Es gibt zwei Möglichkeiten das Threading in Java zu nutzen:
- Erledigen unterschiedlicher Aufgaben parallel
- Bsp: Swing: Oberfläche neu zeichen, Eingaben abarbeiten, eigentliche Programmaufgaben ausführen
- Paralleles Abarbeiten der gleichen Aufgabe
- Bsp: Differentialgleichungen berechnen, Such & Sortieralgorithmen, Bearbeitung von Massendaten (Batch).
Das Fork & Join Framework erleichert das parallele Programmieren durch eine Optimierung der Parallelität und komfortable Klassen.
Im Rahmen der Vorlesung werden wir die Möglichkeiten einer Parallelisierung ohne und mit Rückgaben diskutieren. Die Unterschiede zum Einsatz der einfachen Threadingkonstrukte und der des Frameworks sind im Diagramm unten dargestellt:
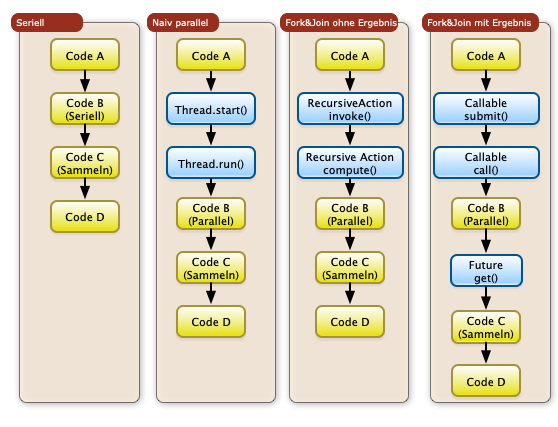
Steuerung des Grads der Parallelisieren
Java erlaubt es recht einfach viele Ausführungseinheiten (Threads) zu erzeugen. Das Betriebssystem wird diese Threads auf Hardwarethreads zuordnen. Das macht das Betriebssystem auch fast immer sehr gut. Erzeugt man aber zufiele ausführbare Threads kann der Rechner überlastet werden und ist kaum noch ansprechbar. Das bedeutet, dass Prozesse die mit dem Benutzer interagieren sollen nicht mehr unbedingt die CPU Zeit bekommen die sie benötigen.
Hat man viel, zu viele Softwarethreads und Prozesse wird das Betriebsystem auch noch ineffizient. Es muss die ganzen Zustandänderungen managen. Hier gibt es kritische Pfade und im Überlastungsfall zuwenig CPU-Zeit.
Das Fork & Join Framework erleichtert das professionelle Skalieren in dem es eine Threadpool anlegt und alle Tasks an freie Prozessoren im Threadpool vergibt. Hiermit übernimmt es eine Aufgaben des Betriebsystem und vermeidet eine Überlastung. Gibt man keinen Wert für den Pool an, wird die Anzahl aller Prozessoren im Rechner als Defaultwert verwendet.
Dies ist nur ein kleiner Ausschnitt aus dem Fork & Join Framwork. Wir betrachten hierzu die folgenden Klassen:
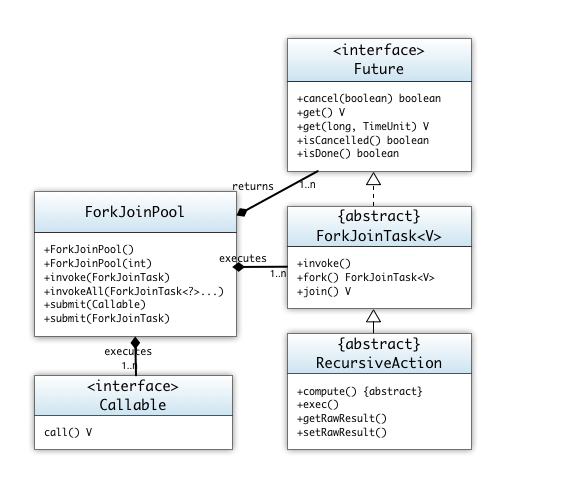
Die Klasse ForkJoinPool
Die Klasse java.util.concurrent.ForkJoinPool wurde im JDK 7 eingeführt.
In dieser Klasse werden eine Menge von Threads verwaltet und zur Ausführung von Task (Aufgaben) verwendet. Dies macht es dem Betriebsystem leichter die Threads auf die Prozessoren zu verteilen, da nicht beliebig viele Threads von Java erzeugt werden. Die Klasse ForkJoinPool verwaltet die Zuordnung der Task auf die konfigurierten (Software)threads.
Tasks können auf 3 Arten dem Framework übergeben werden:
| Aufrufe von ausserhalb | Aufruf innerhalb einer Berechnung | |
|---|---|---|
| asynchrone Ausführung | ForkJoinPool.execute(ForkJoinTask) | ForkJoinTask.fork() |
| warte auf Ergebnis | ForkJoinPool.invoke(ForkJoinTask) | ForkJoinTask.invoke() |
| asynchrone Ausführung mit Ergebnis | ForkJoinPool.submit(ForkJoinTask) ForkJoinPool.submit(Callable) |
ForkJoinTask.fork(ForkJoinTasks sind Futures) |
Die Implementierung wird zu einer RejectedExecutionException Ausnhame führen falls der Threadpool runtergefahren wird oder falls es keine Threads mehr in der VM gibt.
Interessante Konstruktoren:
- public ForkJoinPool(): default Konstruktor, erzeugt einen Pool mit so vielen Threads wie der Rechner Hyperthreads besitzt
- public ForkJoinPool(int parallelism): erzeugt einen Pool mit einer definierten Anzahl Threads
Paralleles Abarbeiten ohne Rückgabewerte
Ein Beispiel hierfür ist der Quicksort. Man kann parallel das linke und das rechte Teilintervall sortieren nachdem die Vorarbeit (seriell) erledigt wurde.
Hierzu nutzt man die abstrakte Klasse RecursiveAction die aus der abstrakten Klasse ForkJoinTask spezialisiert wird. Die Klasse ForkJoinPool kann Tasks die die Bedingungen der Klasse ForkJoinTask erfüllen, parallel ausführen. Hierzu gibt es in der Klasse die Methoden:
- invoke(): startet den Task in dem man sich gerade befindet
- invokeAll(ForkJoinTask<?> ... tasks): startet eine Liste von Tasks (wird im Quicksort verwendet)
Es verbleibt das Problem, dass man einen bestimmten Code ausführen möchte. Hierzu dient die abstrakte Klasse RecursiveAction. Sie besitzt eine abstrakte Methode:
- compute(): führt den Code aus. Diese Methode ist abstrakt!
 |
Wie implementiert man so etwas?
|
Paralleles Abarbeiten mit Rückgabewerte
Die Aufgabe parallelisieren und als Aufgabe starten reicht oft nicht. Oft müssen die Ergebnisse entgegen genommen werden und dann rekursiv zu neuen Ergebnissen aggregiert werden.
Hierzu benötigt man einen Mechanismus der
- die Eingabeparameter für jede Aufgabe (Task) entgegennimmt
- die Aufgaben (Tasks) ausführt
- und die Ergebnisse erst zurückgibt wenn die Ergebnisse vorliegen
Die Schnittstelle Callable
Die Schnittstelle java.util.concurrent.Callable muss implementiert werden um die Ausgabeparameter einer Aufgabe (Task) entgegenzunehmen. Hierfür muss man
- einen generischen Typen wählen der das Ergebnis zur Verfügung stellt
- einen Konstruktor implementieren der alle Eingabeparameter entgegen nimmt.
- alle Parameter als Attribute implementiert
- die Methode V call() die das Ergebnis zurückliefert
Ein Beispiel auf der Programmierübung Ariadnefaden
public class SearchCallable implements Callable<List<Position>> {
Position von;
Position nach;
Ariadne4Parallel a;
/**
*
* @param a Instanz von Ariadne
* @param von Start
* @param nach Ziel
*/
SearchCallable(Ariadne4Parallel a,Position von, Position nach) {
this.a =a;
this.von = von;
this.nach = nach;
}
/**
* Führe Task in eigenem Thread aus und nutze Instanzvariablen
* als Parameter um Aufgabe auszuführen.
* @throws java.lang.Exception
*/
@Override
public List<Position> call() throws Exception {
return a.suche(von, nach);
}
}In diesem Beispiel ist das Ergebnis eine Liste von Positionen die den Web aus dem Labyrinth weisen.
Die Eingabeparameter sind ein Labyrinth, die Startposition und die Position mit dem Ausgang ais dem Labyrinth.
Die Schnittstelle Future
Die Schnittstelle Future erlaubt es das Ergebnis einer Aufgabe zu analysieren. Die Schnittstelle ist generisch und erlaubt es daher nur einen bestimmten Type einer Klasse auszulesen.
Die beiden wichtigsten Methoden der Schnittstelle sind:
- V get(): wartet falls notwendig auf das Beenden der Aufgabe und liefert das Ergebnis ab
- V get(long timeout, TimeUnit unit): wartet eine bestimmte Zeit auf auf ein bestimmtes Ergebnis
In der Schnittstellendefinition sind noch weitere Methoden zum Kontrollieren und Beenden von Aufgaben (Tasks) vorhanden.
Abschicken von Aufgaben (Tasks)
Die Klasse java.util.concurrent.ForkJoinPool verfügt über eine Methode
- public <T> ForkJoinTask<T> submit(Callable<T> task)
Diese Methode nimmt die Eingaben für die Aufgabe (Task) an solange es eine Spezialierung der Klasse Callable<T> ist. Das Ergebnis ist ein Objekt vom Typ ForkJoinTask. Die Klasse ForkJoinTask implementiert die Schnittstelle Future. Das Ergebnis der Aufgabe (Task) wird hier abgeliefert sobald die Aufgabe abgearbeitet ist.
|
Wie implementiert man so etwas?
|
- Printer-friendly version
- Log in to post comments
- 1946 views