Skript: Fortgeschrittene Programmierung, Algorithmen und Datenstrukturen
Skript: Fortgeschrittene Programmierung, Algorithmen und DatenstrukturenModulbeschreibung International Management for Business and Information Technology
- Studiengang: International Business Information Technology Mannheim (Bachelor Wirtschaftsinformatik)
- 2. Semester
- 5 ECTS Punkte Arbeitsleistung: 60h Präsenzzeit, 90h Selbststudium
Kompetenzziele
Die Studierenden kennen die Grundprinzipien der Programmierung und Objektorientierung und können diese in einer adäquaten Programmiersprache anwenden.
Sie sind in der Lage, einfache Problemstellungen algorithmisch zu formulieren, Algorithmen mit den Sprachelementen der Programmiersprache adäquat umzusetzen und Programme zu implementieren, zu testen und anzuwenden. Die Grundprinzipien der Objektorientierung können an modellhaften Szenarien analysiert und implementiert werden.
Die Studierenden sind in der Lage, eine objektorientierte Programmiersprache anzuwenden und damit auch komplexe Problemstellungen algorithmisch zu behandeln und anwenderfreundlich und effizient umzusetzen. Sie sind in der Lage, Algorithmen in verschiedenen Darstellungsarten zu verstehen und ihre Effizienz bzw. Qualität zu beurteilen, aber auch selbstständig Algorithmen und dazu erforderliche Datenstrukturen zu entwickeln und implementieren. Die Studierenden können angewandte Problemstellungen analysieren und bekannte Algorithmen und Datenstrukturen effizienzorientiert darauf anwenden und falls notwendig an die Problemstellungen anpassen.
Lehrinhalte
Fortgeschrittene Programmierung, Algorithmen und Datenstrukturen
Objektorientierte Programmierung mit
- Vererbung
- Unterklassen
- Polymorphie
- Pakete
- Zugriffsrechte
- abstrakte Klassen
- Interfaces
- Exceptions, Ausnahmebehandlung
- Definition eigener Ausnahmeklassen
- Assertions
- Aufbau graphischer Oberflächen
- Applikationen und Applets
- AWT, Swing Komponenten
- typische Komponenten
- Layout-Manager
- Ereignisbehandlung mit Listener-Interfaces und Adapterklassen
- Optionale Themen
- Parallele Programmierung mit Threads
- Ein- und Ausgabe mit Streams
Algorithmen und Datenstrukturen
- Programmiermethodik bei Iteration und Rekursion
- Beschreibung und Analyse von Algorithmen, Umgang mit elementaren, strukturierten und objektorientierten Datentypen
- Datenstrukturen mit den Grundoperationen für Einfügen, Löschen etc.
- als lineare Listen mit Feldstruktur
- einfach, doppelt verkettete Listen
- Bäume
- Stapel
- Schlangen
- abstrakte Datentypen
- Collections, Iteratoren
- als lineare Listen mit Feldstruktur
- Suchverfahren
- sequentielles Suchen
- binäres Suchen
- Sortierverfahren
- Insertionsort
- Selectionsort
- Bubblesort
- Quicksort
- u.a.
- Optionale Themen
- Parallele bzw. nebenläufige Algorithmen mit
- Threads
- Synchronisationskonzepten
- Parallele bzw. nebenläufige Algorithmen mit
Online Skript
- 26159 views
Referenzen
Referenzen- Java-Grundkurs für Wirtschaftsinformatiker
- Klaus-Georg Deck,
- Herbert Neuendorf
- ISBN:978-3-8348-1222-3
- Broschiert, 456 Seiten
- Zweite Auflage 26. März 2010
- URL Amazon
- Java als erste Programmiersprache: Vom Einsteiger zum Profi
- Cornelia Heinisch, Frank Müller-Hofmann, Joachim Goll
- ISBN: 978-3-8351-0147-0
- 1200 Seiten
- 5.te Auflage 2007 URL Amazon
- 6.te Auflage 2010 URL Amazon
- UML 2 Das umfassende Handbuch
- Christoph Kecher
- ISBN: 978-3-8362-1419-3
- 424 Seiten
- Dritte Auflage 2009
- URL Amazon
- Algorithmen und Datenstrukturen
- T.Ottmann, P.Widmayer
- ISBN: 3-8274-1029-0
- 716 Seiten
- Vierte Auflage 2002
- 5.te Auflage (ab Sept. 2011) URL Amazon
- Java Klassen API
- 9052 views
Ablauf der Vorlesung
Ablauf der VorlesungZeitliche Aufteilung der Themen auf die Vorlesungsblöcke. Das thematisch organisierte Inhaltsverzeichnis des Skripts ist hier zufinden.
1. Suchen und Sortieren
- Kompexitätsbetrachtungen
- Suchen
- Einführung in Sortieren
- Sortieralgorithmen
- Gruppenarbeit: Sortieralgorithmen
2. Listen, Stapel (Stack), Warteschlangen
- Vorstellung der Sortieralgorithmen
- Listen
- Stapel (Stack)
- Warteschlangen (Queues)
3. Bäume
- Binärbäume
- Übungen:
- Einfügen in Binärbaum,
- Bestimmen der Tiefe eines Baumes
- Optional: Entfernen aus dem Baum
- Übungen:
- AVL Bäume, Bruderbäume
4. Generische Klassen
- Generische Klassen
5. Collections, Iteratoren
- Java Collections Framework
- Iteratoren
- Übungen (Map, Set)
6. Swing
- Swing
- Innere Klasse, anonyme Klassen
- Wiederholung innerer und anonymer Klassen
- Übungen zu inneren und anonymen Klassen
7. Backtrack Übung
- Wiederholung Swing
- Ariadnefaden Programmierübung
8. Streams
- IO mit Java
- Ariadnefaden Programmierübung
9. Backtracking, Teile und Herrsche
- Ariadnefaden Programmierübung
- Stufe 4: Wo geht es hier bitte raus?
10. Nebenläufiges Programmieren
- Threading
- Fork & Join Framework
- Letzter Abschnitt: Backtracking, paralleler Ansatz
- Wiederholung
- 9871 views
Programmieren
ProgrammierenDieser Abschnitt behandelt fortgeschrittene Javakonzepte:
- 10529 views
Oberflächenprogrammierung mit Swing
Oberflächenprogrammierung mit SwingGrafische Benutzeroberflächen in Java
- GUI: englische Abkürzung für "Graphical User Interface" oft auch mit UI (User Interface) abgekürzt
- Ziel graphischer Benutzeroberflächen:
- Intuitiv bedienbare Benutzerschnittstellen für ungeübte Benutzer
- Optionen zu effizienten Benutzung von erfahrenen Benutzern (Kommandos auf Befehlstasten, Tabulatoren zum Bewegen zwischen Eingabefeldern etc.)
- Vorteil von Java-GUIs
- Plattformunabhängigkeit (write once, run anywhere)
- 7611 views
Entwicklungsgeschichte der grafischen Benutzerschnittstellen in Java (JRE)
Entwicklungsgeschichte der grafischen Benutzerschnittstellen in Java (JRE)Swing ist das Ergebnis einer Evolution der grafischen Benutzerschnittstellen die seit 1996 immer weiterentwickelt wurden. Der geschichtliche Überblick ist hilfreich beim Verstehen der recht komplexen Paketstrukturen von Swing und AWT.
Java 1.0: Another Windowing Toolkit (AWT)
- Jahr 1996
- Paket: java.awt.*
Die ursprüngliche Grafikbibliothek AWT sollte die folgenden Anforderungen erfüllen
- einfach zu verstehen und zu Programmieren ("Volks GUI")
- weniger komplex als das damals populäre X11, Motif von Unix-Workstations
- unabhängig von Windows (Rechte, Lizensen!)
- Kleine Teilmenge der wichtigsten GUI Elemente
- geplanter Einsatz Browser-Applets und TV-Settop Boxen (Auf Neudeutsch "Kabeltuner")
- Internet Browser zu mehr Interaktion und mehr Intelligenz zu verhelfen
- leicht auf unterschiedlichen Betriebssytemen zu implementieren
AWT hat daher die folgenden Eigenschaften
- nur wenige GUI Komponenten
- HeavyWeight Implementierung (direkte Abbildung auf Betriebssystemkomponenten)
- Threadsicher
- keine Model-View-Controller Architektur
Java 1.1: AWT + Java Foundation Classes (JFC)
- Jahr 1997
- Paket: javax.swing.*
Das AWT musste um eine objektorientierte Ereignissteuerung erweitert werden da das Implementieren von GUIs mit vielen Komponenten sehr unübersichtich war
Gleichzeitig wurde ein vollkommenes Neudesign mit einem optionalen Package (javax Pakete) mit dem Projektnamen Swing (engl. Schaukel) vorgestellt. Der offizielle Name war "Java Foundation Classes".
Da JFC zum Zugriff auf die Betriebssytemkomponenten AWT benutzen muss, ist es von AWT abhängig. JFC ist eine "light weight" Implementierung und daher stärker vom gegebenen Betriebssytemen entkoppelt.
|
|
Java 1.2: JFC/Swing Standard GUI
JFC (Swing) muss nicht mehr separat geladen werden und ist Bestandteil des Standard JREs. Es verdrängt AWT mehr und mehr. Seine wichtigsten Eigenschaften sind
Swing wurde seit JRE 1.2 kontinuierlich weiterentwickelt und erhielt in jeder neuen JRE Version zusätzliche Eigenschaften. Die Demoanwendung SwingSet2 ist eine gute Referenzanwendung in der sehr viele Komponenten verwendet werden. |

"Lightweight" versus "Heavyweight" Implementierungen
Man spricht von Heavyweight Komponenten wenn zu ihrer Implementierung die vom Betriebssytem zu Verfügung gestellten Komponenten verwendet werden.
In einer Heavyweight Implementierung wird z.Bsp. zur Anzeige einer Menüauswahliste direkt die Menüauswahlliste des Betriebssytem verwendet.
Man spricht von einer Lightweight Implementierung wenn eine Grafikbibliothek vom Betriebsystem nur einen Pixelbereich auf dem Bildschirm nutzt und dann die Komponenten selbst zeichnet (rendered). Bei einer Lightweigtimplemenierung muss die Anwendung zum Beispiel eine Menüauswahlliste selbst auf dem Bildschirm zeichnen und selbst darauf achten, welche Bereiche des Fenster überschrieben werden.
| Vorteile | Nachteile | |
|---|---|---|
| Heavyweight |
|
|
| Lightweight |
|
|
Anmerkung: Die historischen (vor 2005) Probleme von Swing sind in den aktuellen Javaversion nicht mehr vorhanden. Moderne Garbage-Kollektoren blockieren die Benutzerschnittstellen nicht mehr sichtbar. Die aktuelle 2D Bibliothek von Java zeichnet in der Regel ausreichend schnell und benutzt auf den gängigen Plattformen (Windows, Mac, Linux) die Betriebssystemoptimierungen für Fonts, 2D- und 3D-Operationen. JavaFX stellt auch die nötigen hardwareunterstützten Operationen für Bildtransformationen und Filme zur Verfügung.
- 6226 views
Implementieren von einfachen Swingkomponenten
Implementieren von einfachen SwingkomponentenSwing-Komponenten
Eine sehr anschauliche Übersicht über die existierenden Swing-Komponenten kann man auf der Seite des MIT finden. Hier gibt es auch Beispielcode. Bei Oracle kann man auch ein Tutorial mit Beispielcode finden.
| Komponente (In Java Swing) |
|---|
| Komponenten sind grafische Bereiche die mit dem Benutzer interagieren können. |
Toplevel Container
Swing verfügt über drei "Top-level-Container" in denen Benutzeroberflächen implementiert werden können:
- JFrame: reguläre freistehende Programmfenster mit (optionaler) Menüleiste
- JDialog: Eine Dialog-Box für modale Dialoge wie z.Bsp. Fehlermeldungen
- JWindow: Ein freistehendes Fenster ohne Menüleisten, ohne Buttons zur Verwaltung des Fensters
| Container (In Java Swing) |
|---|
| Ein Container ist eine Komponente die andere AWT Kompomenten enthalten kann. |
Fenster: Klasse JFrame
Fenster können mit der Klasse JFrame erzeugt werden. Das folgende Beispielprogramm erzeugt ein einfaches Fenster der Größe 300 Pixel x 100 Pixel mit einem Titel in der Kopfleiste:
package s2.swing;
import javax.swing.JFrame;
public class JFrameTest {
public static void main(String[] args) {
JFrame myFrame = new JFrame("Einfaches Fenster");
myFrame.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE); //Beende Anwendung bei Schließen des Fensters
myFrame.setSize(300,100); // Fenstergroesse 300x100 Pixel
myFrame.setVisible(true); // Mache Fenster sichtbar
}
}
Erzeugt das folgende Fenster (MacOS):
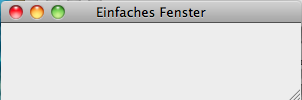
Die Klasse JFrame erbt die Eigenschaften von Component, Container, Window und Frame aus dem AWT Paket:
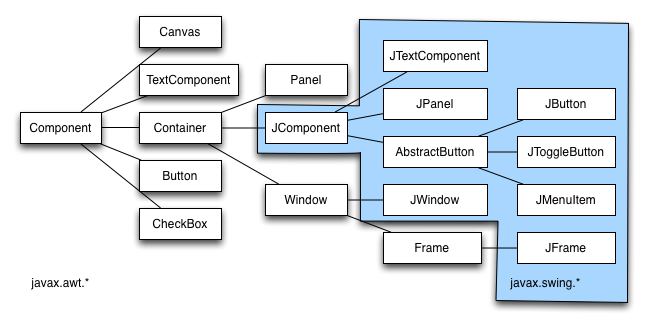
Die vollständge Beschreibung findet man in der Java API Dokumentation.
Ein JFrame besteht aus mehreren Ebenen in denen unterschiedliche grafische Objekt positioniert sind:
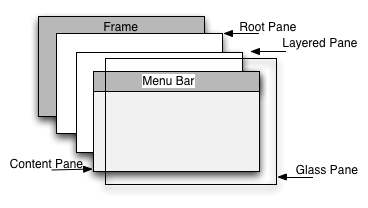
Die Verwendung der unterschiedlichen Ebenen ist ein fortgeschrittenes Thema und wird im Rahmen des Kurses nicht behandelt. Es ist jedoch wichtig zu wissen, dass diese verschiedenen Ebenen existieren. Das Glass ane erlaubt beispielsweise eine unsichtbare Struktur über das GUI zu legen und damit zum Beispiel Mausereignisse abzufangen. Mehr Informationen sind z. Bsp. in der Oracle Dokumentation zu finden.
Buttons: Die Klasse JButton
Buttons können leicht mit der Klasse JButton erzeugt werden. Sie können mit der add() Methode dem Fenster hinzugefügt werden da das JFrame als Container in der Lage ist Komponenten aufzunehmen.
Beispiel: JButton in einem JFrame
package s2.swing;
import javax.swing.JButton;
import javax.swing.JFrame;
public class JFrameButtonTest {
public static void main(String[] args) {
JFrame myFrame = new JFrame("Einfaches Fenster");
myFrame.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
myFrame.add(new JButton("Click mich ich bin ein JButton!"));
myFrame.setSize(300,100);
myFrame.setVisible(true);
}
}Ergibt das folgende Fenster:
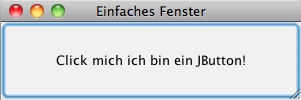
Swing bietet eine Reihe von Varianten von Buttons an auch in Menüleisten verwendet werden können. Die entsprechenden Klassen werden von der Klasse AbstractButton abgeleitet:
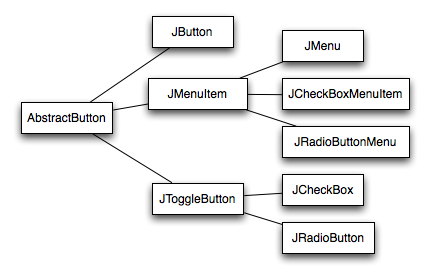
Textfelder: Klasse JTextComponent und JTextField
Swing erlaubt die Verwaltung von Eingabetextfeldern durch die Klasse JTextField. Die Klasse JTextField ist die einfachste Möglichkeit Text auszugeben und einzugeben wie im folgenden Beispiel zu sehen ist.
Beispiel: JTextfield in JFrame
package s2.swing;
import javax.swing.JFrame;
import javax.swing.JTextField;
public class TextfeldTest {
public static void main(String[] args) {
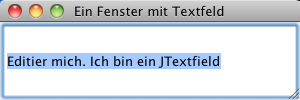
JFrame frame = new JFrame("Ein Fenster mit Textfeld");
frame.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
frame.add(new JTextField("Editier mich. Ich bin ein JTexfield", 60));
frame.setSize(300, 100);
frame.setVisible(true);
}
}
Das Programm erzeugt bei der Ausführung das folgende Fenster:
Beispiel: JTextField in einem Applet/Hauptprogramm
Swing bietet eine ganze Reihe von Möglichkeiten mit Texten umzugehen wie sich aus der Klassenhierarchie von JTtextComponent ergibt:
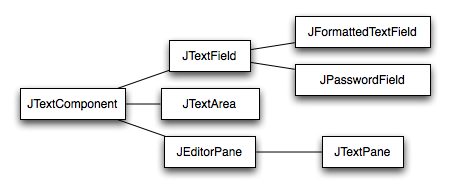
Beschriftungen: Klasse JLabel
Einfache, feste Texte für Beschriftungen werden in Swing mit der Klasse JLabel implementiert:
package s2.swing;
import javax.swing.JFrame;
import javax.swing.JLabel;
/**
*
* @author s@scalingbits.com
*/
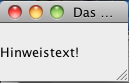
public class JLabelTest {
public static void main(String[] args) {
JFrame f = new JFrame("Das Fenster zur Welt!");
f.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
f.add(new JLabel("Hinweistext!"));
f.setSize(100, 80);
f.setVisible(true);
}
}
Das Programm erzeugt bei der Ausführung das folgende Fenster:
Container, Behälter für andere Komponenten: Klasse JPanel
Zum Anordnen und Positionieren von Komponenten wird die Klasse JPanel verwendet. Sie ist ein Behälter der andere Komponenten aus der JComponent-Hierarchie verwalten kann. Dies sind z.Bsp.:
- andere JPanels
- JButton
- JTextField
- JLabel etc.
JPanels haben zwei weitere wichtige Eigenschaften
- sie können nur ihren eigenen Hintergrund zeichnen
- sie benutzen Layoutmanager um die Positionierung der JComponenten durchzuführen
Jede Instanz eines JPanels hat einen eigenen Layoutmanager. Da typischerweise ein Layoutmanager nicht ausreicht, werden JPanels und deren Layoutmanager geschachtelt.
Beispiel: JTextfield in JFrame
import javax.swing.JFrame;
import javax.swing.JTextField;
/**
*
* @author s@scalingbits.com
*/
public class TextfeldTest {
public static void main(String[] args) {
JFrame frame = new JFrame("Ein Fenster mit Textfeld");
frame.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
frame.add(new JTextField("Editier mich. Ich bin ein JTextfield", 60));
frame.setSize(300, 100);
frame.setVisible(true);
}
}
Das Programm erzeugt bei der Ausführung das folgende Fenster:
Beispiel: JTextField in einem Applet
| Quellcode |
|---|
package s2.swing; import java.awt.BorderLayout; /** public JPanelJApplet() { JButton myButton = new JButton("Click mich"); JLabel myLabel = new JLabel("Ich bin ein JLabel"); JPanel myPanel = new JPanel(); Container myPane = getContentPane(); @Override |
- 8890 views
Top Level Container
Moin Moin,
in ihrem Skript steht etwas von "3 Top-Level Container", aufgezählt sind aber 4.
Also wie viele sind es?
Anmerkung: Hinter "JApplet" steht ein Semikolon und kein Doppelpunkt. Und es fehlt ein "p" bei pain, bei "JFrame" ganz am Ende im letzten Absatz.
Gruß
- Log in to post comments
Gut beobachtet
Applets werden von keinen gängigen Browsern aus Sicherheitsgründen mehr unterstützt. Da man mit Applet nichts mehr machen kann bleiben noch drei. Habe das Skript angepasst.
- Log in to post comments
Layoutmanager
LayoutmanagerLayoutmanager erlauben die Anordnung von Komponenten in einem Container. Abhängig vom gewählten Manager werden die Komponenten in ihrer gewünschten oder in einer gestreckten, bzw. gestauchten Form angezeigt. Die Feinheiten der Layout-Manager werden hier nicht behandelt. Es werden auch nur die wichtigsten Layout-Manager vorgestellt. Die Swingdokumentation ist für die Entwicklung von GUIs unerlässlich.
| Definition: Layout-Manager |
|---|
| Ein Layout-Manager ist ein Objekt, welches Methoden bereitstellt, um die grafische Repräsentation verschiedener Komponenten innerhalb eines Container-Objektes anzuordnen |
Wichtig: Eine absolute Positionierung von Komponenten ist ungünstig, da Fenster eine unterschiedliche Größe haben können.
Java biete eine Reihe von Layout-Managern. Im Folgenden wird eine Auswahl vorgestellt:
Flowlayout
Das FlowLayout ist das einfachste und Standardlayout. Es wird benutzt wenn kein anderer Layoutmanager angeben wird. In ihm werden die Komponenten in der Reihenfolge des Einfügens von links nach rechts eingefügt.
Strategie: Alle Komponenten werden in einer Reihe wie in einem Fließtext angeordnet. Reicht die gegebene Breite nicht erfolgt ein Umbruch mit einer neuen Zeile.
Dem JPanel jp wird im Folgenden kein expliziter LayoutManager mitgegeben um die 6 Knöpfe zu verwalten es wird der FlowLayoutmanager als Standardeinstellung verwendet:
package s2.swing;
import javax.swing.JButton;
import javax.swing.JFrame;
import javax.swing.JPanel;
/**
* Zeigt einen sehr einfachen FlowlayoutManager mit 5 Buttons
* @author s@scalingbits.com
*/
public class FlowlayoutTest {
/**
* Hauptmethode
* @param args Es werden keine Parameter ausgewertet
*/
public static void main(String[] args) {
JFrame f = new JFrame("FlowLayout");
JPanel jp = new JPanel();
for (char c = 0; c <= 5; ++c) { // Stecke 6 Buttons in das Panel
jp.add(new JButton("Button " + (char)('A'+c)));
}
f.add(jp); // Füge Panel zu Frame
//Beende Anwendung beim Schliesen des Fensters
f.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
f.pack(); // Berechne Layout
f.setVisible(true);// Zeige alles an
}
}
Ergibt ein Fenster mit dem folgenden Layout:

| Bei mangelndem horizontalem Platz wird ein automatischer Umbruch in eine neue Zeile durchgeführt (siehe rechts). |  |
Eigenschaften Flowlayout
- Komponenten behalten ihre Wunschgröße
- Zeilenumbruch bei mangelndem horizontalen Platz
- aus den beiden ersten Eigenschaften ergibt sich, dass Komponenten eventuell nur teilweise angezeigt werden oder völlig verdeckt sein können!
Borderlayout
Der Borderlayoutmanager erlaubt das Gruppieren von Komponenten abhängig von der Richtung im Panel.
Strategie: Die zur Verfügung stehende Fläche wird in fünf Bereiche nach den Himmelsrichtungen aufgeteilt
- NORTH (Oben)
- SOUTH (Unten)
- EAST (Rechts)
- WEST (Links)
- CENTER (Mitte)
Der Centerbereich ist der priorisierte Bereich.
Das BorderLayout ist die Standardeinstellung für die Klassen Window und JFrame.
Im nächsten Beispiel wir je ein Knopf (Button) in einem der Bereiche angelegt:
}
Zur Bestimmung der Position werden Konstanten mit den englischen Namen der Himmelsrichtung verwendet (Bsp. BorderLayout.NORTH). Beim Borderlayout ist zu beachten, dass Komponenten die oben, bzw. unten angeordnet werden über die ganze Breite des Containers gezeichnet werden. Komponenten die links und rechts angeordnet werden sind jedoch immer unter, bzw. über den Komponenten die oben und unten angelegt urden.
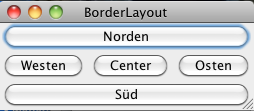
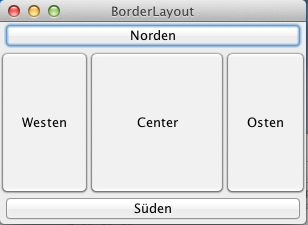
Eigenschaften BorderlayoutSiehe Fenster rechts mit größerem Fensterbereich:
|
 |
BoxLayout
Das BoxLayout erlaubt das Anordnen von Komponenten in Zeilen oder Spalten. Durch das Verschachteln von BoxLayoutmanagern kann man ähnliche Effekte wie beim GridLayout erzielen. Man hat jedoch die Möglichkeit einzelne Zeilen oder Spalten individuell zu konfigurieren.
Das BoxLayout versucht alle Komponenten mit ihrer bevorzugten Breite bei der horizontalen Darstellung zu positionieren. Die Höhe aller Komponenten wird hier versucht auf Die Wunschhöhe der höchsten Komponente wird benutzt um die Gesamthöhe zubestimmen.
Bei der vertikalen Darstellung wird entsprechend versucht die bevorzugte Höhe zu verwenden. Bei der vertikalen Darstellung versucht der Layoutmanager alle Komponenten horizontal so weit wie die breiteste Komponente zu strecken.
Komponenten können aneinander
- Linksbündig
- Rechtsbündig
- Zentriert
ausgerichtet werden
Das folgende Beispiel zeigt ein horizontales Boxlayout welches nach 2 Sekunden automatisch die Orientierung zu vertikal und dann wieder zurück triggert:
package s2.swing;
import javax.swing.BoxLayout;
import javax.swing.JButton;
import javax.swing.JFrame;
import javax.swing.JPanel;
import javax.swing.JTextArea;
public class BoxLayoutTest {
public static void main(String[] args) {
int wartezeit = 2000; // in Millisekunden
JFrame f = new JFrame("BoxLayout");
JPanel jp = new JPanel();
// Erzeuge ein horizontales und ein vertikales BoxLayout
BoxLayout horizontal = new BoxLayout(jp, BoxLayout.X_AXIS);
BoxLayout vertikal = new BoxLayout(jp, BoxLayout.Y_AXIS);
jp.setLayout(horizontal);
for (char c = 0; c < 4; ++c) {
f.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
f.pack();
f.setVisible(true); // Warte 2 Sekunden try { Thread.sleep(wartezeit); // Wechsle fünfmal die Orientierung alle zwei Sekunden for (int i = 0; i < 5; i++) { jp.setLayout(vertikal); f.setTitle("BoxLayout - Vertikal"); f.pack(); Thread.sleep(wartezeit); jp.setLayout(horizontal); f.setTitle("BoxLayout - Horizontal"); f.pack(); Thread.sleep(wartezeit); } } catch (InterruptedException e) { // Mache nichts im Fall einer Ausnahme } } }
Ein horizontales Layout wird mit der Konstanten BoxLayout.X_AXIS beim Konfigurieren des Layoutmanagers erzeugt:

Ein vertikales Layout wird beim Erzeugen des Layoutmanagers mit Hilfe der Konstanten BoxLayout.Y_AXIS konfiguriert:
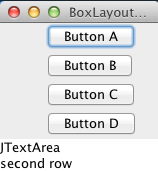
Eigenschaften Boxlayout
- Jede Komponente wird in ihrer Wunschgröße dargestellt
- Die Größe des Containers ergibt sich aus der größten Wunschhöhe und der größten Wunschbreite
Hinweis: Die zweizeilige JTextArea im Beispiel oben hat eine andere Wunschgröße als die Knöpfe
GridLayout
Der GridLayoutmanager erlaubt die Anordnung von Komponenten in einem rechteckigen Raster (Grid: engl. Raster, Gitter). Der Gridlayoutmanager versucht die Komponenten von links nach rechts und von oben nach unten in das Raster einzufügen.
Strategie: Alle Zellen haben eine einheitliche Größe
Wird für die Größe der Zeilen oder Spalten eine 0 angegeben erlaubt dies das Anlegen beliebig vieler Element in den Spalten oder Zeilen.
|
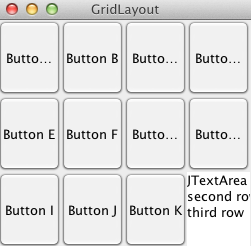
Im folgenden Beispiel werden 11 Buttons und ein Textfeld in drei Reihen und vier Spalten angeordnet: package s2.swing;
import java.awt.GridLayout;
import javax.swing.JButton;
import javax.swing.JFrame;
import javax.swing.JPanel;
import javax.swing.JTextArea;
public class GridLayoutTest {
public static void main(String[] args) {
JFrame f = new JFrame("GridLayout");
JPanel jp = new JPanel();
jp.setLayout(new GridLayout(3,4));
for (char c = 0; c < 11; ++c) {
jp.add(new JButton("Button " + (char)('A'+c)));
}
JTextArea jta =new JTextArea(3,10);
jta.append("JTextArea \nsecond row\nthird row");
jp.add(jta);
f.add(jp);
f.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
f.pack();
f.setVisible(true);
}
}
|
Dies ergibt das folgende Fenster bei der Ausführung:
|
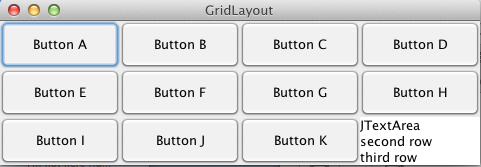
Eigenschaften des Gridlayouts
|
gestauchtes Fenster:
|
- 9082 views
Boxlayout - Schreibfehler
Hallo,
"Das folgende Beispiel zeigt ein vertikales Boxlayout welches nach 2 Sekunden automatisch die Orientierung zu vertikal und zurück triggert:"
-> Müsste sicher "die Orientierung zu HORIZONTAL und zurück triggert heißen ?
und
"Ein horizontales Layout wird mit der Konstanten BoxLayout.Y_AXIS beim Konfigurieren des Layoutmanagers erzeugt:"
-> horizontal müsste BoxLayout.X_AXIS sein, richtig ?
- Log in to post comments
BorderLayoutManager
Hallo,
Der BorderLayoutManager teilt Norden und Süden die gewünschte Breite und nicht die gewünschte Höhe zu, oder sehe ich das falsch?
Vgl. Westen / Osten.
lg
- Log in to post comments
Gute Überlegung
Schauen Sie sich mal das Bild mit den Buttons an:
- Norden und Süden sind gerade groß genug. Sie sind aber breiter als minimal notwendig.
- Osten, Westen, Mitte sind ursprünglich so breit wie sie minimal sein müssen. Zieht man das GUI in die Länge werden sie höher als notwendig.
- Log in to post comments
Rechtschreibfehler
Jede Komponente wird in ihrer Wunschgröße gargestellt???
Eigenschaften von BoxLayout
- Log in to post comments
Ereignisse und deren Behandlung
Ereignisse und deren BehandlungGUI Programme und Ereignisverarbeitung
GUI Programme laufen nicht linear ab. Bei Benutzerinteraktionen muss das Programm in der Lage sein sofort einen bestimmten Code zur Behandlung auszuführen.
Programmaktionen werden durch Benutzeraktionen getriggert. Man spricht hier von einem ereignisgesteuerten Programmablauf.
| Definition: Ereignis |
|---|
|
Ein Ereignis ist ein Vorgang in der Umwelt des Softwaresystems von vernachlässigbarer Dauer, der für das System von Bedeutung ist. |
Im Rahmen dieses Abschnitts sprechen wir von einer wichtigen Gruppe von Ereignissen den Benutzerinteraktionen:
Beispiele sind
- Mausclick
- Tasteneingabe
- Menülistenauswahl
- Zeigen auf einen Bereich des GUI
- Texteingabe oder Veränderung
Der Programmablauf wird aber auch von anderen weniger offensichtlichen Benutzerintreaktionen gesteuert
- Verdecken des Programmfensters durch ein anderes Fenster
- Fenstermodifikationen
- Vergößern, verkleinern
- Bewegen,
- Schließen eines Fenster
- Bewegen der Maus über das Programmfenster ohne Klicken (nicht auf allen Plattformen)
- Erlangen des Fokus auf einem Fenster
Ereignisklassen
Java benutzt Klassen zur Behandlung von Ereignissen (engl. Events) der Java-Benutzeroberflächen. Typische Klassen sind
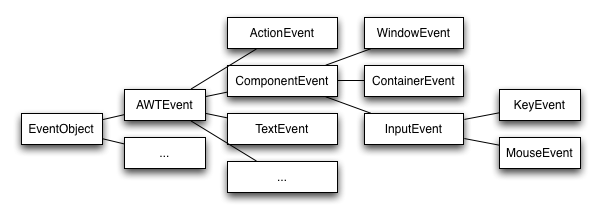
Die Klassen enthalten die Beschreibung von GUI Ereignissen (z.Bsp. Maus wurde auf Position x=17, y=24 geklickt).
Sie korrelieren mit den Klassen die die grafischen Komponenten implementieren: Z.Bsp.
- Window erzeugt einen WindowEvent beim Schließen des Fensters
- JFrame einen WindowEvent beim Schließen des Fensters (JFrame ist ein Window!)
- JButton erzeugt einen ActionEvent beim Betätigen der Schaltfläche
Erzeugen von Ereignissen und deren Auswertung
Ereignisse werden automatisch von den Swingkomponenten erzeugt. Dies ist die Klasse JComponent mit ihren abgeleiteten Klassen. Sie werden zum Beispiel erzeugt, wenn ein Benutzer die Schaltfläche eines JButton betätigt. Die Aufgabe die dem Entwickler verbleibt ist die Registrierung seiner Anwendung für bestimmte GUI-Ereignisse. Die Anwendung kann nur auf Ereignisse reagieren gegen die sich sich vorher registriert hat.
Der Entwickler kann dann nach der Registrierung eines bestimmten Ereignisses ist die Auswertung des Ereignisses vornehmen und auf das Ereignis mit der gewünschten Aktion reagieren.
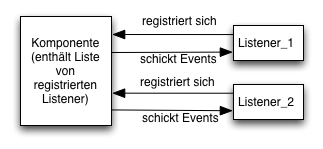
Java verwendet hierzu die Ereignis-Delegation um die Komponente die das Ereignis auslöst von der Ereignisbehandlung zu entkoppeln.
- Der Benutzer betätigt z.Bsp. eine Schaltfläche
- Das Laufzeitsystem erkennt das Ereignis
- Objekte die das Ereignis beobachten (engl. "Listener" in Java) werden aufgerufen und das Ereignis wird behandelt.
- Ein Listener erhält vom Laufzeitsystem ein ActionEvent-Objekt mit allen Informationen die zum Ereignis gehören.
Die Listenerobjekte müssen sich mit Hilfe einer Registrierung bei den GUI Objekten anmelden:
- Komponenten die Ereignisse erzeugen (Klasse JComponent) können, erlauben die Registrierung von "Listener" Objekten (engl. zuhören; nicht nur hören!)
- die Registrierung erfolgt mit Methoden der Syntax addXXXListener(...) der GUI Komponenten
- "Listener" Objekte implementieren das Java Interface ActionListener und damit die Methoden die beim Eintritt eines Ereignisses ausgeführt werden sollen.
Wichtig: Beziehung zwischen Listenerobjekt und GUI Objekt
Ein Listenerobjekt kann sich gegen ein oder mehrere GUI Objekte registrieren
- Registriert man ein Listenerobjekt gegen genau ein GUI Objekt (Bsp. 1 Button <-> 1 Listenerobjekt)
- muß man den Urheber des Ereignisses und den Ereignistyp nicht analysieren. Der Typ des Ereignis und das GUI Objekt sind bekannt
- Registriert man ein Listenerobjekt gegen mehrere GUI Objekte (Bsp. 3 Buttons <-> 1 Listenerobjekt)
- muß man im Listenerobjekt das übergebene Ereignisobjekt auf den Verursacher, das GUI Objekt, untersuchen
- muß man ein Listenerinterface implementieren, dass auch die Ereignisse aller Objekte verarbeiten kann.
- Beispiel: 1 Button und ein Textfeld werden von einem Listenerobjekt verwaltet. Man benötigt hier eine gemeinsame Listener-Oberklasse die beide graphische Objekte verwalten kann
Beispiel
Das folgenden Beispiel ist eine sehr einfache Implementierung eines JFrame mit einem Button und einem ActionListener:
package s2.swing;
import java.awt.event.ActionEvent;
import java.awt.event.ActionListener;
import javax.swing.JButton;
import javax.swing.JFrame;
/**
*
* @author s@scalingbits.com
*/
public class ActionListenerBeispiel implements ActionListener {
@Override
public void actionPerformed(ActionEvent ae) {
//Ausgabe des zum ActionEvent gehörenden Kontexts
System.out.println("Aktion: " + ae.getActionCommand());
}
public static void main(String[] args) {
JFrame myJFrame = new JFrame("Einfacher ActionListener");
myJFrame.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
JButton jb = new JButton("Hier drücken");
ActionListenerBeispiel behandeln = new ActionListenerBeispiel();
jb.addActionListener(behandeln); // Füge Listener zu Button
myJFrame.add(jb); // Füge Button zu Frame
myJFrame.pack();
myJFrame.setVisible(true);
} // Ende main()
} // Ende der KlasseDie Klasse ActionListenerBeispiel implementiert die Methode actionPerformed() nach der Spezifikation eines ActionListener.
Das Programm startet in der main() Methode und erzeugt das folgende GUI:
- Nach klicken des Button "feuert" das Buttonobjekt jb ein Ereignis (Event)
- die Methode actionPerformed() des registrierten Listener behandeln wird mit einem Eventobjekt als Übergabeobjekt aufgerufen
- Das Eventobjekt ae wird analysiert und das
- Kommando wird als Text auf der Konsole ausgegeben:
Aktion: Hier drücken
Der Text "Hier drücken" wird ausgeben, da das Eventobjekt bei Buttons immer den Text des Buttons ausgibt.
Ereignisse (Events)
Es gibt eine reichhaltige Hierarchie von spezialisierten Event- und Listenerklassen. Hierzu sei auf die Java-Tutorials von Oracle verwiesen.
Weitere Events sind zum Beispiel:
- ItemEvent: Z. Bsp. Analysieren von JCheckBox Komponenten
- MouseEvent: Analysieren von Mausposition, Bewegung etc.
- ChangeEvent: Z. Bsp. Analysieren von Änderungen an einem JSlider
Der Swing "Event Dispatch Thread"
Damit Benutzeraktionen unabhängig vom normalen Programmablauf behandelt werden können, benutzt Swing eine eigene Ausführungseinheit, einen Thread, zum Bearbeiten der Benutzeraktionen. Dieser "Thread" ist ein Ausführungspfad der parallel zum normalen Programmablauf im main-Thread abläuft. Threads laufen parallel im gleichen Adressraum des Prozesses und haben daher Zugriff auf die gleichen Daten.
Blockieren des GUIs
Alle Aktionen der ActionListener werden vom "Swing-Event-Dispatch-Thread" ausgeführt. Diese Thread arbeitet GUI Interaktionen ab während das Javaprogramm mit anderen Threads im Hintergrund weiterlaufen kann.
| Wichtig |
|---|
|
Alle Codestrecken von zur Behandlung von Ereignissen (Methode actionPerformed()) werden in nur einem Thread aufgerufen und blockieren alle anderen Behandlungen während sie ausgeführt werden. Im Klartext: Das GUI wird während der Ausführungszeit einer Ereignisbehandlung nicht bedient und ist blockiert. Vermeiden Sie aufwändige (=langlaufende) Implementierungen in den actionPerformed() Methoden! |
Beispiel
Das folgende Programm blockiert das GUI für 2 Sekunden. Die Blockade ist nach dem Klicken an der geänderten Farbe des Buttons zu erkennen. Er bleibt gedrückt:
package s2.swing;
import java.awt.event.ActionEvent;
import java.awt.event.ActionListener;
import javax.swing.JButton;
import javax.swing.JFrame;
/**
*
* @author s@scalingbits.com
*/
public class ActionListenerBlockiert implements ActionListener {
@Override
public void actionPerformed(ActionEvent ae) {
//Ausgabe des zum ActionEvent gehörenden Kontexts
System.out.println("Aktion: " + ae.getActionCommand());
try {// Thread für 2s blockieren (schlafen)
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
JFrame myJFrame = new JFrame("Einfacher ActionListener");
myJFrame.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
JButton jb = new JButton("Hier drücken");
ActionListenerBlockiert behandeln = new ActionListenerBlockiert();
jb.addActionListener(behandeln); // Füge Listener zu Button
myJFrame.add(jb); // Füge Button zu Frame
myJFrame.pack(); // Berechne Layout
myJFrame.setVisible(true);
}
}Synchronisation mit Swing GUIs
 |
|
- 7985 views
Erzeugen von Ereignissen und deren Auswertung
Sollte der zweite Absatz unter der Überschrift eigentlich so formuliert sein?
"Der Entwickler kann dann nach der Registrierung eines bestimmten Ereignisses die Auswertung des Ereignisses vornehmen und auf das Ereignis mit der gewünschten Aktion reagieren."
Und beim ersten Beispiel steht: "Nach klicken des Button "feuert" ..."
Dort ist der Button "Hier klicken" gemeint, oder?
- Log in to post comments
ActionListenerBeispiel
In dem Beispiel:
ActionListenerBeispiel behandeln = new ActionListenerBeispiel();
--> jb.addActionListener(behandeln); // Füge Listener zu Button
myJFrame.add(jb); // Füge Button zu Frame
myJFrame.setVisible(true);
myJFrame.pack();
müsste der Listener der auf jb registriert wird, "ActionListenerBeispiel" heißen oder?
- Log in to post comments
Antwort
Ich bin mir nicht ganz sicher, dass wir über das gleiche sprechen.
Kommunikation über diese Kommentare haben ihre Grenzen.
behandeln ist ein Zeiger auf ein Objekt ActionListenerBeispiel.
Dieses Objekt wird beim dem Objekt jb mit addActionListener registriert.
Das Programm übersetzt und funktioniert auch.
- Log in to post comments
Event-Interface und Event-Adapter
Event-Interface und Event-AdapterDie Implementierung eines einfachen ActionListener-Schnittstelle ist recht einfach, da nur eine Methode implementiert werden muss.
Viele nicht triviale ActionListener erfordern jedoch die Implementierung von mehreren Methoden aufgrund der Komplexität der entsprechenden Komponente. Ein Beispiel hierfür ist die Schnittstelle MouseListener. Sie erfordert die Implementierung der folgenden Methoden:
- mouseClicked(MouseEvent e)
- mouseEntered()
- mouseExited()
- mousePressed()
- mouseReleased()
Dies ist aufwändig wenn man sich nur für ein bestimmtes Ereignis wie z. Bsp. mouseReleased() interessiert. Man muss alle Interfacemethoden implementieren. Vier der Methoden bleiben leer und sind überflüssig.
Listener-Adapter Klassen
Um diese unnötige Schreibarbeit zu vermeiden, stellt Swing nach dem Entwurfsmuster Adapter Klassen als abstrakte Klassen mit leeren, aber schon implementierten Methoden zur Verfügung.
Vorteil: Der Entwickler kann seine Klasse aus der abstrakten Klasse ableiten und muss nur die Methoden für die Ereignisse implementieren die ihn interessieren.
Für die Implementierung von Maus-Events steht zum Beispiel die Klasse MouseAdapter zur Verfügung, die die entsprechenden Methoden implementiert.
Einige der Adapterklassen die Swing zur vereinfachten Implementierung von Ereignisschnittstellen (Event Interface) sind:
| Spezialisierungen der Schnittsteller EventListener | Adapterklasse |
|---|---|
| ComponentListener | ComponentAdapter |
| ContainerListener | ContainerAdapter |
| FocusListener | FocusAdapter |
| KeyListener | KeyAdapter |
| MouseListener | MouseAdapter |
| MouseMotionListener | MouseMotionAdapter |
| WindowListener | WindowAdapter |
Im folgenden Beispiel wird die Klasse MouseAdapterTest aus der abstrakten Klasse MouseAdapter abgeleitet um nur die Methode mouseClicked() implementieren zu müssen:
package s2.swing;
import java.awt.event.MouseAdapter;
import java.awt.event.MouseEvent;
import javax.swing.JButton;
import javax.swing.JFrame;
public class MouseAdapterTest extends MouseAdapter {
public MouseAdapterTest() {
erzeugeGUI();
}
public static void main(String[] args) {
MouseAdapterTest mat = new MouseAdapterTest();
}
private void erzeugeGUI() {
JFrame myJFrame = new JFrame("Mouse Click Adapter Test");
myJFrame.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
JButton jb = new JButton("Hier drücken");
jb.addMouseListener(this);
myJFrame.getContentPane().add(jb);
myJFrame.pack();
myJFrame.setVisible(true);
}
@Override
public void mouseClicked(MouseEvent mEvent) {
System.out.println("MouseClick wurde auf Position ["
+ mEvent.getX() + ","
+ mEvent.getY() + "] "
+ mEvent.getClickCount() + " mal geklickt");
}
} // Ende der KlasseDas Programm registriert sich selbst gegen den Button und ist jetzt in der Lage, die Information des dEventobjekts mEvent auszulesen (x,y Position, Anzahl der Mehrfachclicks).
Beispiel
Im Diagramm (unten) sind die beiden Möglichkeiten aufgeführt die ein Entwickler zum Auslesen eines Mauscklicks benutzen kann. Die von Java zur Verfügung gestellten Infrastruktur besteht aus dem zu implementierenden Interface MouseListener und einer abstrakten Klasse Mouseadapter:
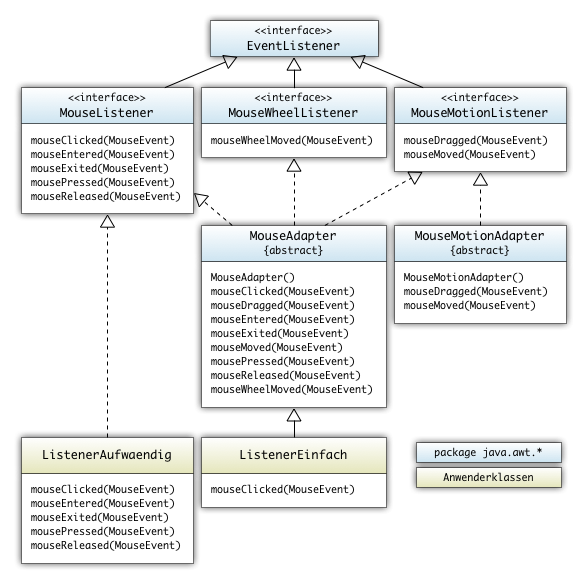
Ein Entwickler der sich nur gegen das MouseClick Ereignis registrieren möchte, kann wie im Diagramm oben:
- das Interface MouseListener in z.Bsp. der Klasse ListenerAufwaendig implementieren. Hier müssen alle 5 Methoden des Interface implementiert werden. Die vier nicht benötigten Methoden können als leere Methoden implementiert werden.
- aus der abstrakten Klasse MouseAdapter eine Klasse wie z.Bsp. ListenerEinfach ableiten. In ihr muss man nur eine einzige Methode mouseClicked() durch Überschreiben implementieren. Die anderen vier Methoden sind schon in der Klasse MouseAdapter als leere Proformamethoden implementiert. Beim Ableiten aus der abstrakten Klasse MouseAdapter müssen nur die gewünschten Methoden überschrieben werden. Ein Konstruktor ist nicht nötig, da die Klasse MouseAdapter einen Default-Konstruktor besitzt.
Anbei die vollständige Implementierung der semantisch gleichwertigen Methoden:
| Klasse ListenerAufwaendig | Klasse ListenerEinfach |
|---|---|
package s2.swing; import java.awt.event.MouseEvent;
import java.awt.event.MouseListener;
public class ListenerAufwaendig implements MouseListener{
@Override public void mouseClicked(MouseEvent mEvent) {
System.out.println("MouseClick wurde auf Position ["
+ mEvent.getX() + ","
+ mEvent.getY() + "] "
+ mEvent.getClickCount() + " mal geklickt");
}
@Override public void mouseEntered(MouseEvent mEvent)
{ /* leere Implementierung, erzwungen */ }
@Override public void mouseExited(MouseEvent mEvent)
{ /* leere Implementierung, erzwungen */ }
@Override public void mousePressed(MouseEvent mEvent)
{ /* leere Implementierung, erzwungen */ }
@Override public void mouseReleased(MouseEvent mEvent)
{ /* leere Implementierung, erzwungen */ }
}
|
package s2.swing;
import java.awt.event.MouseAdapter;
import java.awt.event.MouseEvent;
public class ListenerEinfach extends MouseAdapter{
@Override public void mouseClicked(MouseEvent mEvent) {
System.out.println("MouseClick wurde auf Position ["
+ mEvent.getX() + ","
+ mEvent.getY() + "] "
+ mEvent.getClickCount() + " mal geklickt");
}
}
|
- 6432 views
Anonyme und innere Klassen
Anonyme und innere KlassenNach den bisher vorgestellten Prinzipien erfordert die Implementierung eines GUI die Implementierung von vielen Listenern und führt zur Erzeugung sehr vieler Klassen. Java erlaubt hier die Implementierung von anoymen, inneren Klassen die nur im Kontext einer bestimmten Klasse existieren und den Namensraum der Klassen nicht unnötig belasten.
Innere Klassen
Innere Klassen helfen es zu vermeiden, dass man Klassen veröffentlicht die nur von genau einer anderen Klasse benutzt werden. Innere Klassen werden syntaktisch wie normale Klassen implementiert. Der einzige Unterschied ist, dass sie im Block einer äusseren Klasse implementiert werden. Sie werden in der äusseren Klasse mit dem gleichen Block der äusseren Klasse wie die Klassenvariablen und Methoden der äusseren Klasse implementiert.
Die in der Vorlesung vorgestellten inneren Klassen sind Elementklassen.
| Definition Elementklasse |
|---|
|
Elementklassen sind wie Instanzmethoden und Instanzvariablen Elemente einer (anderen) Klasse. Sie werden auf der gleichen Blockebene wie Instanzmethoden und Instanzvariablen implementiert. Sie haben einen Zugriffschutz wie Instanzmethoden und Instanzvariablen. |
Innere Klassen können auch als lokale Klasse innerhalb eines beliebigen Blocks implementiert werden. Diese Variante ist nicht Gegenstand der Vorlesung.
Die inneren Klassen gehören zum Paket der äusseren Klasse. Importkommandos müssen in der äusseren Klasse implementiert werden.
| Besondere Eigenschaften von Elementklassen |
|---|
Instanzen von Elementklassen sind Komponenten des umgebenden Objekts! |
Das vorhergehende Beispiel kann jetzt wie folgt implementiert werden:
package s2.swing;
import java.awt.event.MouseAdapter;
import java.awt.event.MouseEvent;
import javax.swing.JButton;
import javax.swing.JFrame;
/**
*
* @author s@scalingbits.com
*/
public class MouseAdapterInnereKlasseTest {
/**
* Die innere Klasses MyMouseListener
*/
class MyMouseListener extends MouseAdapter {
@Override
public void mouseClicked(MouseEvent mEvent) {
System.out.println("MouseClick wurde auf Position ["
+ mEvent.getX() + ","
+ mEvent.getY() + "] "
+ mEvent.getClickCount() + " mal geklickt");
}
}
/**
* Erzeuge GUI im Konstruktor
*/
public MouseAdapterInnereKlasseTest() {
JFrame myJFrame = new JFrame("Mouse Click Innere Klasse Test");
myJFrame.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
JButton jb = new JButton("Hier drücken");
jb.addMouseListener(new MyMouseListener());
myJFrame.getContentPane().add(jb);
myJFrame.pack();
myJFrame.setVisible(true);
}
public static void main(String[] args) {
MouseAdapterInnereKlasseTest mat =
new MouseAdapterInnereKlasseTest();
}
}Die Unterschiede sind die Folgenden:
- Die Klasse MouseAdapterInnereKlasseTest muss nicht mehr von der Klasse MouseAdapter abgeleitet werden oder eine Schnitstelle MouseEvent implementieren
- Es wird eine eigene innere Klasse MyMouseListener implementiert die nicht ausserhalb der umgebenden Klasse bekannt ist.
- Die Klasse MyMouseListener erbt (extends Schlüsselwort) von der Klasse MouseAdapter.
- Beim Hinzufügen eines Listeners zum Button wird eine Instanz der inneren Klasse erzeugt.
Diese innere Klasse hat für den Entwickler den Vorteil, dass er keine neuen Klassen nach aussen hin bekanntmachen muss. Die Implementierung des Listeners erfolgt in der gleichen Datei. Die Implementierung des Listener ist also visuell näher als wenn sie in einer eigenen Klasse und einer eigenen Datei geschehen würde.
Objektabhängigkeit von Instanzen innerer Klassen
Im obigen Beispiel wird eine Instanz der Klasse MyMouseListener erzeugt. Dies ist nur erlaubt wenn das Objekt aus dem Kontext (Methode) eines Objekts der Klasse MouseAdapterInnereKlasseTest erzeugt wird. Dieses äussere Objekt existiert, da die innere Klasse im Konstruktor von MouseAdapterInnereKlasseTest erzeugt wird.
Der Code zum Erzeugen des GUI im Konstruktor kann nicht einfach in die statische main() Methode kopiert werden. Hier gibt es noch keinen Kontext zu einem Objekt der Klasse MouseAdapterInnereKlasseTest. Der javac Übersetzer wird einen Fehler melden.
Anonyme, innere Klasse
Für Swing wurde das Konzept der anonymen, inneren Klasse entwickelt.
| Definition anonyme, innere Klasse |
|---|
|
Eine anonyme, innere Klasse ist eine lokale Klasse ohne Namen die innerhalb eines Ausdrucks (Block) definiert und instanziiert wird. |
Anonyme, innere Klassen haben keinen Namen und daher auch keine Konstruktoren. Sie werden typischerweise als Implementierungen für Adapterklassen oder Schnittstellen verwendet.
Beispiel
Anonyme, innere Klassen erlauben die benötigte Listenerimplementierung noch eleganter durchzuführen:
An der Stelle an der eine Instanz eines Listeners benötigt wird kann man auch direkt eine vollständige Klasse implementieren und instanziieren.
Das folgende Beispiel hat die gleiche Funktion wie das vorgehende Beispiel mit der Implementierung einer inneren Klasse. Es kommt aber ohne einen eigenen Klassennamen aus:
package s2.swing;
import java.awt.event.MouseAdapter;
import java.awt.event.MouseEvent;
import javax.swing.JButton;
import javax.swing.JFrame;
public class MouseAdapterAnonymeInnereKlasseTest {
/**
* Erzeuge GUI im Konstruktor
*/
public MouseAdapterAnonymeInnereKlasseTest() {
JFrame myJFrame = new JFrame("Mouse Click Adapter Test");
myJFrame.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
JButton jb = new JButton("Hier drücken");
jb.addMouseListener(new MouseAdapter() {
@Override
public void mouseClicked(MouseEvent mEvent) {
System.out.println("MouseClick wurde auf Position ["
+ mEvent.getX() + ","
+ mEvent.getY() + "] "
+ mEvent.getClickCount() + " mal geklickt");
}
});
myJFrame.getContentPane().add(jb);
myJFrame.pack();
myJFrame.setVisible(true);
}
public static void main(String[] args) {
MouseAdapterAnonymeInnereKlasseTest mat =
new MouseAdapterAnonymeInnereKlasseTest();
}
} |
InteressantEine anonyme, innere Klasse kann...
Wichtig: Es müssen alle Methoden implementiert werden, die notwendig sind um die Klasse zu instanzieren |
Die Unterschiede sind die Folgenden:
- Die Klasse MouseAdapterInnereAnonymeKlasseTest muss nicht mehr von MouseAdapter abgeleitet werden oder einen MouseEvent implementieren
- Beim Hinzufügen eines Listeners zum Button wird
- mit dem new Operator eine Instanz einer anonymen Klasse angelegt, die die abstrakte Klasse MouseAdapter implementiert. Sie ist anonym da sie selbst keinen Namen besitzt.
- die anonyme Klasse wird innerhalb der Klasse MouseAdapterInnereAnonymKlasseTest soweit wie nötig implementiert um aus der abstrakten Oberklasse eine normale Klasse zu erzeugen
Diese "Hilfskonstruktion" hat für den Entwickler eine Reihe von Vorteilen:
- Das Ereignis kann textuell sehr nahe an der Erzeugung der Komponente implementiert werden. Der Code wird übersichtlicher
- Es müssen keine neuen Klassen mit eigenen Namen erzeugt werden. Hierdurch wird die gesamte Klassenhierarchie übersichtlicher und deutlich kleiner.
Statische innere Klassen, nicht anonyme lokale Klassen
... sind nicht Gegenstand dieser Vorlesung.
- 16249 views
1. MouseAdapterInnereKlasseTest
Für das 1. Code Beispiel "MouseAdapterInnereKlasseTest", heißt die Innere Klasse nicht "MyMouseListener" anstatt wie in der Erklärung darunter "MyMouseClicked" beschrieben?
Entschuldigen Sie falls der Fehler schon in der Vorlesung gefunden wurde, ich war heute krank.
MfG
- Log in to post comments
Korrekte Beobachtung
Danke für den Hinweis. Der Text wurde korrigiert. Die beiden Programmierbeispiele wurden um eine Methode entschlackt und sind jetzt kürzer und hoffentlich besser lesbar.
- Log in to post comments
Müsste es dann in der
Müsste es dann in der Erklärung nicht statt:
"Die Klasse MyMouseClicked implementiert das MouseAdapter"
...
"Die Klasse MyMouseListener implementiert das MouseAdapter"
... heißen ?
- Log in to post comments
kleiner Rechtschreibefehler
Hallo Herr Schneider,
mir ist ein kleiner Rechtschreibefehler aufgefallen. Bei den besonderen Eigenschaften von Elementklassen haben sie beim ersten Punkt umschliesen anstatt umschließen geschrieben.
freundliche Grüße
- Log in to post comments
Danke, wurde verbessert.
Danke für die Wertschätzung der deutschen Sprache.
Fehler wird verbessert.
- Log in to post comments
Übungen (Swing)
Übungen (Swing)Ausnahmefenster
Implementieren Sie ein Fenster mit Hilfe der Klasse JFrame zur Behandlung von Ausnahmen.
- Das JFrame soll beim Auftreten einer Ausnahmen aufgerufen werden und den Namen der Ausnahme zeigen.
- Das Programm soll dann auf Wunsch beendet werden oder es soll ein Stacktrace auf der Konsole angezeigt werden
- Das Programm soll ein Bild aus dem Internet als Label verwenden
Das Fenster soll in etwa wie das folgende GUI aussehen:

Verwenden Sie das Rahmenprogramm AusnahmeFenster.java welches eine Infrastruktur zum Testen zur Verfügung stellt:
package s2.swing;
import java.awt.BorderLayout;
import java.awt.Container;
import java.awt.GridLayout;
import java.awt.event.ActionEvent;
import java.awt.event.ActionListener;
import java.net.URL;
import javax.swing.ImageIcon;
import javax.swing.JButton;
import javax.swing.JFrame;
import javax.swing.JLabel;
import javax.swing.JPanel;
import javax.swing.JTextArea;
public class AusnahmeFenster {
final private JFrame hf;
final private JButton okButton;
final private JButton exitButton;
final private Exception myException;
/**
* Aufbau des Fensters zur Ausnahmebehandlung
*
* @param fehlermeldung ein beliebiger Fehlertext der angezeigt wird
* @param e Die Ausnahme die angezeigt werden soll
*/
public AusnahmeFenster(String fehlermeldung, Exception e) {
JLabel logo;
JPanel buttonPanel;
myException = e;
// 1. Erzeugen einer neuen Instanz eines Swingfensters
System.out.println("Hier beginnt die Arbeit: Löschen Sie dieses Kommando");
// ...
hf = null;
// 3. Gewünschte Größe setzen
// 1. Parameter: horizontale Größe in Pixel: 220
// 2. Parameter: vertikale Größe: 230
// ...
// 8. Labelerzeugung
logo = meinLogo();
// 4. Nicht Beenden bei Schliessen des Fenster
// 5. Anlegen der Buttons
okButton = null;
exitButton= null;
// 10. Hinzügen der Eventbehandlung
// Tipp: Die Klasse muss noch das Interface ActionListener implementieren!
// ...
// 6. Aufbau des Panels
// ...
// 7. Aubau des ContentPanes
// ...
// 2.1 Das Layout des JFrame berechnen.
// ...
// 3. Gewünschte Größe setzen
// 1. Parameter: horizontale Größe in Pixel
// 2. Parameter: vertikale Größe
// ...
// 2.2 Sichtbar machen des JFrames. Immer im Vordergrund
// ...
// ...
}
/**
* Implementieren des Logos
* 9.ter Schritt
* @return Zeiger auf das Logoobjekt
*/
private JLabel meinLogo() {
URL logoURL;
JLabel logoLabel;
String myURL = "https://upload.wikimedia.org/wikipedia/commons/0/01/DHBW_MA_Logo.jpg";
try {
logoURL = new URL(myURL);
ImageIcon myImage = new ImageIcon(logoURL);
logoLabel = new JLabel(myImage);
} catch (java.net.MalformedURLException e) {
System.out.println(e);
System.out.println("Logo URL kann nicht aufgelöst werden");
logoLabel = new JLabel("Logo fehlt");
}
return logoLabel;
}
/**
* Behandlung der JButton-Ereignisse
* 11. ter Schritt
* @param e
*/
public void actionPerformed(ActionEvent e) {
//System.exit(0);
//System.out.println("OK Button clicked");
//myException.printStackTrace();
}
/**
* Hauptprogramm zum Testen des Ausnahmefensters
* @throws Exception
*/
public static void main(String[] args) {
AusnahmeFenster dasFenster;
try {
myTestMethod();
} catch (Exception e) {
dasFenster = new AusnahmeFenster("Hier läuft etwas schief", e);
}
}
/**
* Eine Testmethode die mit einer Division durch Null eine
* Ausnahme provoziert
* @throws Exception
*/
public static void myTestMethod() throws Exception {
int a = 5;
int b = 5;
int c = 10;
c = c / (a - b);
System.out.println("Programm regulär beendet");
}
}
Empfehlung: Bauen Sie das GUI schrittweise auf und testen Sie es Schritt für Schritt
- Erzeugen eines einfachen JFrame
- Sichtbarmachen des JFrame
- Größe des JFrames setzen
- Programm nach Schließen des JFrames weiterlaufen lassen
- Anlegen der Buttons
- Aufbau des Panels
- Verbinden von Buttons, Panel und JFrame
- Erzeugen des Labels mit dem GIF und Hinzufügen zum Pane
- Implementieren des Labels mit Logo
- Hinzufügen der ActionListener zu den Buttons
- Implementieren der Aktionen
Taschenrechner
Implementieren Sie einen Taschenrechner mit den vier Grundrechenarten.
Benutzen Sie hierfür die Aufgabenstellung der Universität Bielefeld von Herrn Jan Krüger:
- Aufgabenstellung
- Quellen und Rahmenprogramm: Calculator.tar.gz
Innere Klasse und anonyme Klasse
Das Programm der vorhergehenden Übung (Ausnahmefenster) benutzt in der Musterlösung eine einzige Methode actionPerformed() in der Klasse AusnahmeFenster um die Aktionen der beiden Buttons auszuführen.
public class AusnahmeFensterFertig implements ActionListener {...
public AusnahmeFenster(String fehlermeldung, Exception e) {
...
okButton = new JButton();
exitButton = new JButton();
// 10. Hinzügen der Eventbehandlung
okButton.addActionListener(this);
exitButton.addActionListener(this);
...
}
public void actionPerformed(ActionEvent e) {
JButton source = (JButton) (e.getSource());
if (source == exitButton) {
System.exit(0);
}
if (source == okButton) {
System.out.println("OK Button clicked");
myException.printStackTrace();
}
}
}
Aufgabe 1:
- Implementieren Sie eine externe Klasse SystemExitListener die als Listener für den "Beenden" Button genutzt werden kann.
- Ändern Sie die Klasse AusnahmeFenster derart,dass Sie für den "Beenden" Button nicht mehr das Ausnahmefenster als Objekt registrieren (this). Erzeugen Sie als registrierten Listener eine Instanz der Klasse SystemExitListener.
Sie haben nun eine eigene Klasse mit einem eigenen Objekt zur Behandlung des "Beenden" Ereignisses
Weiterführend (optional)
Implementieren Sie einen Menüeintrag "Beenden" in einer Menüleiste mit dem EIntrag "Ablage".
|
Herangehen:
|
 |
Aufgabe 2:
- Die Klasse AusnahmeFenster soll NICHT mehr die Schnittstelle ActionListener implementieren.
- Implementieren Sie eine innere Klasse SystemExitAction. Sie soll einen ActionListener implementieren, der das Programm beendet.
- Ändern sie den Aufruf addActionListener() des exitButton so, dass er die Klasse SystemExitAction benutzt.
- Ändern Sie den Aufruf addActionListener() des okButton so, dass eine anonyme innere Klasse aufgerufen wird die einen Stacktrace ausdruckt
Hierdurch entfällt die Analyse der auslösenden Aktion in der ursprünglichen Implementierung. Für jede Aktion wurde jetzt eine eigene Methode implementiert
- 8470 views
Lösungen (Swing)
Lösungen (Swing)Ausnahmefenster
package s2.swing;
import java.awt.BorderLayout;
import java.awt.Container;
import java.awt.GridLayout;
import java.awt.event.ActionEvent;
import java.awt.event.ActionListener;
import java.net.URL;
import javax.swing.ImageIcon;
import javax.swing.JButton;
import javax.swing.JFrame;
import javax.swing.JLabel;
import javax.swing.JPanel;
import javax.swing.JTextArea;
public class AusnahmeFensterLoesung implements ActionListener {
final private JFrame hf;
final private JButton okButton;
final private JButton exitButton;
final private Exception myException;
/**
* Aufbau des Fensters zur Ausnahmebehandlung
*
* @param fehlermeldung ein beliebiger Fehlertext der angezeigt wird
* @param e Die Ausnahme die angezeigt werden soll
*/
public AusnahmeFensterLoesung(String fehlermeldung, Exception e) {
JLabel logo;
JPanel buttonPanel;
myException = e;
hf=null;
okButton=null;
exitButton=null;
// 1. Erzeugen einer neuen Instanz eines Swingfensters
hf = new JFrame("Anwendungsfehler");
// 8. Labelerzeugung
logo = meinLogo();
// 4. Beenden bei Schliesen des Fenster
hf.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
// 5. Anlegen der Buttons
okButton = new JButton();
okButton.setText("Stack Trace");
exitButton = new JButton();
exitButton.setText("Beenden");
// 10. Hinzügen der Eventbehandlung
okButton.addActionListener(this);
exitButton.addActionListener(this);
// 6. Aufbau des Panels
buttonPanel = new JPanel(new GridLayout(1, 0));
buttonPanel.add(exitButton);
buttonPanel.add(okButton);
JTextArea fehlertextArea = new JTextArea(2, 20);
fehlertextArea.append(fehlermeldung + "\n");
fehlertextArea.append("Exception: "+ myException);
// 7. Aubau des ContentPanes
Container myPane = hf.getContentPane();
myPane.setLayout(new BorderLayout());
myPane.add(logo, BorderLayout.NORTH);
myPane.add(fehlertextArea, BorderLayout.CENTER);
myPane.add(buttonPanel, BorderLayout.SOUTH);
// 2.1 Das Layout des JFrame berechnen.
hf.pack();
// 3. Gewünschte Größe setzen
// 1. Parameter: horizontale Größe in Pixel
// 2. Parameter: vertikale Größe
hf.setSize(350, 300);
// 2.2 Sichtbar machen des JFrames. Immer im Vordergrund
hf.setVisible(true);
hf.setAlwaysOnTop(true);
}
/**
* Implementieren des Logos
* 9.ter Schritt
* @return Zeiger auf das Logoobjekt
*/
private JLabel meinLogo() {
URL logoURL;
JLabel logoLabel;
String myURL = "https://upload.wikimedia.org/wikipedia/commons/0/01/DHBW_MA_Logo.jpg;
try {
logoURL = new URL(myURL);
ImageIcon myImage = new ImageIcon(logoURL);
logoLabel = new JLabel(myImage);
} catch (java.net.MalformedURLException e) {
System.out.println(e);
System.out.println("Logo URL kann nicht aufgelöst werden");
logoLabel = new JLabel("Logo fehlt");
}
return logoLabel;
}
/**
* Behandlung der JButton Ereignisse
* 11. ter Schritt
* @param e
*/
public void actionPerformed(ActionEvent e) {
JButton source = (JButton) (e.getSource());
if (source == exitButton) {
System.exit(0);
}
if (source == okButton) {
System.out.println("OK Button clicked");
myException.printStackTrace();
}
}
/**
* Hauptprogramm zum Testen des Ausnahmefensters
* @throws Exception
*/
public static void main(String[] args) {
AusnahmeFensterLoesung dasFenster;
try {myTestMethod();}
catch (Exception e) {
dasFenster = new AusnahmeFensterLoesung("Hier läuft etwas schief",e);
}
}
/**
* Eine Testmethode die eine durch eine Division durch Null eine
* Ausnahme provoziert
* @throws Exception
*/
public static void myTestMethod() throws Exception {
int a = 5;
int b = 5;
int c = 10;
c = c / (a-b);
System.out.println("Programm regulär beendet");
}
}
Taschenrechner
Die Universität Bielefeld (Herr Jan Krüger) bieten die Lösung der Programmieraufgabe an unter:
Innere und anonyme Klasse
Aufgabe 1
Klasse SystemExitListener
package s2.swing;
import java.awt.event.ActionEvent;
import java.awt.event.ActionListener;
/**
*
* @author s@scalingbits.com
* Implementierung eines ActionListener der als Aktion die Anwendung
* beendet
*/
public class SystemExitListener implements ActionListener{
@Override
public void actionPerformed(ActionEvent e) {
System.exit(0);
}
}
Einfügen eines Menüs (Optional)
import javax.swing.*;
...
JMenuItem jmi = new JMenuItem("Beenden");
jmi.addActionListener(new SystemExitListener());
JMenu jm = new JMenu("Ablage");
jm.add(jmi);
JMenuBar jmb = new JMenuBar();
jmb.add(jm);
hf.setJMenuBar(jmb);
Aufgabe 2
Hinweis: Die Klasse wurde in AusnahmeFensterInnerer umbenannt
}
hf.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
- 5540 views
Zu Übung 1 (Swing)
Wie in der Veranstaltung: hf.setDefaultCloseOperation(JFrame.HIDE_ON_CLOSE); sollte sein hf.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE); damit das Programm beim Schließen des Fensters beendet wird. Viele Grüße
- Log in to post comments
Danke für die Erinnerung.
habe den Code verbessert.
Kommentar für die nicht Eingeweihten:
Mit diesen beiden Optionen kann man steuern ob die gesamte Anwendung bei schliesen des Fensters beendet wird. In der Übung macht das Beenden der Anwendung Sinn, da man sonst nichts mehr machen kann. Bei realen Anwendungen ist es oft besser wenn man die Anwendung nicht beendet weil es oft Ikonen oder Menüleisten gibt, die es erlauben neue Fenster zu öffnen.
- Log in to post comments
Lernziele (Swing, innere und anonyme Klassen)
Lernziele (Swing, innere und anonyme Klassen)|
|
Am Ende dieses Blocks können Sie:
|
Lernzielkontrolle
Sie sind in der Lage die folgenden Fragen zu beantworten:Fragen zur graphischen Programmierung (Swing)

- 3597 views
Generische Klassen (Generics)
Generische Klassen (Generics)|
|
Generische (engl. generic) Klassen, Schnittstellen und Methoden wurden in Java in der Version 5.0 eingeführt. Generisch bedeutet in diesem Zusammenhang, dass die entsprechenden Klassen, Methoden und Schnittstellen parametrisierbare Typen verwenden. Ein Übergabetyp ist also nicht im Quellcode festgelegt, er kann bei der Verwendung zum Übersetzungszeitpunkt verschiedene Ausprägungen annehmen. |
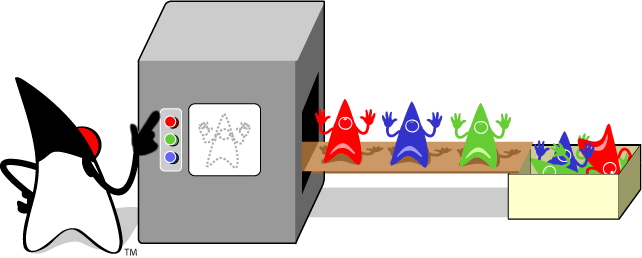
Das Konzept der generischen Klassen erhöht die Typsicherheit im Zusammenhang mit Polymorphismus und Vererbung. Eine Erhöhung der Typsicherheit bedeutet, dass der Entwickler weniger explizite Casts verwenden muss um Typkonversionen und Anpassungen zu erzwingen.
| Generische Klasse |
|---|
| Verwendet eine Klasse formale Typ-Parameter so nennt man sie generische Klasse. Der formale Typ-Parameter ist ein symbolischer Typ der wie ein normaler Bezeichner in Java aufgebaut ist. Er wird nach dem Klassennamen in spitzen Klammern angegeben. |
Am einfachsten lässt sich das Konzept an einem Beispiel einer Klasse Koordinate mit einem parametrisierbaren Typen <T> veranschaulichen:
public class Koordinate<T> {
private T x;
private T y;
Koordinate(T p1, T p2) {
x = p1;
y = p2;
}
...
}
In dieser Implementierung der Klasse wird der eigentliche Typ der Komponenten (x und y) der Klasse Koordinate nicht konkret festgelegt. Ein Konsument dieser Klasse kann sich entscheiden diese Implementierung für Integer, Float oder Double zu verwenden. Die allgemeine Syntaxregel für die Deklaration einer generischen Klasse lautet:
| Deklaration einer generischen Klasse |
|---|
class Klassenname < Typvariablenliste > {//Body} |
Will man die Implementierung der generischen Klasse Koordinate für große Fließkommazahlen verwenden, so benutzt man die folgende Syntax:
Koordinate<Double> eineKoordinate = new Koordinate<Double>(2.2d, 3.3d);
Der Typ ist parametrisierbar und wird Teil des Variablennamens bzw. des Klassennamens. Die allgemeine Syntax zum Erzeugen eines Objekts einer generischen Klasse lautet:
| Instanziieren einer generischen Klasse |
|---|
new Klassenname < Typliste > ( Parameterliste); |
Will man kleinere Fließkommazahlen benutzen, so kann man die Klasse Koordinate auch mit dem Typ Float parametrisieren:
Koordinate<Float> nochEineKoordinate = new Koordinate<Float>(4.4f, 5.5f);
Beispiel einer einfachen generischen Klasse
Die Klasse Koordinate hat ein Hauptprogramm main() welches zwei Instanzen mit unterschiedlichen Ausprägungen erzeugt und bei der Ausgabe der Werte die Methode toString() implizit aufruft:
package s2.generics;
/**
*
* @author s@scalingbits.com
* @param <T> Generischer Typ der Klasse Koordinate
*/
public class Koordinate<T> {
private T x;
private T y;
public T getX() {return x;}
public void setX(T x) {this.x = x;}
public T getx() {return x;}
public void setY(T y) { this.y = y;}
public T getY() {return y;}
public Koordinate(T xp, T yp ) {
x = xp;
y = yp;
}
@Override
public String toString() {return "x: " + x + "; y: " + y;}
public static void main (String[] args) {
Koordinate<Double> k1 = new Koordinate<Double>(2.2d, 3.3d);
System.out.println(k1);
Koordinate<Integer> k2 = new Koordinate<Integer>(2, 3);
System.out.println(k2);
Koordinate<Number> k3 = new Koordinate<Number>(4.4f, 5.5f);
System.out.println(k3);
} // Ende main()
} // Ende Klasse KoordinateBei der Ausführung ergibt sich die folgende Konsolenausgabe:
x: 2.2; y: 3.3 x: 2; y: 3 x: 4.4; y: 5.5
- 12618 views
Generics zur Übersetzungs- und Laufzeit
Generics zur Übersetzungs- und LaufzeitDer javac Übersetzer erzeugt aus der gegebenen generischen Klasse in der Datei Koordinate.java nur genau eine Datei Koordinate.class mit Bytecode für alle möglichen Instanzierungen.
package s2.generics;/**
*
* @author s@scalingbits.com
* @param <T> Generischer Typ der Klasse Koordinate
*/
public class Koordinate<T> {
private T x;
private T y;public T getX() {return x;}
public void setX(T x) {this.x = x;}
public T getx() {return x;}
public void setY(T y) { this.y = y;}
public T getY() {return y;}public Koordinate(T xp, T yp ) {
x = xp;
y = yp;
}@Override
public String toString() {return "x: " + x + "; y: " + y;}public static void main (String[] args) {
Koordinate<Double> k1 = new Koordinate<Double>(2.2d, 3.3d);
System.out.println(k1);
Koordinate<Integer> k2 = new Koordinate<Integer>(2, 3);
System.out.println(k2);
Koordinate<Number> k3 = new Koordinate<Number>(4.4f, 5.5f);
System.out.println(k3);
}
}
Der erzeugte Bytecode enthält nicht mehr den Formalparameter <T>. Er enthält den Referenztyp Object. Aus diesem Grund kann der Bytecode mit allen Instanzierungen arbeiten solange sie aus der Klasse Object abgeleitet sind. Direkte Basistypen wie int oder long können daher nicht direkt in generischen Klassen verwendet werden. Die Stellvertreterklassen Integer und Long in Verbindung mit dem "Autoboxing" sind der Ersatz für die direkte Verwendung.
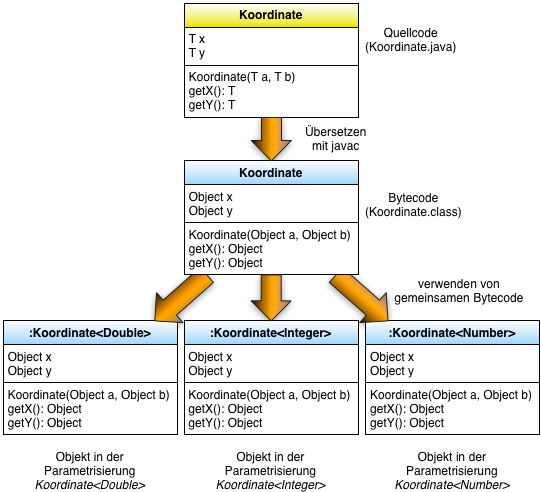
Zur Laufzeit kann dann der Bytecode verwendet werden um den aktuell parametrisierten Parametern zu arbeiten.
Das Ersetzen der Parametrisierung <T> durch die Klasse Object nennt man Type-Erasure (engl. Auslöschen).
| Polymorphismus und Vererbung von generischen Klassen |
|---|
|
Aufgrund der Möglichkeit die Klassen mit unterschiedlichen aktuellen Parametern zu benutzen sind generische Klassen polymorph. Die aktuell parametrisierten Objekte stehen jedoch auf der gleichen Vererbungsebene. Sie haben keine Vererbungsbeziehung! |
- 5393 views
Generics, Autoboxing, Subtyping
Generics, Autoboxing, SubtypingDie im vorhergehenden Beispiel benutzte Klasse kann aber auch als aktuellen Parameter eine abstrakte Klasse wie Number verwenden:
Mit Hilfe des Java Autoboxing kann man die Variablen k3 und k4 auch wie folgt belegen:
Koordinate<Number> k3 = new Koordinate<Number>(2l, 3l); System.out.println(k3);
k3 = new Koordinate<Number>(4.4f, 5.5f);
System.out.println(k3);
Die Variable k3 hat den formalen Parametertyp Number. Die aktuellen Parameter 21 und 31 sind int Typen. Sie werden automatisch in Instanzen von Integer umgewandelt und sind daher Spezialisierungen der Klasse Number. Die Variable k3 zeigt hier zuerst auf eine Koordinate die aus ganzen Zahlen besteht und anschließend auf eine Koordinate die aus Fließkommanzahlen bestehen
Ohne Autoboxing würde man die Variable k3 so belegen:
Koordinate<Number> k3 = new Koordinate<Number>(new Integer(2l), new Integer(3l));
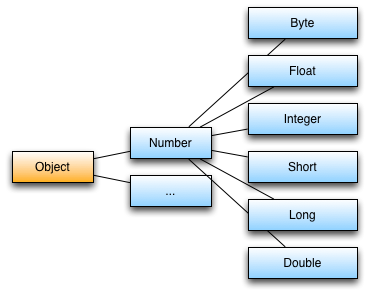
Subtyping
Die parametrisierte Klasse Koordinate<Number> kann zwar wahlweise auf verschiedene Varianten von Objekten zugreifen die parametrisiert mit Koordinate<Number> erzeugt wurden. Sie kann aber nicht auf Objekte gleichen Inhalts aus Koordinate<Integer> zugreifen. Das folgende Implementierungsbeispiel erlaubt nicht die letzte Zuweisung von k2 auf k3:
Koordinate<Double> k1 = new Koordinate<Double>(2.2d, 3.3d);
Koordinate<Integer> k2 = new Koordinate<Integer>(2, 3);
Koordinate<Number> k3 = new Koordinate<Number>(2l, 3l);
k3 = new Koordinate<Number>(4.4f, 5.5f);
k3 = k2; // FehlerDie Vererbungsbeziehung besteht nicht zwischen den generischen Klassen selbst. Der Javaübersetzer erzeugt den folgenden Fehler:
found : Kurs2.Generics.Koordinate<java.lang.Integer>
required: Kurs2.Generics.Koordinate<java.lang.Number>
k3 = k2;In diesem Beispiel wird das "Liskov Substitution Principle" verletzt! Der Übersetzer javac erkennt diese Fehler und übersetzt diesen Quellcode nicht.
- 5453 views
Vererbung und generische Klassen
Vererbung und generische KlassenDie Vererbung zwischen generischen Klassen untereinander und mit nicht generischen Klassen ergibt eine zweidimensionale Tabelle von Möglichkeiten:
| Oberklasse generisch | Oberklasse nicht generisch | |
|---|---|---|
| Unterklasse generisch | ||
| Unterklasse nicht generisch |
|
Eine generische Klasse erweitert eine generische Klasse
Will man eine generische Klasse aus einer anderen generischen Klasse ableiten so gibt es zwei Möglichkeiten:
- der formale Typ-Parameter der Oberklasse wird weitervererbt
- der formale Typ-Parameter der Oberklasse wird durch einen aktuellen Parameter ersetzt.
Formaler Parameter der Oberklasse ersetzt formalen Parameter der Unterklasse
Bei dieser Form der Vererbung hat die Klassendeklaration der Unterklasse die folgende Noatation:
public class Unterklasse<T> extends Oberklasse<T>
Ein Beispiel ist die Erweiterung der zweidimensionalen Klasse Koordinate zu einer drei dimensionalen Koordinate in der Klasse Koordinate3DGen
package s2.generics;/**
*
* @author s@scalingbits.com
* @param <T> Generischer Typ der Klasse Koordinate
*/
public class Koordinate3DGen<T> extends Koordinate<T> {
private T z;public T getZ() {return z;}
public void setZ(T z) {this.z = z;}public Koordinate3DGen (T x, T y, T z) {
super (x,y);
this.z = z;
}@Override
public String toString() {return super.toString()+", z: "+ z;}public static void main (String[] args) {
Koordinate3DGen<Double> k1 = new Koordinate3DGen<Double>(1.1d, 2.2d, 3.3d);
System.out.println(k1);Koordinate3DGen<Integer> k2 = new Koordinate3DGen<Integer>(1,2,3);
System.out.println(k2);
}
}
Die z Dimension kann in dieser Klasse immer nur mit dem aktuellen Parameter der beiden anderen Dimensionen instanziiert werden.
Formaler Typ-Parameter der Oberklasse wird durch aktuellen Parameter ersetzt
Eine andere Möglichkeit besteht darin den formalen Typparameter der Oberklasse durch einen aktuellen zu ersetzen und gleichzeitig einen neuen formalen Typparameter einzuführen. Hier haben die Klassendeklarationen die folgende Form:
public class Unterklasse<T> extends Oberklasse<konkrete-Klasse>
Ein Beispiel hierfür sei eine zweidimensionale Koordinate die über ein generisches Gewichtsattribut verfügt. Als aktueller Typparameter wird hier der Typ Double ausgewählt:
package s2.generics;
/**
*
* @author s@scalingbits.com
* @param <T> Die Dimensionen der Koordinate
*/
public class Koordinate2DGewicht<T> extends Koordinate<Double> {
private T gewicht;public T getGewicht() {return gewicht;}
public void setGewicht(T g) {gewicht = g;}public Koordinate2DGewicht (Double x, Double y, T g) {
super (x,y);
gewicht = g;
}@Override
public String toString() {return super.toString()+", Gewicht: "+ gewicht;}public static void main (String[] args) {
Koordinate2DGewicht<Double> k1 = new Koordinate2DGewicht<Double>(1.1d, 2.2d, 9.9d);
double dx = k1.getX();
System.out.println(k1);Koordinate2DGewicht<Integer> k2 = new Koordinate2DGewicht<Integer>(1.1d,2.2d,9);
System.out.println(k2);
}
}
Achtung: Der formale Typparamter T der Klasses Koordinate2Gewicht wurde an dieser Stelle neu eingeführt. Er ist ein anderer als der formale Typparameter T der Oberklasse Koordinate!
Generische Unterklasse leitet aus nicht generischer Oberklasse ab
Eine generische Klasse auch eine nicht generische Klasse erweitern. Hier wird der Typ-Parmater neu in die Klassenhierarchie eingeführt. Die Klassendeklarationen genügen dann der folgenden Form:
public class Unterklasse<T> extends Oberklasse
Ein Beispiel hierfür ist eine nicht generische Oberklasse Koordinate2D aus der eine generische Unterklasse Koordinate2DGewichtGen<T> abgeleitet wird:
package s2.generics;
/**
*
* @author s@scalingbits.com
*/
public class Koordinate2D {
private Double x;
private Double y;public Double getX() {return x;}
public void setX(Double x) {this.x = x;}
public Double getY() {return y;}
public void setY(Double y) { this.y = y;}public Koordinate2D(Double xp, Double yp ) {
x = xp;
y = yp;
}@Override
public String toString() {return "x: " + x + "; y: " + y;}public static void main (String[] args) {
Koordinate2D k1 = new Koordinate2D(2.2d, 3.3d);
System.out.println(k1);
}
}
public class Koordinate2DGewichtGen<T> extends Koordinate2D {
private T gewicht;
public T getGewicht() {return gewicht;}
public void setGewicht(T g) {gewicht = g;}public Koordinate2DGewichtGen (Double x, Double y, T g) {
super (x,y);
gewicht = g;
}@Override
public String toString() {return super.toString()+", Gewicht: "+ gewicht;}public static void main (String[] args) {
Koordinate2DGewichtGen<Double> k1 = new Koordinate2DGewichtGen<Double>(1.1d, 2.2d, 9.9d);
double dx = k1.getX();
System.out.println(k1);Koordinate2DGewichtGen<Integer> k2 = new Koordinate2DGewichtGen<Integer>(1.1d,2.2d,9);
System.out.println(k2);
}
}
Nicht generische Unterklasse leitet aus generischer Oberklasse ab
Die letzte Variante besteht aus nicht generischen Klassen die aus einer generischen Oberklasse ableiten in dem sie einen aktuellen Typ-Parameter für die Unterklasse aus der Oberklasse wählen. Die Klassendeklarationen dieser Klassen haben die folgende Schreibweise:
public class Unterklasse extends Oberklasse<konkrete-Klasse>
Ein Beispiel hierfür sei die Klasse Koordinate3DDouble die nicht generisch ist und für die x und y Koordinate die Klasse Koordinate mit dem aktuellen Typparameter Double verwendet:
package s2.generics;
/**
*
* @author s@scalingbits.com
*/
public class Koordinate3DDouble extends Koordinate<Double> {
private Double z;public Double getZ() {return z;}
public void setZ(Double z) {this.z = z;}@Override
public String toString() {return super.toString()+", z: "+ z;}public Koordinate3DDouble (Double x, Double y, Double z) {
super (x,y);
this.z = z;
}public static void main (String[] args) {
Koordinate3DDouble k1 = new Koordinate3DDouble(1.1d, 2.2d, 3.3d);
double d1 = k1.getX(); //Generezität nicht mehr sichtbar
System.out.println(k1);
}
}
- 13526 views
allgemeine Sytax-Regeln
Müssten die Syntax-Regeln nicht eigentlich Oberklasse
- Log in to post comments
Wildcards
Wildcards"Wildcards" sind ein Begriff aus dem Englischen und beziehen sich auf die Joker im Pokerspiel, die vielfältig eingesetzt werden können. Der Begriff wird im Computerumfeld verwendet wenn es um Platzhalter für andere Zeichen geht.
Unbound Wildcards
Die Wildcards werden benötigt um mit Referenzen auf generische Objekte zu zeigen und deren Ausprägung mehr oder weniger allgemein zu definieren. Eine Referenz auf ein Objekt der verwendeten generischen Klasse Koordinate<T> kann man mit einer Wildcard so beschreiben:
Koordinate<?> zeiger;
Ein Fragezeichen ? ist eine "unbound Wildcard". Sie erlaubt es auf jeden beliebigen Typ der Klasse Koordinate<T> zu zeigen.
Beispiel:
package s2.generics;
/**
*
* @author s@scalingbits.com
*/
public class Koordinate<T> {
private T x;
private T y;
public T getX() {return x;}
public void setX(T x) {this.x = x;}
public T getY() {return y;}
public void setY(T y) { this.y = y;}
public Koordinate(T xp, T yp ) {
x = xp;
y = yp;
}
@Override
public String toString() {return "x: " + x + "; y: " + y;}
public static void main (String[] args) {
Koordinate<Double> k1 = new Koordinate<Double>(2.2d, 3.3d);
System.out.println(k1);
Koordinate<Integer> k2 = new Koordinate<Integer>(2, 3);
System.out.println(k2);
Koordinate<Number> k3 = new Koordinate<Number>(2l, 3l);
System.out.println(k3);
k3 = new Koordinate<Number>(4.4f, 5.5f);
System.out.println(k3);
Koordinate<?> zeiger;
zeiger = k1;
zeiger = k2;
zeiger = k3;
}
} // Ende der Klasse KoordinateDie Referenzvariable zeiger kann im gezeigten Beispiel auf beliebig parametrisierte Objekte der Klasse Koordinate<T> zeigen.
| Wichtig |
|---|
|
Die Wildcard kann nicht in der Sektion des Typ-Parameter einer Klasse, Methode oder Schnittstelle stehen! Sie kann nur im Kontext von Referenzvariablen verwendet werden! |
Umgangssprachlich: Die Wildcard findet man immer nur links des Zuweisungsoperators oder in einer Variablendeklaration.
Die Upper Bound Wildcard
Die bisher verwendeten Typparameter erlauben die Instanziierung einer Klasse mit jeder beliebigen Klasse (die aus der Klasse Object abgeleitet wird). Dies ist oft zu allgemein und kann kontraproduktiv sein.
Bei der Klasse Koordinate macht es keinen Sinn sie mit dem Typ-Parameter Boolean zu parametrisieren:
Koordinate<Boolean> k = new Koordinate<Boolean>(true, true);
Das oben gezeigte Beispiel ist eine korrekte Zuweisung die man übersetzen und ausführen kann. Man kann eine solche Verwendung unterbinden wenn die Typenstruktur Klassenhierachie von Java für Zahlen nutzt:
Man kann die Klasse Number als Oberklasse für alle erlaubten Parametrisierungen wählen und den generischen Typ der Klasse Koordinate<T> einschränken:
public class Koordinate<T extends Number>
Durch diese Notation wird der formale Typparameter auf die Klasse Number oder Spezialisierungen daraus beschränkt. Man spricht von einer "Upper Bound Wildcard" weil die Verwendung von Klassen nach oben (zur Wurzel der Klasse) hin beschränkt ist.
Die Lower Bound Wildcard
Neben der "Upper Bound Wildcard" gibt es auch eine "Lower Bound Wild Card". Sieht wird trotz des ähnlichen Namens, sehr unterschiedlich verwendet.
Sie wird ausschließlich mit der "Unbound Wildcard" in der Schreibweise "? super Lowerbound" bei der Typfestlegung von Referenzen verwendet.
Die generische Klasse selbst ist hier beliebig. Sie sei:
public class MyGenericClass<T> {
// Inhalt der Klasse ist nicht wichtig
}Weiterhin sei eine Klassenhierarchie mit Klassen von A bis F gegeben:
mit Hilfe der "Lower Bound Wildcard" kann die Verwendung einer Referenz so eingeschränkt werden, dass nur Instanzen der Klasse C oder Klassen von denen C abgeleitet wurde, verwendet werden darf.
public class TestClass {
...
public void testCreate(MyGenericClass<? super C> zeiger) {
....
}
public void test () {
TestClass.testCreate(new MyGenericClass<C>()); // Korrekt
TestClass.testCreate(new MyGenericClass<A>()); // Korrekt
TestClass.testCreate(new MyGenericClass<Object>()); // Korrekt
TestClass.testCreate(new MyGenericClass<F>()); // Fehler!!
TestClass.testCreate(new MyGenericClass<D>()); // Fehler!!
}
}Die Typ-Parameter der Klassen E, F und B können nicht übergeben werden, da sie nicht in der Typhierarchie der Klasse C vorkommen.
Im Java API werden auch "Lower Bound Wildcards" verwendet. Ein Beispiel ist die drainTo() Methode der Schnittstelle BlockingQueue:
int drainTo(Collection<? super E> c, int maxElements)
- 8826 views
Der "Diamondoperator" in Java
Der "Diamondoperator" in JavaBei der Verwendung generischer Datentypen ensteht zuätzlicher Schreibaufwand, da man den Typ inklusive seines generischen Typs an vielen Stellen nennen muss. Ein Bespiel hierfür ist:
Koordinate<Double> meinPunkt = new Koordinate<Double>(1.1D,2.2D);
Man muss den generischen Typ Double in der Deklaration der Referenzvariable, wie auch im Konstruktoraufruf beim Anlegen des Objekts nennen.
Seit Java 7 ist es erlaubt eine verkürzte Schreibweise zu verwenden. Man nennt diese verkürzte Schreibweise den "Diamondoperator" weil das Kleiner- und Größerzeichen an einen Kristall erinnern. Das obige Beispiel lässt sich auch verkürzt so programmieren:
Koordinate<Double> meinPunkt = new Koordinate<>(1.1D,2.2D);
Der Übsetzer leitet sich die notwendige Typinformation beim Konstruktoraufruf aus dem generischen Typ der Referenzvariable ab.
Bemerkung: Dies ist eine stark verkürzte Erklärung.
Die automatische Bestimmung des Typs durch den Übersetzer kann recht kompliziert sein, da die Konzepte der Vererbung, Interfaces (Schnittstellen), Casts und Autoboxing beachtet werden müssen.
Weiterführende Ressourcen
- 3078 views
Übungen, Fragen (Generics)
Übungen, Fragen (Generics)1. Frage: Instanziierungen
Gegeben seien die folgenden Klassen:
public class Kaefig<T> {
private T einTier;
public void setTier(T x) {
einTier = x;
}
public T getTier() {
return einTier;
}
}
public class Tier{ }
public class Hund extends Tier { }
public class Vogel extends Tier { }
Beschreiben Sie was mit dem folgenden Code geschieht. Die Möglichkeiten sind
- er übersetzt nicht
- er übersetzt mit Warnungen
- er erzeugt Fehler während der Ausführung
- er übersetzt und läuft ohne Probleme
1.1
Kaefig<Tier> zwinger = new Kaefig<Hund>();
1.2
Kaefig<Vogel> voliere = new Kaefig<Tier>();
1.3
Kaefig<?> voliere = new Kaefig<Vogel>();
voliere.setTier(new Vogel());
1.4
Kaefig voliere = new Kaefig();
voliere.setTier(new Vogel());
2. Umwandeln einer nicht generischen Implementierung in eine generische Implementierung
In diesem Beispiel werden Flaschen mit verschiedenen Getränken gefüllt und entleert. Das Befüllen und Entleeren erfolgt in der main() Methode der Klasse Flasche.
Die vorliegende Implementierung erlaubt das Befüllen der Flaschen f1 und f2 mit beliebigen Getränken.
Aufgabe:
Ändern Sie die Implementierung der Klasse Flasche in eine generische Klasse die für unterschiedliche Getränke parametrisiert werden kann.
- passen Sie alle Methoden der Klasse Flasche so an das sie mit einem parametrisierten Getränk befüllt werden können (Bier oder Wein)
- Ändern Sie die main() Methode derart, dass f1 nur mit Bier befüllt werden kann und f2 nur mit Wein.
2.1 Klasse Flasche
Die Klasse dient als Hauptprogramm. In dieser Übung müssen ausschließlich die Methoden dieser Klasse und das Hauptprogramm angepasst werden.
package s2.generics;
/**
*
* @author s@scalingbits.com
*/
public class Flasche {Getraenk inhalt = null;
public boolean istLeer() {
return (inhalt == null);
}public void fuellen(Getraenk g) {
inhalt = g;
}public Getraenk leeren() {
Getraenk result = inhalt;
inhalt = null;
return result;
}public static void main(String[] varargs) {
// in generischer Implementierung soll
// f1 nur für Bier dienen
Flasche f1 = new Flasche();
f1.fuellen(new Bier("DHBW-Bräu"));
System.out.println("f1 geleert mit " + f1.leeren());
f1 = new Flasche();
f1.fuellen(new Bier("DHBW-Export"));
System.out.println("f1 geleert mit " + f1.leeren());
// In der generischen Implementierung soll f2 nur für
// Weinflaschen dienen
Flasche f2;
f2 = new Flasche();
f2.fuellen(new Weisswein("Pfalz"));
System.out.println("f2 geleert mit " + f2.leeren());
f2 = new Flasche();
f2.fuellen(new Rotwein("Bordeaux"));
System.out.println("f2 geleert mit " + f2.leeren());
}
}
2.2 Klasse Getraenk
package s2.generics;public abstract class Getraenk {
}
2.3 Klasse Bier
package s2.generics;public class Bier extends Getraenk {
private String brauerei;
public Bier(String b) { brauerei = b;}
public String getBrauererei() {
return brauerei;
}
public String toString() {return "Bier von " + brauerei;}
}
2.4 Klasse Wein
package s2.generics;public class Wein extends Getraenk {
private String herkunft;public String getHerkunft() {
return herkunft;
}public String toString(){ return ("Wein aus " + herkunft);}
public Wein (String origin) {
herkunft = origin;
}}
2.5 Klasse Weisswein
package s2.generics;public class Weisswein extends Wein {
public Weisswein(String h) {super(h);}}
2.6 Klasse Rotwein
package s2.generics;public class Rotwein extends Wein {
public Rotwein(String h) {super(h);}}
3. Typprüfungen
Welche Zeilen in der main() Methode werden vom Übersetzer nicht übersetzt?
Markieren Sie die Zeilen und nennen Sie den Fehler:
package s2.generics;
/**
*
* @author s@scalingbits.com
* @param <T> ein Getraenk
*/
public class KoordinateTest<T extends Number> {public T x;
public T y;public KoordinateTest(T xp, T yp) {
x = xp;
y = yp;
}public static void main(String[] args) {
KoordinateTest<Double> k11, k12;
KoordinateTest<Integer> k21, k22;
Koordinate<String> k31;
KoordinateTest<Number> k41, k42;
KoordinateTest<Float> k81, k82;
k81 = new KoordinateTest<Float>(2.2f, 3.3f);
k12 = new KoordinateTest<Double>(2.2d, 3.3d);
k21 = new KoordinateTest<Integer>(2, 3);
//k31 = new Koordinate<String>("11","22");
k41 = new KoordinateTest<Number>(2l, 3l);
k41 = new KoordinateTest<Number>(4.4d, 5.5f);
k11 = new KoordinateTest<Double>(3.3d,9.9d);
KoordinateTest<? super Double> k99;
k99 = k11;
k99 = k41;
k99 = k31;
k11 = k12;
k12 = k21;
KoordinateTest k55 = new KoordinateTest<Number>(7.7f, 8.8f);
KoordinateTest k66 = new KoordinateTest(7.7d, 3.d);
}
}
- 11153 views
Lösungen, Antworten
Lösungen, Antworten1. Antwort: Instanziierungen
Gegeben seien die folgenden Klassen:
public class Kaefig<T> {
private T einTier;
public void setTier(T x) {
einTier = x;
}
public T getTier() {
return einTier;
}
public class Tier{ }
public class Hund extends Tier { }
public class Vogel extends Tier { }
}Beschreiben Sie was mit dem folgenden Code geschieht. Die Möglichkeiten sind
- er übersetzt nicht
- er übersetzt mit Warnungen
- er erzeugt Fehler während der Ausführung
- er übersetzt und läuft ohne Probleme
1.1
Kaefig<Tier> zwinger = new Kaefig<Hund>();
Übersetzungsfehler: Hund ist zwar eine Unterklasse von Tier. Kaefig<Tier> und Kaefig<Hund> sind keine kompatiblen Typen.
1.2
Kaefig<Vogel> voliere = new Kaefig<Tier>();
Übersetzungsfehler: Vogel ist zwar eine Unterklasse von Tier. Kaefig<Tier> und Kaefig<Vogel> sind keine kompatiblen Typen.
1.3
Kaefig<?> voliere = new Kaefig<Vogel>(); voliere.setTier(new Vogel());
Übersetzungsfehler in der zweiten Zeile. Die erste Zeile ist in Ordnung. Man kann einen Kaefig eines unbekannten aktuellen Parametertyps erzeugen. Die zweite Zeile kann nicht übersetzen, da der Übersetzer nicht wissen kann welche Tiere in voliere verwaltet werden sollen. Der folgende Code würde übersetzen:
Kaefig<?> voliere = new Kaefig<Vogel>(); Kaefig<Vogel> k= new Kaefig<Vogel>(); k.setTier(new Vogel()); voliere=k;
Anmerkung: Man darf nur Referenzen auf Zeiger mit Wildcards (hier voliere) zuweisen. Man darf keine Objektmethoden aufrufen weil hierfür der Typ zur Übersetzungszeit nicht bekannt ist.
1.4
Kaefig voliere = new Kaefig(); voliere.setTier(new Vogel());
Der Übersetzer übersetzt den Quellcode mit einer Warnung. Er kann nicht wissen welchen Typ er benutzt. Er erzeugt deshalb eine Warnung, weil es beim Zuweisen eines Vogels zu Problemen kommen kann. Man verliert die Vorteile der Typprüfung der generischen Klassen. Dieser Codierstil sollte deshalb vermieden werden.
2. Umwandeln einer nicht generischen Implementierung in eine generische Implementierung
package s2.generics;
/**
*
* @author s@scalingbits.com
* @param <T> ein Getraenk
*/
public class FlascheGeneric<T extends Getraenk> {
T inhalt = null;
public boolean istLeer() {
return (inhalt == null);
}
public void fuellen(T g) {
inhalt = g;
}
public T leeren() {
T result = inhalt;
inhalt = null;
return result;
}
public static void main(String[] varargs) {
// in generischer Implementierung soll
// f1 nur für Bier dienen
FlascheGeneric<Bier> f1 = new FlascheGeneric<Bier>();
f1.fuellen(new Bier("DHBW-Bräu"));
System.out.println("f1 geleert mit " + f1.leeren());
f1 = new FlascheGeneric<Bier>();
f1.fuellen(new Bier("DHBW-Export"));
System.out.println("f1 geleert mit " + f1.leeren());
// In der generischen Implementierung soll f2 nur für
// Weinflaschen dienen
FlascheGeneric<Wein> f2;
f2 = new FlascheGeneric<Wein>();
f2.fuellen(new Weisswein("Pfalz"));
System.out.println("f2 geleert mit " + f2.leeren());
f2 = new FlascheGeneric<Wein>();
f2.fuellen(new Rotwein("Bordeaux"));
System.out.println("f2 geleert mit " + f2.leeren());
}
}3. Typprüfungen
Welche Zeilen in der main() Methoder werden vom Übersetzer nicht übersetzt?
Markieren Sie die Zeilen und nennen Sie den Fehler:
package s2.generics;
public class KoordinateTest<T extends Number> {
public T x;
public T y;
public KoordinateTest(T xp, T yp) {
x = xp;
y = yp;
}
public static void main(String[] args) {
KoordinateTest<Double> k11, k12;
KoordinateTest<Integer> k21, k22;
//Koordinate<String> k31; Die Klasse String ist nicht aus Number abgeleitet. Siehe extends Klausel
KoordinateTest<Number> k41, k42;
//k11 = new KoordinateTest<Float>(2.2d, 3.3d); Die Eingabeparameter sind vom Typ double und nicht vom Typ Float
k12 = new KoordinateTest<Double>(2.2d, 3.3d);
k21 = new KoordinateTest<Integer>(2, 3);
//k31 = new Koordinate<String>("11","22"); Nicht erlaubt, da der Typ weiter oben nicht für die Variable erlaubt war
k41 = new KoordinateTest<Number>(2l, 3l);
k41 = new KoordinateTest<Number>(4.4d, 5.5f);
//k11 = new Koordinate<Double>(3.3f,9.9d); Der erste Parameter ist ein Float und nicht ein Double wie gefordert
KoordinateTest<? super Double> k99;
//k99 = k11; Nicht erlaubt, da der Typ weiter oben nicht für die Variable erlaubt war
k99 = k41;
//k99 = k31; Nicht erlaubt, da der Typ weiter oben nicht für die Variable erlaubt war
k11 = k12;
//k12 = k21; k21 ist vom Typ KoordinateTest<Integer>. k12 muss aber vom Typ KoordinateTest<Double> sein
KoordinateTest k55 = new KoordinateTest<Number>(7.7f, 8.8f);
KoordinateTest k66 = new KoordinateTest(7.7f, 8.8f);
}
}- 7214 views
Beispiel: Von einer nicht generischen Klasse zu einer generischen Klasse
Beispiel: Von einer nicht generischen Klasse zu einer generischen KlasseDie Klassen MerkerX implementieren eine Warteschlange der Länge 2. Sie ist in der Lage sich den letzten und den vorletzten Wert zu merken.
Im Folgenden erhalten die Klassen neue Namen (Merker2, Merker3 etc.). Dies erlaubt die Klassen gleichzeitig im Paket zu verwalten
Von Basistypen zu Objekten
Die Klasse Merker1 ist in der Lage Basistypen vom Typ int zu verwalten. Die Werte werden als Teil der Instanzen der Klasse Merker1 verwaltet.
Die Klasse Merker2 verwaltet Objekte vom Typ Integer. Verschiedene Instanzen von Merker2 könne also auf die gleichen Instanzen der Klasse Integer zeigen.
| Klasse Merker1 | Klasse Merker2 |
|---|---|
package Kurs2.Generics; |
package Kurs2.Generics; |
Von Integer-Objekten zur Verwaltung beliebiger Objekte
Die Klasse Merker3 kann nun nicht nur Instanzen der Klasse Integer verwalten. Sie kann beliebige Objekte verwalten.
| Klasse Merker2 | Klasse Merker3 |
|---|---|
package Kurs2.Generics; |
package Kurs2.Generics; |
Von der unsicheren Verwaltung beliebiger Objekte zu einer generischen Klasse
Die Klasse Merker4 ist jetzt generisch. Sie kann typsicher Objekte verwalten. In der main() Methode der Klassse Merker4 wird jedoch diese neue gewonnen Fähigkeit ignoriert. Die Klasse Merker4 wird benutzt wie eine Klasse die beliebige Typen verwalten kann.
| Klasse Merker3 | Klasse Merker4 |
|---|---|
package Kurs2.Generics;
public class Merker3 { |
package Kurs2.Generics;
public class Merker4<T> { |
Typsichere Nutzung der generischen Klasse
Die Klasse Merker5 ist mit Ausnahme der main() Methode identisch zur Klasse Merker4. In der main() Methode der Klassse Merker4 werden jetzt Objekte f1, f2, f3 angelegt die nur die Verwaltung von bestimmten Typen in der Klasse Merker5 erlauben. Da die aktuellen Typen von f1, f2, f3 unterschiedlich sind kann man Sie nicht mehr beliebig aufeinander zuweisen.
| Klasse Merker4 | Klasse Merker5 |
|---|---|
package Kurs2.Generics;
public class Merker4<T> { |
package Kurs2.Generics; |
Die Klassenhierarchie der verschiedenen Varianten der generischen Klasse Merker5:
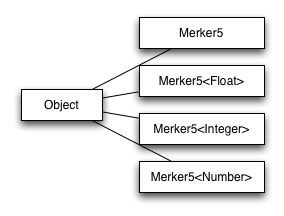
Einschränkung der generischen Klasse Merker6 auf bestimmte Typen
Die Klasse Merker6 verwendet das Schlüsselwort extends um die Verwendung auf zahlenartige Typen (Number) einzuschränken. Die Einschränkungen bei den Zuweisungen zwischen den Variablen f1, f2, und f3 sind zu beachten.
Anbei die Klassen Hierarchie des Java API zur Klasse Number und ihrer Unterklassen:
| Klasse Merker4 | Klasse Merker5 |
|---|---|
package Kurs2.Generics; |
package Kurs2.Generics;
public class Merker6<T extends Number> {
private T letzter;
private T vorletzter; |
Wild Cards
Die Klasse Merker7 benutzt in der main() Methode eine Variable merkeAlles die mit einer Wildcard versehen ist.
Die Variable kann auf alle Varianten der Klasse Merker7 zeigen, sie kann aber nicht alle Methoden nutzen da die Methoden zur Übersetzungszeit nicht bekannt sein müssen.
package Kurs2.Generics;
public class Merker7<T extends Number> {private T letzter;
private T vorletzter;public Merker7() {
letzter = null;
vorletzter = null;
}public T getLetzter() {
return letzter;
}public T getVorLetzter() {
return vorletzter;
}public void merke(T wert) {
vorletzter = letzter;
letzter = wert;
}public String toString() {
return "[" + letzter + ";" + vorletzter + "]";
}public static void main(String[] args) {
// Teil 1: Integer Verwalten
Merker7<Integer> f1 = new Merker7<Integer>();
Integer i10 = 10; // Erzeugung mit Autoboxing
f1.merke(i10);
Integer i11 = new Integer(11); // Reguläre Erzeugung
f1.merke(i11);
Integer i12 = new Integer(12); // Reguläre Erzeugung
f1.merke(i12);
System.out.println(f1);
// Teil 2: Float verwalten
Merker7<Float> f2 = new Merker7<Float>();
Float i20 = 100.1f;
f2.merke(i20);
Float i21 = 101.2f;
f2.merke(i21);
Float i22 = 102.3f;
f2.merke(i22);
System.out.println(f2);
// Teil 3: Alles Verwalten
Merker7<Number> f3 = new Merker7<Number>();
Integer i30 = 200;
f3.merke(i30);
Float i31 = 201.f;
f3.merke(i31);
String i32 = "Zeichenkette";
//f3.merke(i32); // Warum ist dies nicht erlaubt?
System.out.println(f3);
// Teil 4: Alles Verwalten
Merker7 f4 = new Merker7();
Integer i40 = 400;
f4.merke(i40);
Float i41 = 401.f;
f4.merke(i41);
String i42 = "Zeichenkette";
//f4.merke(i42); // Warum ist dies nicht erlaubt?
System.out.println(f4);
f2 = f4;
Merker7<?> merkeAlles;
merkeAlles = f1;
// Hier wird implizit die Methode toString() aufgerufen
System.out.println(merkeAlles);
int m;
// Warum ist diese Zuweisung nicht erlaubt?
//m = merkeAlles.letzter;
// Warum ist diese Zuweisung erlaubt?
m = 3 * f1.letzter;
System.out.println(merkeAlles.letzter);
merkeAlles = f2;
System.out.println(merkeAlles);
merkeAlles = f3;
System.out.println(merkeAlles);
}
}
- 4973 views
Lernziele (Generics)
Lernziele (Generics)|
|
Am Ende dieses Blocks können Sie:
|
Lernzielkontrolle
Sie sind in der Lage die folgenden Fragen zu beantworten: Übungsfragen zu generischen Typen
- 3468 views
Java Collections Framework
Java Collections FrameworkDer Begriff "Collection" wird in Java für alle Klassen verwendet, mit denen man Objekte zusammenfassen und verwalten kann. Die Java-Collections sind Großbehälter die genau gesehen, Referenzen auf Objekte verwalten.
Felder (Arrays) sind ein Teil der Javasprache und erlauben die extrem effiziente Verwaltung von statischen Daten über ihren Feldindex. Felder erlauben nur die Verwaltung von Daten eines genauen Typs mit einer vorher festgelegten Größe. Das Java Collections Framework hat nicht diese Einschränkungen und erlaubt die Verwaltung von Objekten vieler Arten. Das Java Collections Framework ist daher sehr interessant, wenn man vorab nicht weiß wieviele Objekte man verwalten, oder die Objekte nach ganz bestimmten Kriterien verwaltet werden müssen.
Die Klassen im Java Collection Framework implementieren alle gängigen abstrakten Datenstrukturen wie sie in der Vorlesung vorgestellt wurden.
Die Klassen des Java Collection Framework's sind im Paket java.util zu finden. Sie bestehen aus den drei Gruppen:
- Algorithmen: effiziente Algorithmen zur Verwaltung von Objekten
- Implementierungen: Klassenhierarchie mit abstrakten Klassen zur Implementierung eigener Klassen und konkrete Implementierungen zur direkten Benutzung
- Schnittstellen (Interfaces): Hierarchie von Schnittstellen zur einheitlichen Behandlung von Objekten über die Collectionklassen hinweg. Die Interfaces des Collection Frameworks werden hier wie abstrakte Datentypen verwendet.
Generizität
Alle Klassen des Java Collection Framework sind seit JDK 5.0 generische Klassen. Hierdurch können die Klassen sehr viel allgemeiner verwendet werden. Es gibt weniger Situationen in denen man die Klassen selbst spezialisieren muss um Typsicherheit zu gewährleisten.
Die Benutzung generischer Typen hat die folgenden Vorteile:
- Rückgabewerte werden typsicher
- Hierdurch geht die Typinformation der verwalteten Objekte nicht verloren
- Es werden keine expliziten Typkonversionen (Casts) mehr benöigt um beim Auslesen von Objekten diese zuzuweisen.
- 8499 views
Überblick Java Collections
Überblick Java CollectionsDie Klassen des Java Collection Framework in java.util stellen vier Familien von abstrakten Datentypen und Funktionen zur Verfügung:
- Listen (abstrakte Klasse List): geordnete Datenstrukturen auf die man wie auf Felder mit einem numerischen Index zugreifen kann. Im Unterschied zu Feldern (Array) erlauben sie das listentypische Einfügen an einer beliebigen Stelle
- Mengen (abstrakte Klasse Set): Eine Implementierung mathematischer Mengen. Objekte können nur einmal in einer Menge vorkommen. Man kann prüfen ob bestimmte Objekte in einer Menge enthalten sind. Eine Reihenfolge oder Ordnung in der Menge ist nicht relevant.
- Verzeichnisse (abstrakte Klasse Map): Verzeichnisse können als verallgemeinerte Felder angesehen werden. Felder erlauben einen direkten zugriff mit einem numerischen Index. Verzeichnisse erlauben die Wahl einer beliebigen Zugriffskriteriums. Man kann zum Beispiel Personen nach ihrem Nachnamen verwalten und eine Person mit Hilfe eines gegebenen Nachnamens aurufen.
- Warteschlangen (abstrakte Klasse Queue): Warteschlangen sind Listen die nach dem FIFO Prinzip (First In , First Out) aufgebaut sind. Sie verfügen über keinen wahlfreien Zugriff.
Hinzu kommt die Hilfsklasse Arrays zum Verwalten von Feldern. Die Klasse fasst viele nützliche statische Methoden zum Suchen und Sortieren von Feldern zusammen. Die Klasse Arrays gehört zu diesem Paket, da Felder logisch zu den abstrakten Datentypen gehören. Da Felder wegen der benötigten Effizienz ein Hybrid zwischen Basistypen und komplexen Typen sind, passen Sie nicht sauber in die hier vorgestellte Vererbunghierarchie.
Die vier Familien werden durch die folgende Hierarchie von Schnittstellen in Java implementiert:
Jede dieser Familien wird durch eine abstrakte Klasse und eine Schnittstelle implementiert. Die Aufteilung in diese beiden Aspekte findet nach dem folgenden Prinzip statt:
- Schnittstelle: Sie definiert welche Operationen für eine bestimmte Familie erlaubt sind (funktionale Eigenschaft). Diese funktionalen Eigenschaften sind:
- sortiert oder unsortiert
- geordnet oder ungeordnet. Bleibt die Einfügereihenfolge erhalten?
- sequenziell oder wahlfreier Zugriff
- abstrakte Basisklasse: Die abstrakte Klasse implementiert die Schnittstelle und bestimmt damit den Algorithmus, der zu einer bestimmten Effizienz führt.
Zur Auswahl der optimalen Klasse kann man sich an der folgenden Tabelle von Klassen und Eigenschaften orientieren:
| Klasse | Famlie (implem. Schnittst.) | Zugriff | Duplikate erlaubt | Ordnung | Kommentar |
|---|---|---|---|---|---|
| ArrayList | Liste(List) | wahlfrei über Index | Ja | geordnet | effizientes Lesen über Index |
| LinkedList | Liste(List) | wahlfrei über Index | Ja | geordnet | effizientes Einfügen |
| Vector | Liste(List) | wahlfrei über Index | Ja | geordnet | synchronisiert(!) |
| Stack | Liste(List) | sequentiell (letztes Element) | Ja | geordnet | LIFO: Last In First Out |
| HashSet | Menge(Set) | ungeordnet; Test auf Existenz | Nein | ungeordnet | schnelles Lesen, Einfügen, Löschen |
| TreeSet | Menge(Set) | sortiert; Test auf Existenz | Nein | sortiert | |
| LinkedList | Warteschlange(Queue) | sequentiell, Nachfolger | Ja | geordnet | effizientes Einfügen (am Rand) |
| PriorityQueue | Warteschlange(Queue) | sequentiell, Nachfolger | Ja | sortiert | |
| HashMap | Verzeichnis(Map) | wahlfrei über Schlüssel | Keine Schlüsselduplikate, Werteduplikate erlaubt | ungeordnet | effizientes Lesen, Einfügen, Löschen |
| TreeMap | Verzeichnis(Map) | wahlfrei über Schlüssel | Keine Schlüsselduplikate, Werteduplikate erlaubt | sortiert |
In Bezug auf die Spalte Ordnung:
- geordnet: Elemente tauchen beim Iterieren in der gleichen Reihenfolge auf
- sortiert: Elemente tauchen beim Iterieren entsprechend ihre Kardinalität auf.
 |
Frage: Die Klasse LinkedList taucht in der Tabelle zweimal auf. Wieso eigentlich? |
Iteratoren
Neben dem spezifischen Zugriff auf diese abstrakten Datentypen bietet das Java Collection Framework Iteratoren die es Erlauben, nacheinander alle Objekte einer Collection auszulesen. Hierzu dient die Schnittstelle Iterator. Iteratoren werden hier im Detail im Skript vorgestellt.
Beispiel
Im folgenden Beispiel werden Studenten in einer verzeigerten Liste verwaltet. Die Implementierung ist eine nicht generische Verwendung.
| Klasse LinkedListDemo | Klasse Student |
|---|---|
package s2.collection; import java.util.Iterator; /** public static void main(String[] args) { System.out.println("Element auf Index 1:" + ll.get(1)); Iterator<Student> iter = ll.iterator(); System.out.println("Inhalt der Liste:"); |
package s2.collection;
public class Student {
int matrikelnr;
String name;public Student (String n, int nr) { public String toString() {
|
Konsolenausgabe:
Element auf Index 1:(17,Merian Maria-Sybilla, 3) Inhalt der Liste: Student: (19,Curie Marie, 1) Student: (17,Merian Maria-Sybilla, 3) Student: (16,Noether Emmi, 1) Student: (15,Herschel Caroline, 2) Inhalt der Liste: Student: (19,Curie Marie, 1) Student: (17,Merian Maria-Sybilla, 3) Student: (16,Noether Emmi, 1) Student: (15,Herschel Caroline, 2)
In diesem Beispiel wurde eine gängige Technik angewendet:
- Die Variable ll ist vom Schnittstellentyp List.
- Die erzeugte Instanz ist vom Typ LinkedList. LinkedList ist eine spezielle Implementierung die man bei Bedarf gegen eine andere Implementierung austauschen kann ohne die anschließende Verwendung der Variable ll zu modifizieren. Dies würde hier durch die Auswahl der Klasse ArrayList geschehen. Man muss hierzu in der Methode main() nur eine Zeile ändern um das Laufzeitverhalten zu ändern:
List ll = new ArrayList();
- 39951 views
Überbl J-Collections Konsolenausgabe & EIngabe stimm nicht übere
Im Bereich wo die angebliche Konsolenausgabe abgebildet sein sollt, passt das Ergebnis also die Konsolenausgabe weder zu den Eingabe Parametern, noch zu der Klasse und damit Bedingung für die Parameterliste die für "new Student" gilt, da die Signaturen unterschiedlich sind.
In der Klasse Student haben wir eine Signatur Student(String, int)
In der LinkedListIterDemo Klasse haben wir aber eine Signatur von folgender Art Student(String, String, int, int) und in der Konsolenausgabe ist die Signatur Student(int, String, String, int).
- Log in to post comments
Schnittstellen (Interfaces) des Collection Framework
Schnittstellen (Interfaces) des Collection FrameworkZiel des Java Collections Frameworks ist es alle wichtigen abstrakten Datentypen als Schnittstellen für den Entwickler anzubieten.
Der Entwickler soll möglichst nur gegen die Methoden der Schnittstelle implementieren. Dies erlaubt es bei der Objekterzeugung eine optimale Implementierung des entsprechenden Datentyps zu wählen. Aus diesem Grund werden in der Vorlesung die zu benutzenden Schnittstellen immer gemeinsam mit den unterschiedlichen Implementierungen beschrieben. Anbei die Hierachie der Schnittstellen, die aus der gemeinsamen Schnittstelle java.util.Collection abgeleitet werden:
Maps sind sehr komplexe Klassen. Sie werden Aufgrund ihres sehr speziellen Zugriffs mit freigewählten Schlüsseln nicht aus der Klasse java.util.Collection spezialisiert.
Schnittstellen und Implementierungen
Entwickler sollten wann immer möglich gegen die Schnittstellen (z.Bsp. Interface List) implementieren und nicht gegen die Implementierungen ( z.Bsp. Klasse ArrayList, LinkedList). Hierdurch können Sie Implementierung ihres Codes leichter an geänderte Anforderungen anpassen. Sie müssen dann nur bei der Objekterzeugung einen anderen Typ verwenden.
Guter Stil
List meineListe = new ArrayList<String>(); // Später im Code: meineListe.add(0,"DHBW"); meineListe.add(0,"Mannheim"); List neueReferenz = meineListe;
Häufiges Einfügen am Anfang der Liste ist bei einer ArrayList sehr aufwendig. Für den Wechsel der Implementierung muß nur die Erzeugung des Objekts in der ersten Zeile geändert werden:
List meineListe = new LinkedList<String>();
Schlechter Stil
ArrayList meineListe = new ArrayList<String>(); // Später im Code: meineListe.add(0,"DHBW"); meineListe.add(0,"Mannheim"); ArrayList neueReferenz = meineListe;
Wählen Sie als Datentyp List für meineListe, können Sie in der Regel nicht absehen wie diese Referenz später verwendet wird. Es können die folgenden Probleme beim Wechsel der Implementierung auftreten:
- Zuweisungen auf andere Variablen haben Typprobleme (siehe Beispiel)
- Es wurden eventuell Methoden verwendet die es nur in der Implementierung der Klasse ArrayList gab und nicht in der Klasse LinkedList.
- 10215 views
Listen (Collections)
Listen (Collections)Das Java Collections Framework bietet eine Schnittstelle List<E> mit der man uniform auf verschiedene Implementierungen von Listen zugreifen kann.
Listen sind geordnete Folgen die man in der Informatik als Sequenz (engl. sequence) bezeichnet.
Die Schnittstelle List<E> definiert die Methoden mit denen man auf Listen zugreifen kann:
- public void add(int index, E element): fügt ein Element auf einer gegebenen Position ein. Die Nachfolger werden verschoben.
- public E get(int index): wahlfreier Zugriff auf ein Objekt auf eine Postion index
- public E set (int index, E element): wahlfreier schreibender Zugriff auf ein Listenobjekt
- public List<E> sublist(int von, int bis): Erzeugt eine Teilliste im vorgegebenen Intervall
- public E remove(int index): Entfernen eines Objekts von der Position index.
Die Schnittstelle List<E> besitzt noch mehr Methoden als die hier aufgeführten. Sie sind in der API Dokumentation zu finden.
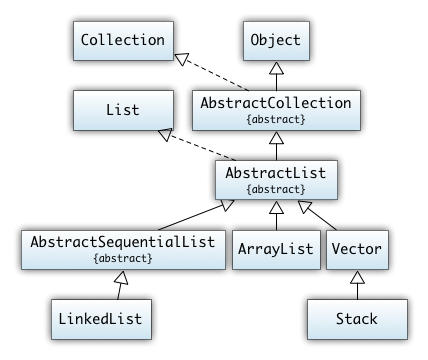
Das Java Collections Framework bietet zwei empfohlene Implementierungen und die Klasse Vector für diese Schnittstelle an, die nach Bedarf gewählt werden können:
Klasse ArrayList
Fie Klasse ArrayList ist im Normalfall die bessere Wahl. Sie verhält sich wie ein Feld (Array). Im Unterschied zu einem Feld kann man die Größe jedoch dynamisch verändern. Die Operationen zum dynamischen Ändern der Größe sind nur in der Klasse ArrayList zu finden. Benutzt man die Schnittstelle List<E> hat man keinen Zugriff auf die zusätzlichen Methoden der Klasse ArrayList .
Die Klasse ArrayList verhält sie weitgehend wie die Klasse Vector. Die Klasse ArrayList ist jedoch nicht synchronisiert.
Eigenschaften:
- Methoden mit einem konstanten Aufwand bei der Ausführung: size(), isEmpty(), get(), set(), iterator(), listIterator()
- Die Methode add() wird im Durchschnitt mit einer konstanten Zeit ausgeführt
- Alle anderen Methoden haben einen linearen Aufwand mit einem niedrigen konstanten Faktor im Vergleich zur Klasse LinkedList.
Klasse Vector
Die Klasse Vector verhält sich wie die Klasse ArrayList . Die Klasse Vector ist historisch älter als das Java Collections Framework. Sie wurde in JDK 1.2 eingeführt und dann später überarbeitet um mit den Schnittstellen des Java Collections Framework konform zu sein. Die Klasse ist daher aus Kompatibilitätsgründen synchronisiert. Hierdurch ist sie zum einen sicher bei der Verwendung bei Anwendungen mit mehreren Threads. Sie ist hierdurch aber auch deutlich langsamer. Die Klasse Vector sollte in neuen Implementierungen zugunsten der Klasse ArrayList vermieden werden.
Klasse LinkedList
Die Klasse LinkedList ist eine Implementierung einer doppelt verzeigerten Liste.
Sie ist sehr gut geeignet für Anwendungen in denen sehr oft Elemente eingefügt oder entnommen werden müssen. Beim indexierten, wahlfreien Zugriff auf ein Objekt muss jedoch die Liste traversiert werden.
Die Klasse LinkedList ist wie die anderen Klassen des Java Collections Frameworks nicht synchronisiert.
- 7410 views
Mengen (Collection)
Mengen (Collection)Das Java Collections Framework stellt mit der Schnittstelle Set<E> einen Behälter zur Verfügung der keine Elemente mehrfach enthält. Die Schnittstelle Set<E> stellt die folgenden Methoden für die unterschiedlichen Implementierungen zur Verfügung:
package java.util;
public interface Set<E> extends Collection<E> {
// Grundlegende Operationen
int size();
boolean isEmpty();
boolean contains(Object element);
boolean add(E element);
boolean remove(Object element);
Iterator<E> iterator();
// Massenoperationen
boolean containsAll(Collection<?> c);
boolean addAll(Collection<? extends E> c);
boolean removeAll(Collection<?> c);
boolean retainAll(Collection<?> c);
void clear();
// Feld Operationen
Object[] toArray();
<T> T[] toArray(T[] a);
}Neben der Schnittstelle Set<E> existiert auch eine Schnittstelle SortedSet<E> in der die Mengenelemente nach ihrer natürlichen oder einer definierten Ordnung sortiert sind.
package package java.util;
public interface SortedSet<E> extends Set<E> {
// Range-view
SortedSet<E> subSet(E fromElement, E toElement);
SortedSet<E> headSet(E toElement);
SortedSet<E> tailSet(E fromElement);
// Endpoints
E first();
E last();
// Comparator access
Comparator<? super E> comparator();
} 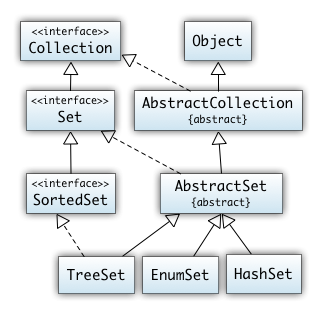
Als konkrete Implementierungen können die folgenden Klassen benutzt werden:
Klasse TreeSet
Die Klasse TreeSet verwaltet alle Elemente in ihrer natürlichen Ordnung oder in der Ordnung die mit der Schnittstelle Comparator definiert wurde.
Die Kosten für die Zugriffsmethoden add(), remove(), contains() liegen bei O(log(n)).
Die Klasse TreeSet ist nicht synchronisiert.
Anwendungsfälle:
- Man muß über die Menge mit einem bestimmten Schlüsselkriterium iterieren können
- Die erhöhten Kosten für Einfügen und Entfernen von Objekten sind nicht relevant.
Klasse EnumSet
Die Klasse EnumSet ist eine Spezialimplementierung für Aufzählungen (enum). Der Aufzählungstyp enum ist extrem effizient mit Hilfe von Bitvektoren implementiert. Die Klasse EnumSet unterstützt extrem effiziente Mengenoperationen auf einem gegegebenen Aufzählungstyp.
Die Iteratoren aller anderen Collections sind "fail safe". Das heißt sie werfen eine ConcurrentModificationException Ausnahme falls die Collection an mehreren Stellen gleichzeitig modifiziert wird. Dies ist nicht der Fall bei den Iteratoren der Klasse EnumSet. Ihre Iteratoren sind nur "weakly consistent" (siehe Dokumentation im API).
Klasse HashSet
Die Klasse HashSet verwendet intern eine Implementierung einer HashMap. Die Klasse HashSet hat keine Ordnung der Elemente. Das bedeutet, dass beim Iterieren über die Menge die Elemente der Menge nicht in einer sortierten Reihenfolge präsentiert werden. Es gibt nicht einmal eine Garantie, dass bei mehrfachem Iterieren über die Menge die Reihenfolge konstant ist.
Der Zugriff der Methoden add(), remove(), contains(), size() haben einen konstanten Aufwand. Diese Operationen sind bei großen Mengen schneller als die Methoden der Klasse TreeSet.
Anwendungsfälle:
- Einfüge-, Entfernungs- und Leseoperationen sollen sehr effizient sein
- Die Ordnung der Menge nach einem Schlüsselkriterium spielt keine Rolle
- 8150 views
Iteratoren
IteratorenIteratoren sind ein universelles Konzept des Java Collections Framework um alle Objekte einer Collection auszulesen. Sie erlauben es Objekte genau einmal aus einer Collection auszulesen und festzustellen ob es noch weitere Elemente gibt.
Iterator ist eine Schnittstelle die drei Methoden für alle Collections anbietet:
- hasNext(): Die Collection hat noch weitere Objekte die ausgelesen werden können
- next(): Liefert das nächste Objekt der Collection
- remove(): entfernt das letzte Objekt welches aus einer Collection gelesen wurde.
Jedes Collectionobjekt ist in der Lage ein Iteratorobjekt mit Hilfe der iterator() Methode anzubieten. Dies kann wie im folgenden Bespiel geschen:
List<Student> ll = new LinkedList<Student>();
... Iterator<Student> iter = ll.iterator();
Beispiel
Der Iterator iter erlaubt über die generische Liste mit Studenten zu iterieren und alle Objekte der Liste auszulesen:
package s2.collection;import java.util.Iterator;
import java.util.LinkedList;
import java.util.List;public class LinkedListIterDemo {
public static void main(String[] args) {
List<Student> ll = new LinkedList<>();
Student s;
s = new Student("Curie","Marie", 19,1);
ll.add(s);
s = new Student("Merian","Maria-Sybilla", 17,3);
ll.add(s);
s = new Student("Noether","Emmi", 16,1);
ll.add(s);
s = new Student("Herschel","Caroline", 15,2);
ll.add(s);
Iterator<Student> iter = ll.iterator();
System.out.println("Inhalt der Liste:");
while (iter.hasNext()){ // Prüfen ob noch Elemente vorhanden sind
s = iter.next(); // Holen des nächsten Listenelements
System.out.println("Student: " +s);
}
}
}
Iterieren mit der erweiterten for-Schleife
Seit JDK 5 kann man auch mit der Syntax der erweiterten for-Schleife über alle Objekte einer Collection iterien.
Der im vorherigen Beispiel vorgestellte Iterator mit der while-Schleife kann sehr elegant mit der erweiterten for-Schleife implementiert werden:
System.out.println("Inhalt der Liste:");
for (Student st : ll)
System.out.println("Student: " +st);
Der Iterator ist hier in die for-Schleife integriert.
Vorsicht: Stabilität von Iteratoren und Collections
Beim Bearbeiten einer Collection mit einem Iterator darf die Collection selbst nicht verändert werden. Operationen mit dem aktuellen Operator sind jedoch als Ausnahme erlaubt. Wird eine Collection beim iterieren verändert so wird eine ConcurrentModifikationException geworfen.
- 6344 views
Verzeichnisse-Maps (Collections)
Verzeichnisse-Maps (Collections)Die Schnittstelle Map im Java Collections Framework erlaubt die Benutzung von Verzeichnissen (engl. Dictionary). Verzeichnisse sind Datenstrukturen in denen man Objekte organisiert nach einem beliebigen Schlüssel verwalten kann. Maps sind Modelle mathematischer Funktionen die einen gegebenen Wert einer Schlüsselmenge auf eine Zielmenge abbilden.
Maps funktionieren wie ein Wörterbuch. Man kann man sie als Tabellen mit zwei Spalten verstehen. In der ersten Spalte steht der Zugriffsschlüssel mit dem man nach einem Objekt sucht, in der zweiten Spalte steht das Objekt welches zu einem gegebenen Schlüssel gehört. Hierdurch werden zwei Objekte in eine Beziehung gesetzt.
Anwendungsbeispiel
In einer Java-Map kann man zum Beispiel Kraftfahrzeuge und deren Halter verwalten. Da ein Kraftfahrzeug genau einen Halter hat, verwendet man das Kraftfahrzeug als Schlüsselobjekt. Die Person die das Fahrzeug besitzt wird als Wert verwaltet. Fügt man dieses Tupel von Schlüsselobjekt und Zielobjekt in die Datenstruktur ein, kann man zu jedem gegebenen Fahrzeug den Halter ausgegeben.
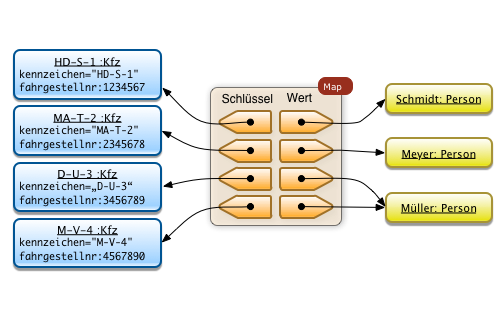
In Java-Maps müssen die Schlüssel eindeutig sein. Jedes Kfz kann daher nur einmal vorkommen. Die verwalteten Werte müssen nicht eindeutig sein. Im Beispiel oben besitzt die Person Müller zwei Kfz.
Abgrenzung zu Objektattributen
Die oben aufgeführten Beispiel benutzte Beziehung zwischen einem Kraftfahrzeug und einem Halter kann man natürlich ebenso gut direkt mit Hilfe von Referenzen in den zwei Klassen modellieren.
Der Vorteil einer Java Map besteht darin, dass man diese Beziehung dynamisch in einem Javaobjekt modelliert und nicht permanent als Objekteigenschaft. Das Verwalten dieser Beziehung in einem Objekt hat die folgenden Vorteile:
- Man kann die Beziehung modellieren ohne die Klassen zu modifizieren
- Man kann jederzeit neue Beziehungen modellieren (z.Bsp Kraftfahrzeug<->Fahrer, Kraftfahrzeug<->Betreuer etc.)
- Man kann zusätzliche Operationen des Java Collection Frameworks ausnutzen um die Daten zu bearbeiten. Man kann z.Bsp.
- über alle Schlüssel iterieren (was ist die Menge der Kraftfahrzeuge?)
- über alle Objekte iterieren (was ist die Menge der Halter? Es kann mehrere Krfatfahrzeuge für einen gegebenen Halter existieren!)
Klassenstruktur
Die Map-Klassen des Java Collections Framework werden nicht wie die anderen Klassen des Frameworks aus der Klasse Collection abgeleitet. Man kann jedoch mit Hilfe der Methoden keySet() und values() über die die Schlüssel oder über die eigentlichen Objekte iterieren.
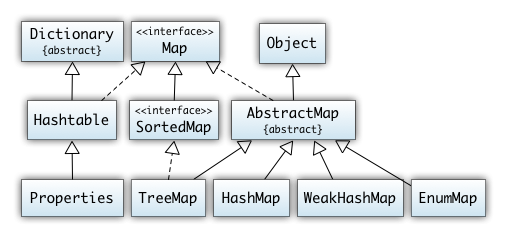
Klasse HashMap
HashMap<K,V> benutzt wie die Klasse HashSet einen Hash-Code für die Schlüssel mit deren Hilfe die Objekte verwaltet werden. Dadurch hat sie auch die gleichen Leistungseigenschafen wie die Klasse HashSet (in Bezug auf die Schlüssel).
Die Klasse HashMap erlaubt es beliebige Klassen als Schlüssel zu verwenden. Die einzige Bedingung ist, dass die Methoden equals() und hashCode() für diese Klassen implementiert sind (triviale Implementierungen existieren bereits in der Klasse Object).
Klasse TreeMap
Die Klasse TreeMap implementiert die Schnittstelle SortedMap. Hierdurch wird sicher gestellt, das Objekte beim Einfügen direkt sortiert eingefügt werden. Die Schlüssel sind also bereits sortiert und erlauben eine effiziente Iteration in der Sortierreihenfolge.
Durch die sortierten Schlüssel ist es zum Beispiel möglich mit Hilfe der Schnittstellenmethoden von SortedMap einen Teilbereich auszuwählen. Ein Verzeichnis welches Zeichketten (Strings) als Schlüssel verwendet kann man z.Bsp. auf die folgende Weise einen Bereich erzeugen der alle Zeichenketten zwischen den Stringvariablen low und high enthält:
SortedMap<String, V> sub = m.subMap(low, high+"\0");
Weitere Klassen
Die Klasse EnumMap erlaubt das Verwalten von Aufzählungstypen (wie auch die Klasse EnumSet).
Die Klasse WeakHashMap erlaubt die Verwaltung schwacher Referenzen. Schwach referenzierte Objekte können in Java bei Bedarf vom Garbage Collector gelöscht werden. Sie benötigen daher eine gewisse Sonderbehandlung.
Beide Klassen werden im Rahmen der Vorlesung nicht weiter behandelt.
Ausgewählte Methoden für Maps
Die Schnittstelle Map hat sehr viele Methoden, die man am besten in der Online API Dokumentation nachliest. Die wichtigsten Methoden werden hier kurz vorgestellt:
Konstruktor
Die Konstruktoren sind nicht Teil der Schnittstelle. Sie hängen von den individuellen Ausprägungen ab. Anbei zwei Beispiele zum Erzeugen von Map-objekten wie sie im Beispiel oben gezeigt wurden:
import java.util.HashMap; import java.util.TreeMap; import Person; import Kfz; Map<Kfz,Person> halterMapsortiert = new TreeMap<Kfz,Person>(); Map<Kfz,Person> halterMapunsortiert = new HashMap<Kfz,Person>();
Hinzufügen: put(K key, V value)
Tupel von Schlüsseln und Werten können mit der put(K key,V value) Methode hinzugefügt werden. Zwei Tupel für das obige Beispiel werden mit der folgenden Syntax eingefügt:
Person p = new Person("Müller");
Kfz wagen1 = new Kfz("D-U-3",3456789);
Kfz wagen2 = new Kfz("M-V-4",4567890);
halterMapsortiert.put(wagen1,p);
halterMapsortiert.put(wagen2,p);
Methode get(Object key): Auslesen eines Wertes zu einem gegebenen Schlüssel
Die "klassische" Verzeichnisoperation ist das Auslesen eines Wertes zu einem gegebenen Schlüssel. Hierzu dient die get(Object key) Methode. Im obigen Beispiel kann man die Person "Müller" finden wenn man eines der Fahrzeuge dieser Person kennt. Die geschieht mit der folgenden Syntax:
Person p = halterMapsortiert.get(wagen2);
Methode keySet(): Auslesen alle Schlüsselelemente
|
Java-Maps erlauben auch das Auslesen aller Schlüssel mit der Methode keySet(). Man kann sich im obigen Beispiel die Menge (Javatyp Set) aller Kfz-objekte dem folgenden Kommando auslesen: Set<Kfz> KfzSet = halterMapsortiert.keySet(); Die neu erzeugte Menge zeigt auf die gleichen Schlüsselobjekte wie die Map: Zum Auslesen der Mengenelemente muss man dann einen Mengeniterator anwenden. |
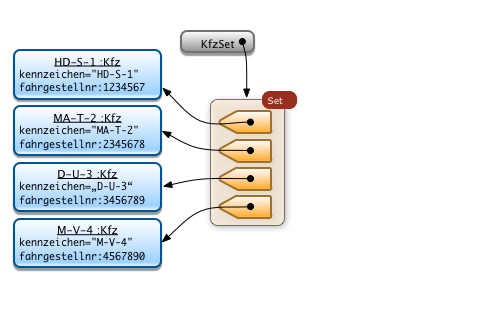 |
Methode values(): Auslesen aller Werte
Die Werte der Map werden mit der Methode values() ausgelesen. Im Beispiel von oben würde man die Werte der Map mit dem folgenden Befehl auslesen:
Person p;
Collection<Person> personColl = halterMapsortiert.values();
Iterator<Person> iterPerson = personColl.iterator();
while (iterPerson.hasNext()) {
p = iterPerson.next();
System.out.println("Person: " + p);
}
Die zurückgebene Datenstruktur hat den Typ Collection. Der genaue Typ der Collection hängt von der gewählten Mapimplementierung ab. |
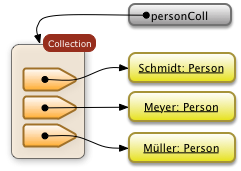 |
Weiterführende Quellen
- 9665 views
Warteschlangen (Collections)
Warteschlangen (Collections)Das Java Collections Framework besitzt Klassen zur Implementierung von Warteschlangen (engl. Queue).
Die Warteschlangen implementieren das FIFO Prinzip (First In, First Out). Warteschlangen werden oft zur Kommunikation zwischen Threads verwendet. Ein weitere typischer Anwendungsfall ist das Verwalten von Alarmnachrichten.
Da Alarmnachrichten eventuell mit unterschiedlichen Prioritäten verwaltet werden müssen erlauben es die Klassen des Java Collections Frameworks Objekten unterschiedliche Prioritäten zuzuweisen. Innerhalb einer Priorität gilt dann wieder das FIFO Prinzip.
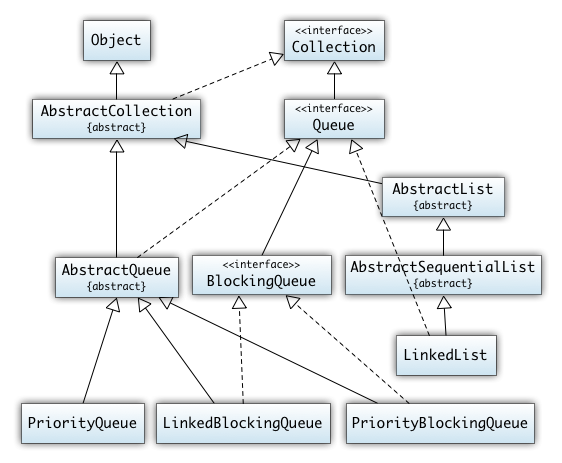
Einfache Warteschlangen
Einfache Warteschlangen implementieren die Schnittstelle Queue:
package java.util; public interface Queue<E> extends Collection<E> {
E element();
boolean offer(E e);
E peek();
E poll();
E remove();
}
- offer(): Erlaubt das Einfügen in eine Warteschlange. Sie gibt den Wert false zurück wenn die Warteschlange ihre maximale Kapazität erreicht hat
- peek(): Liefert das nächste Element es wird jedoch nicht entfernt
- element(): Identisch zur Methode peek()
- poll(): Entfernt das nächste Element der Warteschlange und gibt es zurück
- remove(): Identisch zur Methode poll(). wirft jedoch eine Ausnahme NoSuchElementException falls die Warteschlange leer ist.
Hinweis: Die Klasse LinkedList implementiert die Queue Schnittstelle. Sie ist somit in der Lage sich wie eine Warteschlange zu verhalten.
Priorisierte Warteschlangen: Klasse PriorityQueue
Die Klasse PriorityQueue benutzt zur Priorisierung von Objekten deren Sortierkriterium die entweder durch die Schnittstelle Comparable<E> oder durch ein spezielles Vergleichsobjekt der Klasse Comparator<E> implementiert wird.
Blockierende Warteschlangen: Schnittstelle BlockingQueue<E>
Es gibt Fälle in denen der Produzent und der Konsument unabhängig voneinander arbeiten und der Produzent nicht in der Lage ist, die Warteschlange immer mit Objekten gefüllt zu halten. Das Gegenteil ist genauso möglich. Ein Konsument ist nicht in der Lage die Warteschlange schnell genug auszulesen. In den beiden Fällen einer leeren, sowie er vollen Warteschlange erlaubt die Schnittstelle BlockingQueue dem Produzenten oder dem Konsumenten eine bestimmte Zeit zu warten. Die Schnittstelle fordert die Implementierung der Einfüge-, Lese- und Entfernmethoden mit Angabe eines Zeitintervalls für das der Thread warten sollen:
Die Klasse LinkedBlockingQueue implementiert diese Schnittstelle.
Priorisierte und blockierende Warteschlangen: Klasse PriorityBlockingQueue
Die Klasse PriorityBlockingQueue vereint die beiden Eigenschaften einer priorisierten und blockierenden Warteschlange.
Weitere Informationen
- 6805 views
Übungen (Collections)
Übungen (Collections)Fragen
Was sind günstige, bzw. ungünstige Anwendungsszenarien für die folgenden Klassen des Java Collection Frameworks?
- LinkedList
- ArrayList
- TreeSet
- HashSet
Klasse Student
Die Übungen dieser Seite verwenden die Klasse Student. Studenten haben eine Matrikelnummer, einen Vornamen, einen Nachnamen und eine aktuelles Semester. Für die Klasse wurden alle Methoden zum Vergleichen überladen. Zwei Studenten sind identisch wenn sie die gleiche Matrikelnummer besitzen.
package s2.collection;
public class Student implements Comparable {
int matrikelnr;
String name;
String vorname;
int semester;
public Student(String n, String vn, int nr, int sem) {
name = n;
vorname = vn;
matrikelnr = nr;
semester = sem;
}
public String toString() {
return "(" + matrikelnr + "," + name + " " + vorname
+ ", " + semester + ")";
}
/**
* Studenten werden anhand Ihre Matrikelnr verglichen
* @param o
* @return
*/
public int compareTo(Object o) {
int diff = 0;
if (o.getClass() == getClass()) {
diff = matrikelnr - ((Student) o).matrikelnr;
}
if (diff > 0) {
diff = 1;
}
if (diff < 0) {
diff = -1;
}
return diff;
}
public boolean equals(Object o) {
return (compareTo(o) == 0);
}
public int hashCode() {
return matrikelnr;
}
}Mengen von Studenten
Das Programm soll eine Menge von Studenten verwalten. Vervollständigen Sie das das folgende Programm:
- main() Methode
- Setzen Sie die Objekterzeugung für die Variablen mengeUnsortiert und mengeSortiert ein
- Fügen Sie alle Studenten in beide Mengen ein indem Sie die Platzhalter-Konsolenausgaben ersetzen
- ausgaben() Methode: Iterator über eine Menge implementieren
- Deklarieren und initialisieren Sie ein Iteratorobjekt für das Listenobjekt welches als Parameter übergeben wurde
- Implementieren Sie korrekte Abbruchbedingung für die while-Schleife
- Implementieren die while-Schleife. Weisen Sie der Variablen s einen jeweils neuen Student der Menge zu
Beobachtungen:
- Welche der beiden Mengen ist sortiert?
- Welche Mengenimplementierungen nutzen Sie für welche Aufgabenstellung?
- Was geschieht mit Caroline Herschel?
package s2.collection;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
import java.util.TreeSet;
public class SetIterDemo {
public static void main(String[] args) {
Set<Student> mengeUnsortiert = null; // Hier HashSetobjekt einfügen
Set<Student> mengeSortiert = null; // Hier TreeSetobjekt einfügen
Student s;
s = new Student("Curie", "Marie", 19, 1);
System.out.println("Hier Student " + s + "in beide Mengen einfügen");
s = new Student("Merian", "Maria-Sybilla", 17, 3);
System.out.println("Hier Student " + s + "in beide Mengen einfügen");
s = new Student("Noether", "Emmi", 16, 1);
System.out.println("Hier Student " + s + "in beide Mengen einfügen");
s = new Student("Liese", "Meitner", 15, 2);
System.out.println("Hier Student " + s + "in beide Mengen einfügen");
s = new Student("Herschel", "Caroline", 15, 2);
System.out.println("Hier Student " + s + "in beide Mengen einfügen");
ausgaben(mengeUnsortiert);
ausgaben(mengeSortiert);
}
public static void ausgaben(Set<Student> menge) {
Student s;
System.out.println("Hier Iterator deklarieren");
System.out.println("Inhalt der Menge ("
+ menge.getClass() + "):"); // Nicht ersetzen
while (true) { // Abbruchbedingung ersetzen. Die Schleife terminiert so nicht!
System.out.println("Hier Student aus Iterator in Schleife auslesen");
s = null;
System.out.println("Student: " + s); // Nicht ersetzen
}
}
} // Ende der KlasseMaps von Studenten
- main() Methode
- Setzen die die Objekterzeugung für die Variablen matrikelMap und nachName ein (In den beiden Kommentarzeilen)
- matrikelMap soll als Schlüssel die Matrikelnummer des Studenten verwenden, der Inhalt soll aus Studenten bestehen
- nachnameMap soll als Schlüssel den Nachnamen des Studenten verwenden, der Inhalt soll aus Studenten bestehen
- Welche Typen müssen für die Platzhalter xxx? bei der Variablen und dem Map-Parameter eingesetzt werden?
- Fügen Sie alle Studenten in beide Mengen ein indem Sie die Platzhalter-Konsolenausgaben ersetzen
- Setzen die die Objekterzeugung für die Variablen matrikelMap und nachName ein (In den beiden Kommentarzeilen)
- ausgabenMatrikelnr() Methode:
- Iterieren Sie über die Matrikelnummern. Die Matrikelnummern sind die Schlüssel der Map mp
- Legen Sie einen Iterator an;
- Definieren Sie die Abbruchbedingung für die while Schleife
- Lesen Sie die nächste Matrikelnummer in der while Schleife aus (Variable s)
- Finden Sie die Studenten zur Matrikelnummern 15 und 16.
- Iterieren Sie über die Studenten. Die Studenten sind die eigentlichen Objekte der Map mp
- Legen Sie einen Iterator an;
- Definieren Sie die Abbruchbedingung für die while Schleife
- Lesen Sie die nächste Matrikelnummer in der while Schleife aus (Variable st)
- Iterieren Sie über die Matrikelnummern. Die Matrikelnummern sind die Schlüssel der Map mp
- ausgabenNamen() Methode:
- Iterieren Sie über die Nachnamen. Die Nachnamen sind die Schlüssel der Map mp
- Legen Sie einen Iterator an;
- Definieren Sie die Abbruchbedingung für die while Schleife
- Lesen Sie den nächsten Nachnamen in der while Schleife aus (Variable str)
- Finden Sie die Studenten mit den Namen Herschel und Merian.
- Iterieren Sie über die Studenten. Die Studenten sind die eigentlichen Objekte der Map mp
- Legen Sie einen Iterator an;
- Definieren Sie die Abbruchbedingung für die while Schleife
- Lesen Sie die nächste Matrikelnummer in der while Schleife aus (Variable st)
- Iterieren Sie über die Nachnamen. Die Nachnamen sind die Schlüssel der Map mp
- Welche der beiden Maps ist sortiert?
- Sind die Schlüssel sortiert?
package s2.collection;
import java.util.Collection;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
import java.util.TreeMap;
public class MapIterDemo {
public static void main(String[] args) {
Map<xxx?,Student> matrikelMap = new TreeMap<xxx?,Student>(); // Ersetzen Sie xxx?
Map<xxx?, Student> nachnameMap = new HashMap<xxx?,Student>();// Ersetzen Sie xxx?
Student s;
s = new Student("Curie", "Marie", 19, 1);
System.out.println("Einsetzen: Studenten "+ s + " in die beiden Maps eintragen. Schlüssel beachten!");
s = new Student("Merian", "Maria-Sybilla", 17, 3);
System.out.println("Einsetzen: Studenten "+ s + " in die beiden Maps eintragen. Schlüssel beachten!");
s = new Student("Noether", "Emmi", 16, 1);
System.out.println("Einsetzen: Studenten "+ s + " in die beiden Maps eintragen. Schlüssel beachten!");
s = new Student("Meitner", "Liese", 15, 2);
System.out.println("Einsetzen: Studenten "+ s + " in die beiden Maps eintragen. Schlüssel beachten!");
s = new Student("Herschel", "Caroline", 20, 2);
System.out.println("Einsetzen: Studenten "+ s + " in die beiden Maps eintragen. Schlüssel beachten!");
ausgabenMatrikelnr(matrikelMap);
ausgabenNamen(nachnameMap);
}
public static void ausgabenMatrikelnr(Map<Integer,Student> mp) {
int s;
Student st;
System.out.println("Einsetzen: Vorbereitungen zum Auslesen der Matrikelnr");
Iterator<Integer> iterMatrikel = null; // Einsetzen: Zuweisen des Iterators
System.out.println("Name ("
+ mp.getClass() + "):");
while (null) { // Einsetzen: Iteratorbedingung einfügen
s = null // Einsetzen: Auslesen des Iterators
System.out.println("Matrikelnummer: " + s);
}
int mnr = 15;
System.out.println("Student mit Matrikelnummer " + mnr +
" ist:" + null); // Einsetzen: Student mit Matrikelnr mnr
mnr = 16;
System.out.println("Student mit Matrikelnummer " + mnr +
" ist:" + null ); // Einsetzen: Student mit Matrikelnr mnr
System.out.println("Alle Werte der MatrikelMap:");
Collection<Student> l = null; // Einsetzen: Collection mit den Studenten
Iterator<Student> iterStudi = l.iterator();
System.out.println("Name ("
+ mp.getClass() + "):");
while (null) { // Einsetzen: Schleifenbedingung des Iterators
// Einsetzen: Auslesen des nächsten Studenten
System.out.println("Student: " + st);
}
}
public static void ausgabenNamen(Map<String,Student> mp) {
String str;
Student st;
System.out.println("Einsetzen: Vorbereitungen zum Auslesen der Nachnamen");
System.out.println("Namen ("
+ mp.getClass() + "):");
while (null) { // Einsetzen: Iteratorbedingung einfügen
str = null// Einsetzen: Auslesen des Iterators
System.out.println("Nachname: " + str);
}
String nme = "Merian";
System.out.println("Student mit Name " + nme +
" ist:" + null); // Einsetzen der Operation zum Auslesen der Studentin mit Namen nme
nme = "Herschel";
System.out.println("Student mit Name " + nme +
" ist:" + + null); // Einsetzen der Operation zum Auslesen der Studentin mit Namen nme
System.out.println("Alle Werte der NamenMap:");
Collection<Student> l = null; // Einsetzen: Auslesen der gesamten Collection
Iterator<Student> iterStudi = l.iterator();
System.out.println("Name ("
+ mp.getClass() + "):");
while (null) { // Einsetzen: Iteratorbedingung einfügen
st = null// Einsetzen: Auslesen des Iterators
System.out.println("Student: " + st);
}
}
}- 10548 views
Lösungen (Collections)
Lösungen (Collections)Antworten zu den Fragen
| Klasse | Günstig | Ungünstig |
|---|---|---|
| LinkedList |
|
|
| ArrayList |
|
|
| TreeSet |
|
|
| HashSet |
|
|
Mengen von Studenten
package s2.collection;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
import java.util.TreeSet;
public class SetIterDemo {
public static void main(String[] args) {
Set<Student> mengeUnsortiert = new HashSet<Student>();
Set<Student> mengeSortiert = new TreeSet<Student>();
Student s;
s = new Student("Curie", "Marie", 19, 1);
mengeUnsortiert.add(s);
mengeSortiert.add(s);
s = new Student("Merian", "Maria-Sybilla", 17, 3);
mengeUnsortiert.add(s);
mengeSortiert.add(s);
s = new Student("Noether", "Emmi", 16, 1);
mengeUnsortiert.add(s);
mengeSortiert.add(s);
s = new Student("Meitner","Liese", 15, 2);
mengeUnsortiert.add(s);
mengeSortiert.add(s);
s = new Student("Herschel", "Caroline", 15, 2);
mengeUnsortiert.add(s);
mengeSortiert.add(s);
ausgaben(mengeUnsortiert);
ausgaben(mengeSortiert);
}
public static void ausgaben(Set<Student> menge) {
Student s;
Iterator<Student> iter = menge.iterator();
System.out.println("Inhalt der Menge ("
+ menge.getClass() + "):");
while (iter.hasNext()) {
s = iter.next();
System.out.println("Student: " + s);
}
}
}
Konsolenausgaben
Inhalt der Menge (class java.util.HashSet): Student: (17,Merian Maria-Sybilla, 3) Student: (16,Noether Emmi, 1) Student: (19,Curie Marie, 1) Student: (15,Meitner Liese, 2) Inhalt der Menge (class java.util.TreeSet): Student: (15,Meitner Liese, 2) Student: (16,Noether Emmi, 1) Student: (17,Merian Maria-Sybilla, 3) Student: (19,Curie Marie, 1)
Maps von Studenten
package s2.collection;
import java.util.Collection;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
import java.util.TreeMap;
public class MapIterDemo {
public static void main(String[] args) {
Map<Integer,Student> matrikelMap = new TreeMap<Integer,Student>();
Map<String, Student> nachnameMap = new HashMap<String,Student>();
Student s;
s = new Student("Curie", "Marie", 19, 1);
matrikelMap.put(s.matrikelnr,s);
nachnameMap.put(s.name,s);
s = new Student("Merian", "Maria-Sybilla", 17, 3);
matrikelMap.put(s.matrikelnr,s);
nachnameMap.put(s.name,s);
s = new Student("Noether", "Emmi", 16, 1);
matrikelMap.put(s.matrikelnr,s);
nachnameMap.put(s.name,s);
s = new Student("Meitner", "Liese", 15, 2);
matrikelMap.put(s.matrikelnr,s);
nachnameMap.put(s.name,s);
s = new Student("Herschel", "Caroline", 20, 2);
matrikelMap.put(s.matrikelnr,s);
nachnameMap.put(s.name,s);
ausgabenMatrikelnr(matrikelMap);
ausgabenNamen(nachnameMap);
}
public static void ausgabenMatrikelnr(Map<Integer,Student> mp) {
int s;
Student st;
Set<Integer> matrikelSet = mp.keySet();
Iterator<Integer> iterMatrikel = matrikelSet.iterator();
System.out.println("Name ("
+ mp.getClass() + "):");
while (iterMatrikel.hasNext()) {
s = iterMatrikel.next();
System.out.println("Matrikelnummer: " + s);
}
int mnr = 15;
System.out.println("Student mit Matrikelnummer " + mnr +
" ist:" +mp.get(mnr));
mnr = 16;
System.out.println("Student mit Matrikelnummer " + mnr +
" ist:" +mp.get(mnr));
System.out.println("Alle Werte der MatrikelMap:");
Collection<Student> l = mp.values();
Iterator<Student> iterStudi = l.iterator();
System.out.println("Name ("
+ mp.getClass() + "):");
while (iterStudi.hasNext()) {
st = iterStudi.next();
System.out.println("Student: " + st);
}
}
public static void ausgabenNamen(Map<String,Student> mp) {
String str;
Student st;
Set<String> nameSet = mp.keySet();
Iterator<String> iterName = nameSet.iterator();
System.out.println("Namen ("
+ mp.getClass() + "):");
while (iterName.hasNext()) {
str = iterName.next();
System.out.println("Familienname: " + str);
}
String nme = "Merian";
System.out.println("Student mit Name " + nme +
" ist:" +mp.get(nme));
nme = "Herschel";
System.out.println("Student mit Name " + nme +
" ist:" +mp.get(nme));
System.out.println("Alle Werte der NamenMap:");
Collection<Student> l = mp.values();
Iterator<Student> iterStudi = l.iterator();
System.out.println("Student: ("
+ mp.getClass() + "):");
while (iterStudi.hasNext()) {
st = iterStudi.next();
System.out.println("Student: " + st);
}
}
}
Konsolenausgabe
Name (class java.util.TreeMap): Matrikelnummer: 15 Matrikelnummer: 16 Matrikelnummer: 17 Matrikelnummer: 19 Matrikelnummer: 20 Student mit Matrikelnummer 15 ist:(15,Meitner Liese, 2) Student mit Matrikelnummer 16 ist:(16,Noether Emmi, 1) Alle Werte der MatrikelMap: Name (class java.util.TreeMap): Student: (15,Meitner Liese, 2) Student: (16,Noether Emmi, 1) Student: (17,Merian Maria-Sybilla, 3) Student: (19,Curie Marie, 1) Student: (20,Herschel Caroline, 2) Namen (class java.util.HashMap): Matrikelnummer: Meitner Matrikelnummer: Curie Matrikelnummer: Herschel Matrikelnummer: Noether Matrikelnummer: Merian Student mit Name Merian ist:(17,Merian Maria-Sybilla, 3) Student mit Name Herschel ist:(20,Herschel Caroline, 2) Alle Werte der NamenMap: Name (class java.util.HashMap): Student: (15,Meitner Liese, 2) Student: (19,Curie Marie, 1) Student: (20,Herschel Caroline, 2) Student: (16,Noether Emmi, 1) Student: (17,Merian Maria-Sybilla, 3)
- 7074 views
Lernziele (Java Collections)
Lernziele (Java Collections)|
|
Am Ende dieses Blocks können Sie:
|
Lernzielkontrolle
Sie sind in der Lage die folgenden Fragen zu beantworten: Fragen zu Collections
- 3535 views
Ein- und Ausgabe über Streams
Ein- und Ausgabe über Streams
 |
Programme müssen Daten von unterschiedlichen Datenquellen lesen können und sie müssen Daten auf unterschiedliche Datenziele schreiben können. Hierbei kann es sich um die unterschiedlichsten Quellen und Ziele handeln:
|
Alle Ein- und Ausgaben in Java laufen "stromorientiert" ab, sie folgen dem "Stream-Konzept".
|
Ein Stream ist die Verbindung zwischen einer Datenquelle und einem Datenziel. Die Verbindung erfolgt immer in nur eine Richtung (von der Quelle zum Ziel). |
Um Eingaben in Java zu erhalten muß man einen Strom öffnen der mit einer Datenquelle verbunden ist und anschließend die Daten sequentiel lesen.
Für Ausgaben muß man einen Datenstrom zu einem Datenziel öffnen, dann die Daten sequentiell schreiben.
Dieses Konzept ist einem Wasserschlauch ähnlich: Sie benötigen jemand der das Wasser einspeißt und einen anderen Konsumenten der das Wasser wieder entnimmt.
Kategorien von Streams
In Java werden zwei Kategorien unterschieden:
- Character-Streams: Transportieren 16 Bit Daten. Sie arbeiten mit dem Javatyp char der Unicodezeichen darstellt
- Byte-Stream: Transportieren 8 Bit Daten. Sie arbeiten mit dem Javatyp byte.
- Ihre Basisfunktionalität wird durch die abstrakten Klassen InputStream und OutputStream bereitgestellt.
Wichtig: Alle Klassen die von diesen vier Basisklassen spezialisiert werden haben als Endung den Namen der abstrakten Klasse!
Bsp.: Bei der Klasse FileWriter handelt handelt es sich um einen Ausgabestrom auf Dateien.
 |
Bsp.: Bei der Klasse FileWriter handelt handelt es sich um einen Ausgabestrom auf Dateien. Frage: Verwaltet er Bytes oder Zeichen? |
Interessant:Man kann Streams (Datenströme) verketten! Das bedeutet, dass ein Streamsobjekt in der Regel einen anderen Stream als Eingabe oder Ausgabe akzeptiert. Hiermit kann man Datenströme elegant umkonvertieren. |
 |
java.nio und mehr...
 |
Seit der Version JDK 1.4 gibt es in Java das Paket java.nio mit einer Reihe neuer Klassen. Diese Paket ist nicht Gegenstand der Vorlesung. In diesem Abschnitt werden nur einige wenige, ausgewählte Methoden der Klassen vorgestellt. Bitte benutzen Sie die Hyperlinks zur Java API Dokumention und einen vollständigen Überblick zu bekommen. |
- 1880 views
Die Klasse File
Die Klasse FileViele Operationen werden auf Dateien ausgeführt. Die Klasse File im Paket java.io erlaubt das manipulieren von Dateien und Verzeichnissen.
Im Beispiel der Klasse s2.io.DateiTest (github) kann man sehen wie man Verzeichnisse anlegt und ausliest und neue Dateien anlegt. Methoden zum Manipulieren und Auslesen von Dateiattributen sind in der Java Dokumentation zur Klasse File beschrieben.
package s2.io;
/**
* @author s@scalingbits.com
*/
import java.io.File;
import java.io.IOException;
public class DateiTest {
/**
* Hauptprogamm
* @param args wird nicht verwendet...
*/
public static void main(String[] args) {
String d ="testDir";
String f1 = "datei1.txt";
String f2 = "datei2.txt";
File dir = new File(d);
File file1 = new File(d + "/" + f1);
File file2 = new File(d + "/" + f2);
if (dir.exists())
System.out.println("Verzeichnis " + d + " existiert bereits");
else
dir.mkdir();
try {
file1.createNewFile();
System.out.println("Datei wurde angelegt in : "
+ file1.getAbsolutePath() );
file2.createNewFile();
System.out.println("Datei wurde angelegt in : "
+ file2.getAbsolutePath() );
System.out.println("Dateien im Verzeichnis "
+ dir.getAbsolutePath());
String[] alleDateien = dir.list();
for ( String f : alleDateien)
System.out.println("* " + f);
} catch (IOException ex) {
System.out.println("Probleme im IO Subsystem. Scotty beam me up!");
}
}
} |
Übung: Erweitern Sie Anwendung so, dass die Dateien und das Verzeichnis wieder gelöscht werden! Frage: Welche Methoden brauche ich hierfür? Sie werden doch nicht auf diesen Hyperlink klicken: github s2.io.DateiTestLoesung.java |
- 1081 views
Einführung in Reader- und Writerklassen
Einführung in Reader- und WriterklassenDie Reader und Writer Klassen in Java erlauben es Zeichen-Stöme zu verwalten.
Die spezialisierten Klassen FileReader und FileWriter haben Konstruktoren in denen man als Quelle bzw. Ziel eine Datei angeben kann:
Ihre Oberklassen InputStreamReader und OutputStreamWriter haben Konstruktoren die die Konvertierung von Streams erlauben.
Hiermit kann man einen Byte-Stream (inputStream) in einen Zeichen-Stream (Reader) verwandeln. Dies ist nützlich wenn man eine Binärdatei (Byte-Stream) in eine Datei (Zeichen-Stream) schreiben möchte.
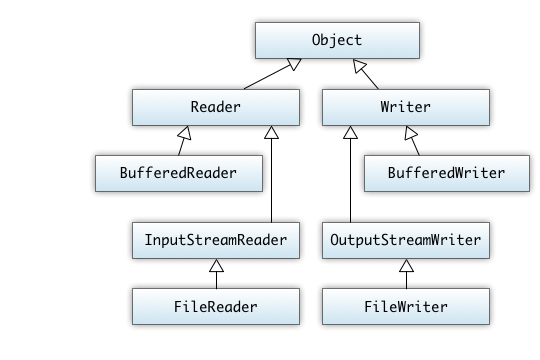
Im folgenden Beispiel wird gezeigt wie man einen Zeichen-Stream von der Konsole lesen kann und ihn dann in eine Datei schreibt. Die Java Klasse System bietet mit dem Attribute System.in Zugriff auf einen InputStream mit Konsoleneingaben und auf Konsolenausgaben (System.out).
/*
* Ein Beispielprogramm welches von der Konsole liest und in eine Datei schreibt
*/
package s2.io;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.Reader;
import java.io.Writer;
/**
*
* @author s@scalingbits.com
*/
public class SchreibInDatei {
/**
* Hauptprogamm
* @param args wird nicht verwendet...
*/
public static void main(String[] args) {
try {
String f = "scalingbits.txt";
File datei = new File(f);
Reader rein = new InputStreamReader(System.in);
Writer raus = new FileWriter(datei);
System.out.println("Der Text der jetzt eingegeben wird, wird in " +
"der Datei " + f + " gespeichert");
System.out.println("Abschliessen mit Strg-Z oder Ctrl-Z");
System.out.println("Abschliessen Auf Unix/Linux mit Ctrl-D");
System.out.println("Abschliessen auf Mac mit IntelliJ mit Cmd-D");
umkopieren(rein,raus);
} catch (IOException ex) {
System.out.println("Probleme im IO Subsystem. Scotty beam me up");
}
}
/**
* Umkopieren zwischen zwei Streams
* @param r Eingabestream
* @param w Ausgabestream
* @throws IOException
*/
public static void umkopieren(Reader r, Writer w) throws IOException{
int c;
while ((c= r.read()) != -1 ) {
w.write(c);
}
r.close();
w.close();
}
}
|
Übung: Erweitern Sie Anwendung so, dass sie die geschriebene Datei wieder ausliest und auf der Konsole druckt. Die Methoden umkopieren() kann man wiederverwenden... Frage: Welche Klassen brauche ich hierfür? Sie werden doch nicht auf diesen Hyperlink klicken: github s2.io.SchreibInDateiLoesung.java |
Gepufferte Reader- und Writer Klassen
Das Lesen bzw. Schreiben einzelner Bytes oder Zeichen vom Netzwerk oder von Dateien ist oft sehr ineffizient. Zum effizienteren Behandlung größerer Datenmengen stellt Java die Klassen BufferedReader und BufferedWriter zur Verfügung. Diese Klassen speichen die Daten zwischenzeitlich in einem Puffer und Lesen bzw. Schreiben die Daten in größeren Blöcken. Diese gepufferten Klassen müssen mit den elementaren Klassen verkettet werden. Deshalb haben sie die folgenden Konstruktoren:
- public BufferedReader(Reader in): zur Erzeugung eines gepufferten Stroms zum Lesen
- public BufferedWriter(Writer out): zur Erzeugung eines gepufferten Stroms zum Schreiben
Sie Verfügen über zusatzliche Methoden zum gepufferten Lesen und Schreiben
- BufferedReader.readLine(): Liest eine Textzeile bis zum nächsten Zeilenumbruch ('\n' oder '\r')
- BufferedWriter.newLine(): Schreibt einen Zeilenwechsel in den Puffer.
Nutzt man diese Klassen im Beispiel, gibt es eine Reihe von Veränderungen:
- mit BufferedReader.readLine() erhält man eine Zeichenkette als Ergebnis (oder einen Nullzeiger!)
- man sollte beim Schreiben den Zeilenimbruch selbst einfügen
Die Klasse SchreibInDateiGepuffered
/*
* Eins Beispielprogramm welches von der Konsole liest und in eine Datei schreibt
*/
package s2.io;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
/**
*
* @author s@scalingbits.com
*/
public class SchreibInDateiGepuffered {
/**
* Hauptprogamm
* @param args wird nicht verwendet...
*/
public static void main(String[] args) {
try {
String f = "scalingbits.txt";
File datei = new File(f);
BufferedReader rein = new BufferedReader(
new InputStreamReader(System.in));
BufferedWriter raus = new BufferedWriter(
new FileWriter(datei));
System.out.println("Der Text der jetzt eingegeben wird, wird in " +
"der Datei " + f + " gespeichert");
System.out.println("Abschliessen mit Strg-Z oder Ctrl-Z");
System.out.println("Abschliessen Auf Unix/Linux mit Ctrl-D");
System.out.println("Abschliessen auf Mac mit IntelliJ mit Cmd-D");
umkopieren(rein,raus);
rein = new BufferedReader(
new FileReader(f));
raus = new BufferedWriter(
new OutputStreamWriter(System.out));
System.out.println("Ausgabe des in Datei " + f
+ " gespeichertem Texts");
umkopieren(rein,raus);
} catch (IOException ex) {
System.out.println("Probleme im IO Subsystem. Scotty beam me up");
}
}
/**
* Umkopieren zwischen zwei Streams
* @param r Eingabestream
* @param w Ausgabestream
* @throws IOException
*/
public static void umkopieren(BufferedReader r, BufferedWriter w) throws IOException{
String z;
while ((z= r.readLine()) != null) {
w.write(z);
w.newLine();
}
r.close();
w.close();
}
}Die Datei SchreibInDateiGepuffered in github.
- 5127 views
Behandlung von Byte-Strömen
Behandlung von Byte-StrömenVon den Byte-Streams werden hier nur wenige ausgewählte vorgestellt
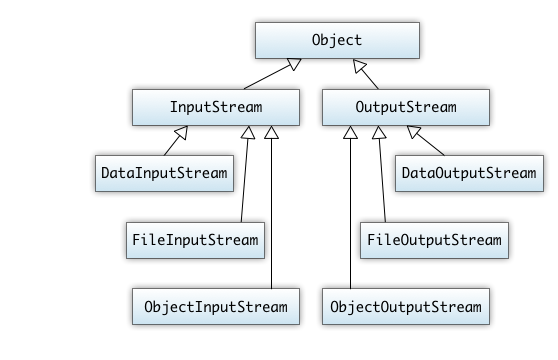
Die abstrakte Basisklasse InputStream hat für die Eingabe von Byte-Streams unter anderem die folgenden Methoden:
- public abstract int read(): sie liefert das nächste Byte aus dem Strom (im Format int!)
- public int read(byte[] b): füllt das Feld der Bytes und gibt als Rückgabe die Anzahl der gelesenen Bytes
- public int read(byte[] b, int off, int n): füllt das Feld der Bytes ab der Position off mit n Bytes und liefert die Anzahl der gelesenen Bytes zurück
- public void close(): Schliest den Strom
Die abstrakte Basisklasse OutputStream besitzt ähnliche Methoden
- public abstract void write(int b): schreibt das Byte b in den Strom
- public void write(byte[] b): schreibt alles von b referenzierten Bytes in den Strom
- public void write(byte[] b, int off, int n): schreibt ab dem Index off die nächsten n Bytes in den Strom
- public void close(): schliest den Strom
- public void flush(): leert den Puffer und schreibt alle Daten in den Strom
DataInput- und DataOutputStream
Die Klassen DataInputStream und DataOutputStream erlauben das Lesen und Schreiben von Java-Basistypen. Ihre Konstruktoren arbeiten mit den Basisklassen:
- public DataInputStream(InputStream in): Erlaubt das Lesen von einem InputStream
- public DataOutputStream(OutputStream out): Schreibt in einen OutputStream
Diese Klassen stellen dann typspezifische Methoden mit der folgenden Notation zur Verfügung. Zum Beispiel DataOutputStream:
- public xxx readxx(): Lies den Typ xxx und gib ihn aus
Serialisierung und Deserialisierung von Objekten
Die Klassen ObjectInputStream und ObjectOutputStream erlauben es Objekte aus dem Hauptspeicher in einen Stream zu schreiben.
Sie wandeln den systemabhängigen Zustand eines Objects in eine neutrale Binärdarstellung in einem Datenstrom um. Diesen Vorgang nennt man Serialisierung in Java. Den umgekehrten Vorgang nennt man Deserialiserung.
Wichtig: Es könne nur Objekte serialiert werden die die Schnittstelle Serializable implementieren. Diese Schnittstelle verlangt es nicht Methoden zu implementieren.
Alle referenzierten, serialisierbaren Objekte werden auch serialisiert.
Möchte man Instanzvariablen nicht serialisieren, muss man sie mit Schlüsselwort transient kennzeichnen.
Die beiden Klassen ObjectInputStream und ObjectOutputStream haben Konstruktoren, die es erlauben aus bzw. in andere Ströme zuschreiben:
- public ObjectInputStream(InputStream in): lesen aus einem InputStream
- public ObjectOutputStream(OutputStream out): schreiben in einen OutputStream.
In geöffnete Ströme vom Typ ObjectInputStream kann man mit der folgenden Methoden lesen:
- public final Object readObject(): liest ein Objekt aus dem Datenstrom und gibt einen Zeiger zurück.
Ähnlich kann in ObjectOutputStream mit der folgenden Methode ein Objekt schreiben
- public final void writeObject(Object obj): schreibt ein Object und alle Unterobjekte in den Strom
- 1345 views
Weitere Klassen
Weitere KlassenDas java.io Paket hat noch viele weiter Klassen. Hier eine kurze Liste der interessantesten Klassen
- RandomAccessFile: wahlfreier Zugriff auf Dateien
- InflaterInputStream, DeflaterOutputStream: checken der Integrität von Dateien mit Hilfe von Prüfsummen
- ZipInputStream, ZipOutputStream: komprimierende, dekomprimierende Ströme. Für gzip gibt es analoge Klassen
- 834 views
Übungen ( Streams)
Übungen ( Streams)Vokalverschiebung
Ersetzen Sie alle Vokale in einer Textdatei durch bestimmte andere und erzeugen Sie eine neue Datei mit den verschobenen Vokalen.
Eine Musterlösung ist in github zu finden.
- 1391 views
Lernziele
Lernziele|
|
Am Ende dieses Blocks können Sie:
|
Lernzielkontrolle
Sie sind in der Lage die folgenden Fragen zu beantworten: Fragen zur Streams
- 802 views
Threads (Nebenläufigkeit)
Threads (Nebenläufigkeit)|
|
EinleitungJava bietet als Programmiersprache von Beginn an eine aktive Unterstützung für das Programmieren mit Threads (engl der Faden, das Fädchen). Hierdurch ist es in Java relativ einfach nebenläufige Programme zu implementieren. |

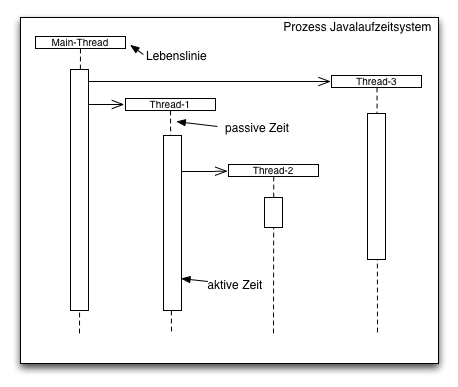
Hiermit ist die Implementierung von Javaanwendungen mit den folgenden Vorteilen möglich:
- man kann sehr viel mehr Aufgaben abarbeiten, da man es gleichzeitig tun kann.
- man kann Aufgaben schneller zu erledigen, da man es parallel tun kann.
- man kann Aufgaben asynchron, parallel im Hintergrund abarbeiten ohne auf andere Aufgaben warten zu lassen.
Prozesse und Threads im Betriebssystem
Mit Java-Threads kann man nebenläufige Programme programmieren die es erlauben mehrere Dinge gleichzeitig zu tun. Ein sehr einfaches Beispiel ist eine Programm mit einer graphische Benutzeroberfläche. Dieses Programm lädt typischerweise in einem Thread eine Datei aus dem Internet während gleichzeitig ein anderer Thread auf dem Bildschirm einen Fortschrittsbalken vergrößert.
Betriebssysteme verwalten die Ressourcen eines Rechners. Beim Programmieren mit nebenläufigen Java-Threads ist es wichtig zu verstehen, wie die beiden wichtigen Resourcen Hauptspeicher und Prozessoren vom Javalaufzeitsystem und dem Betriebsystem verwaltet werden. Bei der Betrachtung des Speichers spielt nur der virtuelle Speicher des Betriebsystems eine Rolle, da der Javaentwickler in der Regel keinen direkten Einfluss auf dem physischen Speicher nehmen kann. Moderne Betriebsysteme sind in der Lage Programme gleichzeitig bzw. nebenläufig auszuführen.
| Prozess(Informatik) |
|---|
| Ein Prozess bezeichnet in der Informatik ein im Ablauf befindliches Computerprogramm (siehe Wikipedia). Zum Prozess gehört das Programm samt seiner Daten und dem Prozesskontext (siehe Wikipedia). |
Das Javalaufzeitsystem ist aus der Sicht des Betriebssystems während seiner Ausführung ein Prozess.
Prozesse besitzen während ihrer Ausführung typischerweise:
- ein Programm welches sie ausführen. Mehrere Prozesse können durchaus das gleiche Programm ausführen
- einen eigenen Speicherbereich zur Verwaltung der Daten. Das Betriebsystem verwaltet diesen Speicher und sorgt dafür das alle Prozesse ihren eigenen Speicher benutzen können ohne sich gegenseitig zu beinflussen. Bei Java ist der Heap der bekannteste gemeinsame Speicherbereich.
- Zumindest einen Programmstack (Stapel) zur Verwaltung der Daten von Methoden und einen dazugehörige Befehlszähler/zeiger
- Zugriff auf Betriebssystemressourcen (Bildschirm, Tastatur, Massenspeicher, Netzwerk etc.)
Threads (engl. der Faden, das Fädchen) sind leichtgewichtige Ausführungseinheiten eines Prozesses:
| Thread (Informatik) |
|---|
| Ein Thread (auch: Aktivitätsträger oder leichtgewichtiger Prozess) bezeichnet in der Informatik einen Ausführungsstrang oder eine Ausführungsreihenfolge in der Abarbeitung eines Programms. Ein Thread ist Teil eines Prozesses. (siehe Wikipedia) |
Das Javalaufzeitsystem ist typischerweise ein Prozess des Betriebssystems. Die Java-Threads werden normalerweise auf Betriebssystem-Threads abgebildet. Dies war in frühen Javaimplementierungen (1.1) nicht der Fall. Hier wurden die Threads von Java selbst verwaltet (siehe Green Threads) .
Ein Thread besitzt typischerweise
- keinen eigenen Speicher (Heap). Er und alle anderen Threads des Prozesses haben Zugriff auf den gemeinsamen Hauptspeicher seines Prozesses. Durch das gemeinsame, gleichzeitige Arbeiten auf den gemeinsamen Daten ist der Datenaustausch zwischen Threads sehr einfach. Die Konsistenz der Daten muss jedoch aktiv verwaltet werden.
- einen eigenen Programmstack. Er dient der Verwaltung der aktuell aufgerufenen Methodenvariablen.
- einen eigenen Befehlszähler
Prozesse bestehen aus mindestens einem Thread (dem Haupt-Thread, Main-Thread) und eventuell zusätzlichen Threads die eigene Programmstacks zur parallelen Ausführung besitzen. Die Lebensdauer von Threads ist durch die Lebensdauer des dazugehörigen Prozesses beschränkt. Sie enden mit dem Beenden des Pozesses.
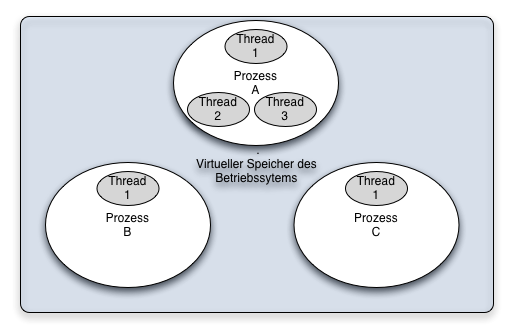
Nebenläufige Ausführung im Betriebssystem
Betriebsysteme weisen den Prozessen die Prozessoren zur Ausführung zu. Hierfür verwendet man die englischen Begriffe des "scheduling" oder "dispatching". Ziel des Betriebssystems ist es die Prozessoren möglichst gut auszunutzen und eine faire, vorteilhafte Abarbeitung aller Programme in Prozessen zu gewährleisten.
Die (historisch) einfachste Art der Verwaltung von Prozessen durch das Betriebsystem ist der Batchbetrieb (Stapelbetrieb). Ein Rechner hat typischerweise nur einen Prozessor. Das Betriebssystem kann nur ein Programm gleichzeitig als Prozess ausführen. Es weist dem Prozessor eine Programm A zu dieses läuft bis es beendet wird. Anschließend wird das nächste Programm ausgeführt:

Multi tasking: Um interaktive Benutzer zu bedienen ist es geschickter laufende Prozesse zu unterbrechen und andere Prozesse teilweise abzuarbeiten. Aufgrund der hohen Prozessorgeschwindigkeit hat der menschliche Betrachter den Eindruck, die Prozesse laufen gleichzeitig. Alle moderne Betriebsysteme arbeiten nach diesem Prinzip. Das Unterbrechen der Prozesse ist oft problemlos möglich, da sie sich oft selbst blockieren. Sie müssen da si relativ lange auf Daten von Benutzern, Festplatten, dem Netzwerk warten müssen. In diesen vielen Zwangpausen kann das Betriebssyteme andere, lauffähige Prozesse abarbeiten.
Die Prozesse laufen jetzt verschränkt und sie werden in vielen einzelnen Blöcken abgearbeitet. Sie werden quasi-parallel abgearbeitet.

Multi tasking-Multiprozessor: Da alle modernen Prozessoren mehrere Ausführungseinheiten besitzen können die Betriebsysteme Prozesse parallel abarbeiten. Die Prozesse müssen nicht zwangsweise auf dem gleichen Prozessor ausgeführt werden (siehe Beispiel). Die Gesamtausführungszeiten können bei mehren Prozessoren entsprecht verkürzen.
Multithreaded-Multiprozessor: Da Threads leichtgewichtige Prozesse mit einem Programmstack und einem eigenen Programmablauf sind, werden sie bei der Prozessorvergabe wie Prozesse behandelt. Ein Prozess kann jetzt mehrere Prozessoren gleichzeitig verwenden wenn er nur über mehrere Theads verfügt. Anwendungen können jetzt innerhalb eines Prozesses skalieren. Dies bedeutet, sie können (threoretisch) beliebig viele Prozessoren benutzen und damit beliebig viele Aufgaben in einer bestimmten Zeit abarbeiten. Der Durchsatz eines Prozesses, bzw. die Abarbeitungsgeschwindigkeit ist nicht mehr direkt an die Geschwindigkeit eines einzelnen Prozessors gebunden.
- 11778 views
Thread Zustandsübergänge
Thread ZustandsübergängeThreads und Prozesse haben unterschiedliche Zustände, die von den verfügbaren Betriebsmitteln abhängen:
- blocked: ein Thread der auf Daten von einem Gerät wie Festplatte, Tastatur, Maus oder Netzwerk wartet ist blockiert. Das Betriebssystem wird ihm keinen Prozessor zuweisen da er ihn nicht nutzen kann solange ihm die notwendigen Daten fehlen.
- ready-to-run: Der Thread hat alle Betriebsmittel, mit Ausnahme des Prozessors, die er zum Laufen benötigt. Er wartet bis der Dispatcher einen Prozessor zuweist.
- running: Der Thread hat alle nötigen Betriebsmittel inklusive eines Prozessors. Er führt sein Programm aus bis er eine nicht vorhandene Ressource benötigt oder bis er vom Dispatcher den Prozessor entzogen bekommt.
Die Übergänge zwischen den vereinfachten Zuständen eines Threads sind im folgenden Diagramm dargestellt:
Threads haben ähnlich wie Prozesse eine Reihe von Zuständen. Sie besitzen jedoch mehr Zustände, da ihre Lebensdauer kürzer als die des Prozesses ist und sie sich miteinandere synchronisieren müssen. Threads haben die folgenden fünf Zustände:
- new: Der Thread wurde mit dem new Operator erzeugt. Er befindet sich im Anfangszustand. Auf seine Daten kann man zugreifen. Er ist noch nicht ablauffähig.
- ready-to-run: Der Thread ist lauffähig und wartet auf eine Prozessorzuweisung
- running: Der Thread hat einen Prozessor und führt das Programm aus
- blocked: Der Thread wartet auf Ressourcen
- dead: Der Thread kann nicht wieder gestartet werden
Eine Reihe dieser Zustände kann durch Methodenaufrufe vom Entwickler beeinflusst werden:
- start(): Ein Thread wechselt vom Zustand "new" zu "ready-to-run"
- sleep(): Ein laufender Thread wird für eine bestimmte Zeit blockiert
- join(): Ein Thread blockiert sich selbst bis der Thread dessen join() Methode aufgerufen wurde sich beendet hat
- yield(): Ein Thread gibt freiwillig den Prozessor auf und erlaubt der Ablaufsteuerung den Prozessor einem anderen Thread zuzuweisen
- interrupt(): Erlaubt es Threads die wegen eines sleep() oder join() blockiert sind wieder in den Zustand "ready-to-run" zu versetzen
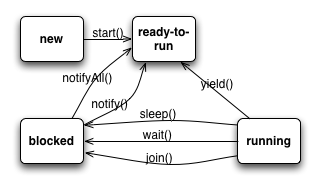
- 9158 views
Programmieren mit Threads
Programmieren mit ThreadsJava erlaubt das Erzeugen und Verwalten von Threads mit Hilfe der Systemklasse Thread. Beim Starten einer Javaanwendung bekommt die Methode main() automatisch einen Thread erzeugt und zugewiesen der sie ausführt. Mit Hilfe der Klasse Thread kann man selbst zusätzliche Threads erzeugen und starten.
Erzeugen und Start mit der Klasse Thread
Man kann einen neuen Thread starten indem man ein Objekt von Thread erzeugt. Hiermit wird parallel im Hintergrund ein Javathread erzeugt. Das Aufrufen der Methode start() startet dann den neuen Thread. Dies geschieht wie im folgenden Beispiel gezeigt:
public static void main(String[] args {
...
Thread t1= new Thread(...);
t1.start();
...
}Im Laufzeitsystem wird hierdurch zuerst ein neuer Thread erzeugt und dann gestartet:
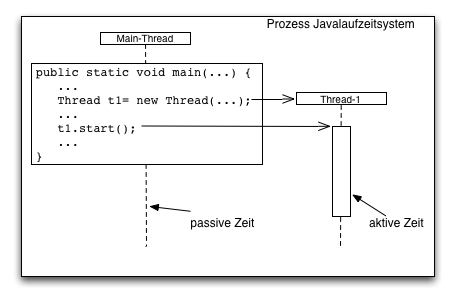
Es verbleibt die Frage welchen Programmcode der neue Thread ausführt.
Der ausgeführte Programmcode steht in einer Methode mit den Namen run() und muss von einer Klasse nach den Vorgaben der Schnittstelle Runnable implementiert werden.
Hierfür muss beim Erzeugen des Thread-objekts eine Referenz auf ein Objekt mitgegeben werden welches diese Schnittstelle implementiert. Geschieht dies nicht wird die Methode run() des Tread-objekts aufgerufen. Hierdurch ergeben sich zwei Möglichkeiten einen eigenen Thread mit einem bestimmten Programm zu starten:
Starten eines Threads durch Erweitern der Klasse Thread
Die erste Möglichkeit besteht im Erweitern der Klasse Thread und im überschreiben der Methode run().
Die Klasse Thread implementiert schon selbst die Schnittstelle Runnable. Ruft man die Methode start() ohne einen Parameter auf, so wird bei einer angeleiteten Klasse die überschriebene Methode run() in einem eigenen neuen Thread aufgerufen.
Im unten aufgeführten Beispiel wurde die Klasse myThread aus der Klasse Thread abgeleitet:
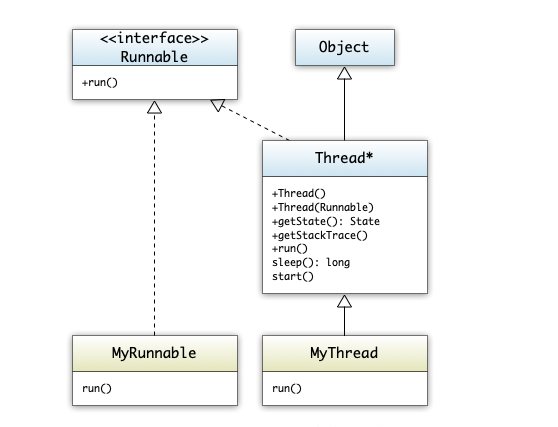
Die Klasse myThread verwaltet die Threads in ihrer main() Methode. Das Erzeugen und Starten der Threads der Klasse myThread könnte auch aus jeder anderen beliebigen Klasse erfolgen.
package s2.thread;
/**
*
* @author s@scalingbits.com
*/
public class MyThread extends Thread {
@Override
public void run() {
System.out.println("Hurra ich bin myThread in einem Thread mit der Id: "
+ Thread.currentThread().getId());
}
public static void main(String[] args) {
System.out.println("Start MyThread.main() Methode im Thread mit der Id: "
+ Thread.currentThread().getId());
MyThread t1 = new MyThread();
t1.start();
System.out.println("Ende MyThread.main() Methode im Thread mit der Id: "
+ Thread.currentThread().getId());
MyThread t2 = new MyThread();
// t2 ist zwar ein Threadobjekt und repräsentiert einen Thread
// da das Objekt nicht mit start() aufgerufen läuft es im gleichen
// Thread wie die main() Routine!
t2.run();
}
} // Ende der KlasseDas Programm erzeugt die folgende Konsolenausgabe:
Start MyThread.main() Methode im Thread mit der Id: 1 Ende MyThread.main() Methode im Thread mit der Id: 1 Hurra ich bin myThread in einem Thread mit der Id: 1 Hurra ich bin myThread in einem Thread mit der Id: 9
Im Beispielprogramm wird für die Referenz t1 ein neues Threadobjekt erzeugt. Anschliesend wird es durch seine start() Methode in einem eigenen Thread gestartet. Die run() Methode wird nach dem Starten im eigenen Thread ausgeführt.
Das Objekt mit der Referenz t2 ist zwar auch ein Thread. Das es aber direkt mir der run() Methode aufgerufen wird, läuft es im gleichen Thread wie die main() Methode.
Im UML Sequenzdiagramm ergibt sich der folgende Ablauf:
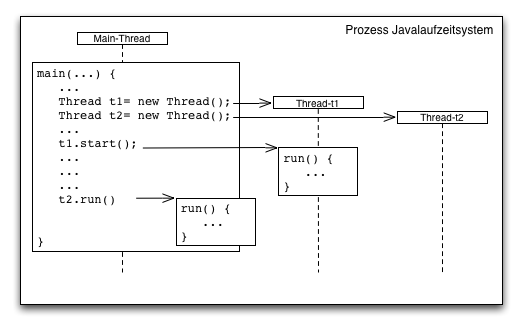
Starten eines Threads durch Implementieren der Schnittstelle Runnable
Das Erweitern einer Klasse aus der Klasse Thread ist nicht immer möglich. Man kann einen Thread auch starten indem man ein Thread-objekt erzeugt und ihm die Referenz auf eine Instanz der Schnittstelle Runnable mitgibt. Die Programmierabfolge ist dann:
- Erzeugen eine Threadobjekts mit Referenz auf eine Instanz von Runnable.
- Aufrufen der start() Methode des Threadobjekts
- die Methode run() der Runnable-objekts wird automatisch aufgerufen
Die Klasse myRunnable:
package s2.thread;
/**
*
* @author s@scalingbits.com
*/
public class MyRunnable implements Runnable {
@Override
public void run() {
System.out.println("Hurra ich bin myRunnable in einem Thread mit der Id: "
+ Thread.currentThread().getId());
}
}
Die Klasse ThreadStarter die als Hauptprogramm dient:
package s2.thread;
/**
*
* @author s@scalingbits.com
*/
public class ThreadStarter{
public static void main(String[] args) {
System.out.println("Start ThreadStarter.main() Methode im Thread mit der Id: "
+ Thread.currentThread().getId());
MyRunnable r1 = new MyRunnable();
MyRunnable r2 = new MyRunnable();
Thread t1 = new Thread(r1);
Thread t2 = new Thread(r2);
t1.start();
System.out.println("Ende ThreadStarter.main() Methode im Thread mit der Id: "
+ Thread.currentThread().getId());
// r2 ist zwar ein Runnableobjekt , da das Objekt aber nicht von einem
// Threadobjekt indirekt aufgerufen wirdläuft es im gleichen
// Thread wie die main() Routine!
r2.run();
}
}Das Programm erzeugt die gleichen Ausgaben wie das vorherige Programm:
Start ThreadStarter.main() Methode im Thread mit der Id: 1 Ende ThreadStarter.main() Methode im Thread mit der Id: 1 Hurra ich bin myRunnable in einem Thread mit der Id: 1 Hurra ich bin myRunnable in einem Thread mit der Id: 9
Das Aufrufen von r2.run() startet keinen eigenen Thread. Der Vorteil der Benutzung der Schnittstelle Runnable liegt darin, dass man die Methode run() in jeder beliebigen Klasse implementieren kann.
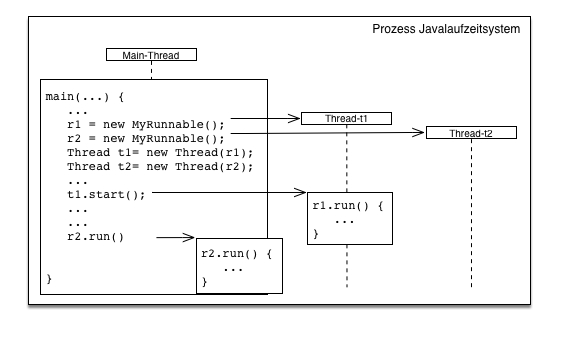
Die wichtigsten Methoden der Klasse Thread
- Konstruktor: Thread(Runnable target) : Erzeugt einen neuen Thread und übergibt ein Objekt dessen run() Methode beim Starten des Threads aufgerufen (anstatt die eigene run() Methode aufzurufen.
- static Thread currentThread(); liefert den aktuellen Thread der ein Codestück gerade ausführt
- long getId(): Liefert die interne Nummer des Threads
- join(): Hält den aktuellen Thread an bis der referenzierte Thread beendet ist.
- static void sleep(long millis): Lässt den aktuellen Thread eine Anzahl von Millisekunden schlafen.
- start(): Lässt die VM den referenzierten Thread starten. Dieser ruft dann die run() Methode auf.
- 18420 views
Synchronisation
SynchronisationDa Threads auf die gleichen Objekte auf im Heap zugreifen, können sie so sehr effizient Daten austauschen. Es besteht jedoch das Risiko der Datenkorruption, da man oft mehrere Daten gleichzeitig verändern muss um sie von einem konsistenten Zustand in den nächsten konsistenten Zustand zu überführen.
Die Sitzplatzreservierung in einem Flugzeug ist hierfür ein typisches Beispiel:
Mehrere Reisebüros prüfen ein Flugzeug auf die Verfügbarkeit von 10 Plätzen für eine Reisegruppe. Ergibt das Lesen der Belegungsvariable 20 freie Plätze, so fährt Reisebüro 1 fort und liest weitere Daten um die Buchung vorzubereiten. Verzögert sich die endgültige Buchung so kann es vorkommen, dass ein zweites Reisebüro die Verfügbarkeit von 15 Plätzen abfragt und die 15 Plätze bucht. Das zweite Reisebüro erhöht den Belegungszähler also um 15 Plätze.
Kommt das erste Reisebüro nun endlich mit seiner Buchung vorran und erhöht die ursprünglich ausgelesene Variable um 10 ergibt sich ein inkonsistenter Zustand.
Man muss also in Systemen mit parallelen Zugriff auf Daten die Möglichkeit schaffen nur einen Thread über eine gewisse Zeit auf einem Datensatz (Objekt) arbeiten zu lassen um wieder einen konsistenten Zustand herzuführen.
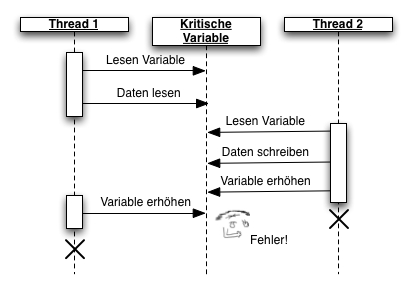
Darf nur ein Thread gleichzeitig auf einer Variablen arbeiten, so nennt man diese eine kritische Variable. Die Zeit die ein Thread mit der Bearbeitung einer solchen Varriablen verbringt nennt man den kritischen Abschnitt oder auch den kritischen Pfad.
Das oben geschilderte Problem beim gleichzeitigen Zugriff nennt man auch "Reader/Writer" Problem, da das Lesen und Schreiben auf dem Datum atomar erfolgen muss. Da in in nebenläufigen Systemen diese Datenkorruption ausschlieslich von der Geschwindigkeit und dem zufälligen paralleln Zugriff abhängt nennt man ein solches Problem auch eine "Race Condition". Die Datenkorruption tritt zufällig und abhängig von der Ausführungsgeschwindigkeit auf.
Beispiel: Nichtatomares Inkrement in Java
Der ++ Operator ist Java ist nicht atomar. Dies bedeutet, dass zwei Threads einen bestimmten Wert auslesen können und der erste Thread schreibt den um 1 erhöhten Wert zurück während eventuell der zweite Thread noch etwas Zeit benötigt. Schreibt der zweite Thread dann den gleichen inkrementierten Wert zurück wurde die Zahl nur einmal inkrementiert. Es liegt eine Datenkorruption vor.
Im Programm ParaIncrement wird eine gemeinsame Variable zaehler von zwei Threads gleichzeitig inkrementiert. Der Wert der Variablen sollte immer doppelt so groß wie die Anzahl der Durchläufe (Konstante MAX) eines einzelnen Threads sein.Die Korruption im Programm ParaIncrement findet relativ selten selten statt. Man muss die Konstante K für die Anzahl der Durchläufe eventuell abhängig vom Rechner und der Java virtuellen Maschine anpassen:
package s2.thread;
/**
*
* @author s@scalingbits.com
*/
public class ParaIncrement extends Thread {
public static int zaehler=0;
public static final int MAX= Integer.MAX_VALUE/10;
public static void increment() {
zaehler++;
}
/**
* Starten des Threads
*/
public void run() {
for (int i=0; i < MAX; i++) {
increment();
}
}
public static void main(String[] args) {
ParaIncrement thread1 = new ParaIncrement();
ParaIncrement thread2 = new ParaIncrement();
long time = System.nanoTime();
thread1.start();
thread2.start();
try {
thread1.join();
thread2.join();
} catch (InterruptedException e) {
}
time = (System.nanoTime() -time)/1000000L; // time in milliseconds
if ((2* ParaIncrement.MAX) == ParaIncrement.zaehler)
System.out.println("Korrekte Ausführung: " +
+ ParaIncrement.zaehler + " (" + time + "ms)");
else
System.out.println("Fehler! Soll: " + (2* ParaIncrement.MAX) +
"; Ist: " +ParaIncrement.zaehler + " (" + time + "ms)");
}
}
Wechselseitiger Ausschluss
Zur Vermeidung der oben genannten Korruption ist es wichtig sicher zustellen, dass nur ein Thread gleichzeitig Zugriff auf diese Daten hat.
 |
Das oben gezeigte Programm zeigt die Millisekunden an die es benötigt. Wieviel sind es? Man kann das Schlüsselwort synchronized als Modifizierer in die Methode increment() einpflegen. Läuft das Programm jetzt langsamer oder schneller? Läuft es korrekt oder inkorrekt? |
| Kritischer Abschnitt/ Kritischer Pfad |
|---|
| Ein kritischer Abschnitt ist eine Folge von Befehlen, die ein Thread nacheinander vollständig abarbeiten muss, auch wenn er vorübergehend die CPU and einen anderen Thread abgibt. Kein anderer Thread darf einen kritischen Abschnitt betreten, der auf die gleichen Variablen zugreift, solange der erstgenannte Thread mit der Abarbeitung der Befehlsfolge noch nicht fertig ist. (siehe: Goll, Seite 744) |
Einfachste Lösung: Verwendung von Typen die den kritischen Pfad selbst schützen
Das Java Concurrency Paket bietet reichhaltige Möglichkeiten und Klassen. Das oben gezeigte Beispiel kann mit Hilfe der Klasse AtomicInteger sicher implementiert werden. Die Klasse AtomicInteger erlaubt immer nur einem Thread Zugriff auf das Datum. Die entsprechende Implementierung ist:
package s2.thread;
import java.util.concurrent.atomic.AtomicInteger;
/**
*
* @author s@scalingbits.com
*/
public class ParaIncrementAtomicInt extends Thread {
public static AtomicInteger zaehler;
public static final int MAX= Integer.MAX_VALUE/100;
public static void increment() {
zaehler.getAndIncrement();
}
/**
* Starten des Threads
*/
public void run() {
for (int i=0; i < MAX; i++) {
increment();
}
}
public static void main(String[] args) {
zaehler = new AtomicInteger(0);
ParaIncrementAtomicInt thread1 = new ParaIncrementAtomicInt();
ParaIncrementAtomicInt thread2 = new ParaIncrementAtomicInt();
long time = System.nanoTime();
thread1.start();
thread2.start();
try {
thread1.join();
thread2.join();
} catch (InterruptedException e) {
}
time = (System.nanoTime() -time)/1000000L; // time in milliseconds
if ((2* ParaIncrementAtomicInt.MAX) == zaehler.get())
System.out.println("Korrekte Ausführung: " +
+ ParaIncrementAtomicInt.zaehler.get() + " (" + time + "ms)");
else
System.out.println("Fehler! Soll: " + (2* ParaIncrementAtomicInt.MAX) +
"; Ist: " +ParaIncrementAtomicInt.zaehler.get() + " (" + time + "ms)");
}
}
Vergleichen Sie die Laufzeiten beider Anwendungen! Die Anwendung bei der immer nur ein Thread auf das Objekt zugreifen kann ist erheblich langsamer, jedoch korrekt.
Sperren durch Monitore mit dem Schlüsselwort synchronized
Um die oben gezeigten Möglichkeiten von Korruptionen zu vermeiden verfügen Javaobjekte über Sperren die Monitore genannt werden. Jedes Javaobjekt besitzt einen Monitor der gesetzt ist oder nicht gesetzt ist.
- Ein Monitor wird gesetzt wenn eine Instanzmethode des Objekts aufgerufen wird, die mit dem Schlüsselwort synchronized versehen ist.
- Kein anderer Thread kann eine synchronisierte Instanzmethode des gleichen Objekts aufrufen, solange der Thread der den Monitor erworben hat noch in der synchronisierten Methode arbeitet.
- Alle anderen Threads werden beim Aufruf einer synchronisierten Instanzmethode des gleichen Objekts blockiert und müssen warten bis der erste Thread die synchronisierte Methode verlassen hat.
- Nach dem der erste Thread die synchronisierten Methode verlassen hat, wird der Monitor wieder freigegeben.
- Der nächste Thread, der eventuell schon wartet kann den Monitor erwerben.
Es ist wichtig zu verstehen, dass in Java immer die individuellen Objekte mit einem Monitor geschützt sind. Sind zum Beispiel die Sitzplätze eines Flugzeuges durch Java-Objekte implementiert, so kann man mit der gleichen synchronisierten Methode auf untrschiedlichen Objekte parallel arbeiten.
Am Beispiel der Klasse Sitzplatz kann man sehen wie man den Monitor für einen bestimmten Sitzplatz setzen kann:
package s2.thread;
/**
*
* @author s@scalingbits.com
*/
public class Sitzplatz {
private boolean frei = true;
private String reisender;
boolean istFrei() {return frei;}
/**
* Buche einen Sitzplatz für einen Kunden falls er frei ist
* @param kunde Name des Reisenden
* @return erfolg der Buchung
*/
synchronized boolean belegeWennFrei(String kunde) {
boolean erfolg = frei; // Kein Erfolg wenn nicht frei
if (frei) {
reisender = kunde;
frei = false;
}
return erfolg;
}
}
Die Methode belegeWennFrei() kann jetzt nur noch von einem Thread auf einem Objekt gleichzeitig aufgerufen werden. Die Methode istFrei() ist nicht synchronisiert und in einer parallelen Umgebung nicht sehr relevant. Man kann sich nicht darauf verlassen, dass bei der nächsten Operation der freie Zustand noch gilt.
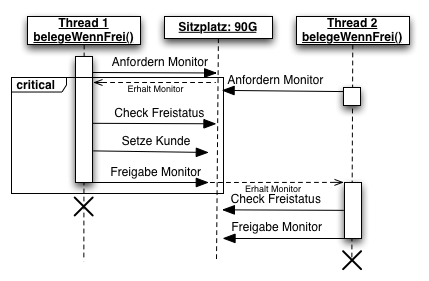
| Monitore und Schutz von Daten |
|---|
|
Monitore schützen nur die synchronsierten Methoden eines Objekts. Dies bedeutet
|
Statische synchronisierte Methoden
Das Schlüsselwort synchronized kann auch verwendet werden um einen Monitor für die Klasse zu setzen. Dieser Monitor hat aber keinen Einfluss auf den Zugriff auf die Objekte einer Klasse! Er schützt nur statische Methoden der Klasse.
Beispiel: Man kann das Korruptionsproblem in der Klasse ParaIncrement beheben in dem man die statische Methode increment() synchronsiert:
public static synchronized void increment() {
zaehler++;
}
Die Variable zaehler ist in diesem Beispiel eine statische Variable. Sie gehört nicht zu einem der beiden erzeugten Objekten.
Synchronisierte Blöcke
Man muss nicht notwendigerweise eine gesamt Methode synchroniseren. Java bietet auch die Möglichkeit einzelne Blöcke zu synchronisieren. Das Synchronsieren eines Blocks erfolgt ebenfalls mit Hilfe des Schlüsselworts synchronized. Hier muss man jedoch das Objekt angeben für welches man einen Monitor erwerben will.
Man kann die Sitzplatzreservierung auch mit Hilfe eines synchronisierten Blocks implementieren:
boolean belegeWennFrei(String kunde) {
boolean erfolg;
synchronized (this) {
erfolg = frei; // Kein Erfolg wenn nicht frei
if (frei) {
reisender = kunde;
frei = false;
}
}
return erfolg;
}
In dieser Implementierung kann die Methode belegeWennFrei() parallel aufgerufen werden. Beim Schlüsselwort synchronized muss jedoch für das aktuelle Objekt der Monitor erworben werden bevor der Thread fortfahren kann.
Referenzen
- Goll,Heinisch, Müller-Hoffman: Java als erste Programiersprache, Teubner Verlag
- IBM Developerworks: Going Atomic: Gute Erklärung zu synchronisierten Zählern (AtomicInteger)
- 5099 views
Beispiel: Kritischer Pfad
Beispiel: Kritischer PfadDas hier benutzte Beispielprogramm visualiert 15 Threads die sich auf einem synchronisierten Objekt serialisieren.
Threads in grüner Farbe befinden sich nicht im kritischen Pfad. Threads in roter Farbe befinden sich im kritischen Pfad.
Der kritische Pfad in in der Klasse EinMonitor in der Methode buchen() implementiert.
Die einzige Instanz von EinMonitor verfügt über zwei Variablen a und b die Konten darstellen sollen.
Die Methode buchen() "verschiebt" mehrfach einen Betrag zwischen den beiden Konten. Die Summe der beiden Variablen sollte am Ende der Methode stets gleich sein.
Die Methode buchen() enthält etwas Overhead zur Visualierung des Konzepts:
- am Anfang und am Ende muss das GUI Subsystemen über den Eintritt und das Verlassen des kritischen Pfads informiert werden
- zwischen allen Buchungen werden kleine Schlafpausen eingelegt um die Zeit im kritischen Pfad künstlich zu verlängern
Die Methode buchen() enthält eine Konsistenzprüfung am Ende der Methode die bei einem Fehler in der Buchführung eine Konsolenmeldung ausdruckt. Sie kommt in der auf dieser Seite gezeigten Variante nicht zum Zuge!
Die Klasse MainTest dient zum Starten des Programms. Sie erzeugt und startet die 15 Threads. Jeder Thread führt nur eine gewisse Anzahl von Buchungen durch und beendet sich dann.
Aufgaben
- Übersetzen Sie die Klassen und starten Sie das Hauptprogramm
- Der Schieberegler erlaubt das Einstellen der Schlafpausen im kritischen Pfad. Was geschieht wenn der kritische Pfad verkürzt wird?
- Entfernen die das Schlüsselwort synchronized in der Methode buchen(). Was geschieht?
- Was würde geschehen geschehen wenn die künstlichen sleep Aufrufe entfernt werden?
- Hinweis: Sie müssen dann auch die Anzahl der Durchläufe pro Thread stark erhöhen. Da die Zeit im kritischen Pfad sehr kurz wird.
- Was geschieht wenn man den yield() Aufruf für in der run() Methode von MainTest entfernt
Kommentar
Da die aktuelle Ausführungsgeschwindigkeit, 4-5 Zehnerpotenzen, jenseits der menschlichen Wahrnehmungsfähigkeit liegt ist, es sehr schwer die echten Abläufe im Zeitlupentempo zu visualisieren. Ein künstlicher sleep() Aufruf blockiert den Prozess und gibt den Prozessor an das Betriebssystem zurück. Der Scheduler des Betriebssystems trifft bei dieser künstlichen Verlangsamung eventuell andere Entscheidungen in Bezug auf den Thread den er ausführt. Das gleiche Problem besteht beim Debuggen von Javaprogrammen. Durch das Bremsen bestimmter Threads können existierende Fehler nicht mehr reproduzierbar sein oder bisher nicht aufgetretene Fehler in der Synchronsiation können sichtbar werden.
Starten des Programms
Die benötigten Klassen sind in Threading.jar zusammen gefaßt.
Man kann diese jar Datei mit
java -jar Threading.jar
von der Kommandozeile nach dem Runterladen starten. Vielleicht reicht auch ein Doppelklick auf die Datei im Download-Ordner...
Nach dem Übersetzen der Dateien oder nach dem Starten der jar-Datei erscheint ein GUI wie es im folgenden Bild zu sehen ist:
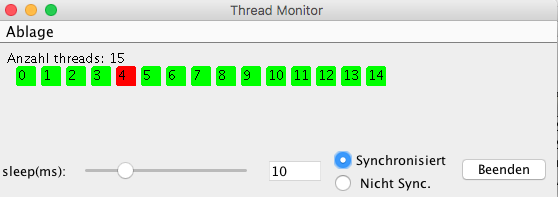
Klasse MainTest
Hauptprogramm der Anwendung.
package s2.thread;
/**
*
* @author s@scalingbits.com
*/
public class MainTest extends Thread {
public static final int INCRITICALPATH = 0;
public static final int NOTINCRITICALPATH = 1;
public static final int ENDED = 2;
public static int anzahlThreads = 15;
public static MainTest[] mt;
public int threadStatus = NOTINCRITICALPATH;
private static EinMonitor myMonitor;
public static int sleepPeriod = 500;
public int meineID;
public static ThreadingPanel tp;
public static ThreadFenster tg;
public boolean stop = false;
public boolean synchron = true;
public MainTest(int id) {
meineID = id;
}
@Override
public void run() {
long anfangszeit = System.nanoTime();
System.out.println("Thread [" + meineID + "] gestartet");
//GUIupdate(NOTINCRITICALPATH);
for (long i = 0; i < 200; i++) {
Thread t = Thread.currentThread();
// Erlaube anderen Threads die CPU zu holen
t.yield();
if (tg.synchron)
myMonitor.buchen(10);
else
myMonitor.parallelbuchen(10);
}
threadStatus = ENDED;
System.out.println("Thread [" + meineID + "] beendet...");
}
public static void main(String[] args) {
// Anlegen des Monitorobjekts
myMonitor = new EinMonitor(1000000L);
mt = new MainTest[anzahlThreads];
tg = new ThreadFenster();
tp = tg.tp;
// Erzeuge die Threads
for (int i = 0; i < anzahlThreads; i++) {
mt[i] = new MainTest(i);
}
// Starte die Threads
for (int i = 0; i < anzahlThreads; i++) {
mt[i].start();
}
}
}Klasse EinMonitor
package s2.thread;
/**
*
* @author s@scalingbits.com
*/
public class EinMonitor {
long invariante;
long a;
long b;
public EinMonitor(long para) {
invariante = para;
a = para;
b = 0L;
}
synchronized public void buchen(long wert) {
GUIupdate(MainTest.INCRITICALPATH);
sleepABit(MainTest.sleepPeriod/5);
this.a = this.a - wert;
sleepABit(MainTest.sleepPeriod/5);
this.b = this.b + wert;
sleepABit(MainTest.sleepPeriod/5);
this.a = this.a + wert;
sleepABit(MainTest.sleepPeriod/5);
this.b = this.b - wert;
sleepABit(MainTest.sleepPeriod/5);
GUIupdate(MainTest.NOTINCRITICALPATH);
if ((a+b) != invariante)
System.out.println("Inkonsistenter Zustand");
}
public void parallelbuchen(long wert) {
GUIupdate(MainTest.INCRITICALPATH);
sleepABit(MainTest.sleepPeriod/5);
this.a = this.a - wert;
sleepABit(MainTest.sleepPeriod/5);
this.b = this.b + wert;
sleepABit(MainTest.sleepPeriod/5);
this.a = this.a + wert;
sleepABit(MainTest.sleepPeriod/5);
this.b = this.b - wert;
sleepABit(MainTest.sleepPeriod/5);
GUIupdate(MainTest.NOTINCRITICALPATH);
if ((a+b) != invariante)
System.out.println("Inkonsistenter Zustand");
}
private void sleepABit(int sleep) {
try {
Thread.sleep(sleep);
} catch (InterruptedException e) {}
}
private void GUIupdate(int status) {
MainTest t = (MainTest) Thread.currentThread();
t.threadStatus = status;
t.tp.repaint();
}
}Klasse ThreadFenster
package s2.thread;
import java.awt.BorderLayout;
import java.awt.Container;
import java.awt.event.ActionEvent;
import java.awt.event.ActionListener;
import javax.swing.BoxLayout;
import javax.swing.ButtonGroup;
import javax.swing.JButton;
import javax.swing.JFrame;
import javax.swing.JLabel;
import javax.swing.JMenu;
import javax.swing.JMenuBar;
import javax.swing.JMenuItem;
import javax.swing.JPanel;
import javax.swing.JRadioButton;
import javax.swing.JSlider;
import javax.swing.JTextField;
import javax.swing.event.ChangeEvent;
import javax.swing.event.ChangeListener;
/**
*
* @author s@scalingbits.com
*
*/
public class ThreadFenster {
final private JFrame hf;
private JButton okButton;
final private JButton exitButton;
JTextField threadDisplay;
private final static int SLEEPMIN = 1;
private final static int SLEEPMAX = 2000;
private final static int SLEEPINIT = 500;
private final int threadCurrent = 10;
public ThreadingPanel tp;
public boolean synchron = true;
JRadioButton syncButton;
JRadioButton nosyncButton;
public class exitActionListener implements ActionListener {
@Override
public void actionPerformed(ActionEvent e) {
System.exit(0);
}
}
/**
* Aufbau des Fensters zur Ausnahmebehandlung
*
*/
public ThreadFenster() {
JPanel buttonPanel;
// Erzeugen einer neuen Instanz eines Swingfensters
hf = new JFrame("Thread Monitor");
//Nicht Beenden bei Schliesen des Fenster
hf.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
// Anlegen der Buttons
exitButton = new JButton("Beenden");
JLabel threadsLabel = new JLabel("sleep(ms):");
JSlider threadSlider = new JSlider
(JSlider.HORIZONTAL, SLEEPMIN, SLEEPMAX, SLEEPINIT);
threadDisplay = new JTextField();
threadDisplay.setText(Integer.toString(threadCurrent));
threadDisplay.setColumns(4);
threadDisplay.setEditable(false);
threadSlider.addChangeListener(new ChangeListener() {
@Override
public void stateChanged(ChangeEvent e) {
JSlider source = (JSlider) e.getSource();
if (!source.getValueIsAdjusting()) {
MainTest.sleepPeriod = source.getValue();
threadDisplay.setText(Integer.toString(MainTest.sleepPeriod));
}
}
});
exitButton.addActionListener(new exitActionListener());
syncButton = new JRadioButton("Synchronisiert");
syncButton.addActionListener(new ActionListener() {
@Override
public void actionPerformed(ActionEvent e) {
synchron= true;
System.out.println("Synchronisiert");
}
} );
syncButton.setSelected(true);
nosyncButton = new JRadioButton(" Nicht Sync.");
nosyncButton.addActionListener(new ActionListener() {
@Override
public void actionPerformed(ActionEvent e) {
synchron= false;
System.out.println("Nicht synchronisiert");
}
} );
ButtonGroup group = new ButtonGroup();
group.add(syncButton);
group.add(nosyncButton);
JPanel syncPanel = new JPanel();
BoxLayout bl = new BoxLayout(syncPanel, BoxLayout.Y_AXIS);
syncPanel.setLayout(bl);
syncPanel.add(syncButton);
syncPanel.add(nosyncButton);
//Aufbau des Panels
//buttonPanel = new JPanel(new GridLayout(1, 0));
buttonPanel = new JPanel();
buttonPanel.add(threadsLabel);
buttonPanel.add(threadSlider);
buttonPanel.add(threadDisplay);
//buttonPanel.add(okButton);
buttonPanel.add(syncPanel);
buttonPanel.add(exitButton);
tp = new ThreadingPanel();
// Aubau des ContentPanes
Container myPane = hf.getContentPane();
myPane.add(buttonPanel, BorderLayout.SOUTH);
myPane.add(tp, BorderLayout.CENTER);
JMenuBar jmb = new JMenuBar();
JMenu jm = new JMenu("Ablage");
jmb.add(jm);
JMenuItem jmi = new JMenuItem("Beenden");
jmi.addActionListener(new exitActionListener());
jmi.setEnabled(true);
jm.add(jmi);
hf.setJMenuBar(jmb);
//Das JFrame sichtbar machen
hf.pack();
hf.setVisible(true);
hf.setAlwaysOnTop(true);
}
}Klasse ThreadingPanel
package s2.thread;
import java.awt.Color;
import java.awt.Dimension;
import java.awt.Graphics;
import javax.swing.JPanel;
/**
*
* @author s@scalingbits.com
*/
public class ThreadingPanel extends JPanel {
private final int ziffernBreite = 10; // Breite einer Ziffer in Pixel
private final int ziffernHoehe = 20; // Hoehe einer Ziffer in Pixel
public ThreadingPanel() {
setPreferredSize(new Dimension(200, 100));
setDoubleBuffered(true);
}
/**
* Methode die das Panel überlädt mit der Implementierung
* der Treads
* @param g
*/
@Override
public void paintComponent(Graphics g) {
super.paintComponent(g);
int maxWidth = getWidth();
int maxHeight = getHeight();
g.setColor(Color.black);
g.drawString("Anzahl threads: " + MainTest.anzahlThreads, 10, 20);
for (int i = 0; i < MainTest.anzahlThreads; i++) {
paintThread(g, i, 20 + 25 * i, 30);
}
}
/**
* Malen eines Threads und seines Zustands
* @param g Graphicshandle
* @param id Identifier
* @param x X Koordinate des Thread
* @param y Y Koordinate des Thread
*/
public void paintThread(Graphics g, int id, int x, int y) {
int xOffset = 1; // offset Box zu Text
int yOffset = 7; // offset Box zu Text
//String wertThread = k.toString(); // Wert als Text
if (MainTest.mt[id] != null) {
switch(MainTest.mt[id].threadStatus) {
case MainTest.ENDED: g.setColor(Color.LIGHT_GRAY); break;
case MainTest.NOTINCRITICALPATH: g.setColor(Color.GREEN); break;
case MainTest.INCRITICALPATH: g.setColor(Color.RED); break;
default: assert(true):"Hier laeuft etwas falsch";
}
}
int breite = 2 * ziffernBreite;
int xNextNodeOffset = 20;
int yNextNodeOffset = ziffernHoehe * 6 / 5; // Vertikaler Offset zur naechsten Kn.ebene
//g.setColor(Color.); // Farbe des Rechtecks im Hintergrund
g.fillRoundRect(x - xOffset, y - yOffset, breite, ziffernHoehe, 3, 3);
g.setColor(Color.black); // Schriftfarbe
g.drawString(Integer.toString(id), x + xOffset, y + yOffset);
}
}- 4825 views
Java Concurrency Paket
Java Concurrency PaketMit JDK 5.0 wurde das Java Concurrency Paket, welches maßgeblich von Doug Lea mitentwickelt wurde (siehe Wikipedia), Teil der Laufzeitumgebung (JRE). Das Paket java.util.concurrent fügt komplexe Klassen zur Laufzeitumgebung die das Steuern der Parallelität auf einem höheren Niveau als das grundlegenden Konstrukte von Java erlauben.
In diesem Abschnitt werden einige, wenige Klassen vorgestellt. Schauen Sie sich dieses Paket an bevor Sie etwas Nebenläufiges implementieren. Hier gibt es sehr viele, sehr mächtige Lösungen, die die Vorlesung bei weitem übersteigen
Referenzen
- 982 views
Atomare Basistypen
Atomare BasistypenIn java.util.concurrent.atomic werden Basistypen zur Verfügung gestellt die atomar sind.
Atomar bedeutet, dass das Lesen des Datums und das anschließende Modifizieren nicht von anderen Operationen unterbrochen werden kann. Das Lesen und Modifizieren erfolgt in einem kritischen Pfad.
Ein Beispiel: Die Klasse AtomicInteger implementiert Number und hat die zum Beispiel Methoden wie:
- int addAndGet(int delta): addiere den Wert delta und gib die Summe aus
- boolean compareAndSet(int expect, int update): setzt den Wert update wenn der Wert expect vorliegt.
Anbei ein Beispiel zum nebenläufigen Addieren:
package s2.thread;
import java.util.concurrent.atomic.AtomicInteger;
/**
*
* @author s@scalingbits.com
*/public class ParaIncrementAtomicInt extends Thread {
public static AtomicInteger zaehler;
public static final int MAX= Integer.MAX_VALUE/100;
public static void increment() {
zaehler.getAndIncrement();
}
/**
* Starten des Threads
*/
public void run() {
for (int i=0; i < MAX; i++) {
increment();
}
}
public static void main(String[] args) {
zaehler = new AtomicInteger(0);
ParaIncrementAtomicInt thread1 = new ParaIncrementAtomicInt();
ParaIncrementAtomicInt thread2 = new ParaIncrementAtomicInt();
long time = System.nanoTime();
thread1.start();
thread2.start();
try {
thread1.join();
thread2.join();
} catch (InterruptedException e) {
}
time = (System.nanoTime() -time)/1000000L; // time in milliseconds
if ((2* ParaIncrementAtomicInt.MAX) == zaehler.get())
System.out.println("Korrekte Ausführung: " +
+ ParaIncrementAtomicInt.zaehler.get() + " (" + time + "ms)");
else
System.out.println("Fehler! Soll: " + (2* ParaIncrementAtomicInt.MAX) +
"; Ist: " +ParaIncrementAtomicInt.zaehler.get() + " (" + time + "ms)");
}
}
- 1040 views
Das "Fork-Join-Framework"
Das "Fork-Join-Framework"Es gibt zwei Möglichkeiten das Threading in Java zu nutzen:
- Erledigen unterschiedlicher Aufgaben parallel
- Bsp: Swing: Oberfläche neu zeichen, Eingaben abarbeiten, eigentliche Programmaufgaben ausführen
- Paralleles Abarbeiten der gleichen Aufgabe
- Bsp: Differentialgleichungen berechnen, Such & Sortieralgorithmen, Bearbeitung von Massendaten (Batch).
Das Fork & Join Framework erleichert das parallele Programmieren durch eine Optimierung der Parallelität und komfortable Klassen.
Im Rahmen der Vorlesung werden wir die Möglichkeiten einer Parallelisierung ohne und mit Rückgaben diskutieren. Die Unterschiede zum Einsatz der einfachen Threadingkonstrukte und der des Frameworks sind im Diagramm unten dargestellt:
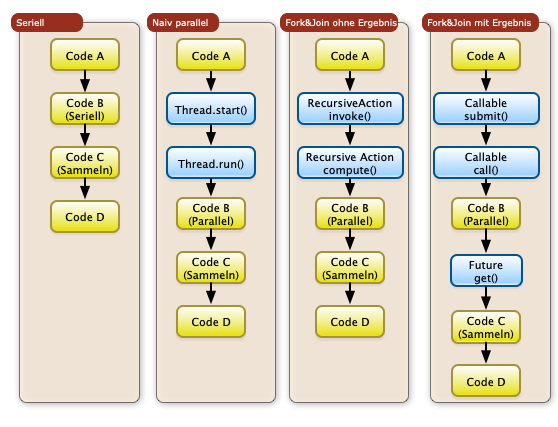
Steuerung des Grads der Parallelisieren
Java erlaubt es recht einfach viele Ausführungseinheiten (Threads) zu erzeugen. Das Betriebssystem wird diese Threads auf Hardwarethreads zuordnen. Das macht das Betriebssystem auch fast immer sehr gut. Erzeugt man aber zufiele ausführbare Threads kann der Rechner überlastet werden und ist kaum noch ansprechbar. Das bedeutet, dass Prozesse die mit dem Benutzer interagieren sollen nicht mehr unbedingt die CPU Zeit bekommen die sie benötigen.
Hat man viel, zu viele Softwarethreads und Prozesse wird das Betriebsystem auch noch ineffizient. Es muss die ganzen Zustandänderungen managen. Hier gibt es kritische Pfade und im Überlastungsfall zuwenig CPU-Zeit.
Das Fork & Join Framework erleichtert das professionelle Skalieren in dem es eine Threadpool anlegt und alle Tasks an freie Prozessoren im Threadpool vergibt. Hiermit übernimmt es eine Aufgaben des Betriebsystem und vermeidet eine Überlastung. Gibt man keinen Wert für den Pool an, wird die Anzahl aller Prozessoren im Rechner als Defaultwert verwendet.
Dies ist nur ein kleiner Ausschnitt aus dem Fork & Join Framwork. Wir betrachten hierzu die folgenden Klassen:
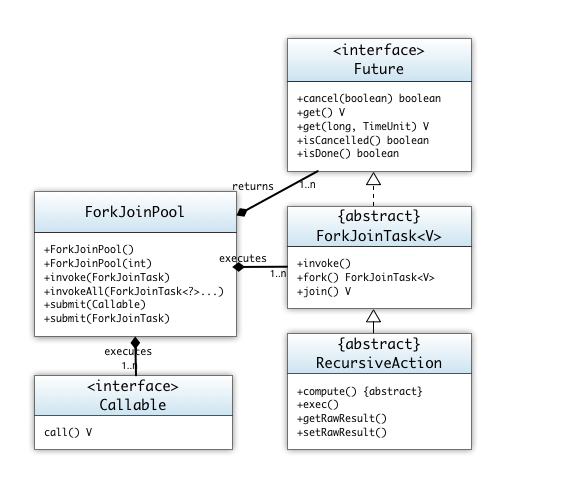
Die Klasse ForkJoinPool
Die Klasse java.util.concurrent.ForkJoinPool wurde im JDK 7 eingeführt.
In dieser Klasse werden eine Menge von Threads verwaltet und zur Ausführung von Task (Aufgaben) verwendet. Dies macht es dem Betriebsystem leichter die Threads auf die Prozessoren zu verteilen, da nicht beliebig viele Threads von Java erzeugt werden. Die Klasse ForkJoinPool verwaltet die Zuordnung der Task auf die konfigurierten (Software)threads.
Tasks können auf 3 Arten dem Framework übergeben werden:
| Aufrufe von ausserhalb | Aufruf innerhalb einer Berechnung | |
|---|---|---|
| asynchrone Ausführung | ForkJoinPool.execute(ForkJoinTask) | ForkJoinTask.fork() |
| warte auf Ergebnis | ForkJoinPool.invoke(ForkJoinTask) | ForkJoinTask.invoke() |
| asynchrone Ausführung mit Ergebnis | ForkJoinPool.submit(ForkJoinTask) ForkJoinPool.submit(Callable) |
ForkJoinTask.fork(ForkJoinTasks sind Futures) |
Die Implementierung wird zu einer RejectedExecutionException Ausnhame führen falls der Threadpool runtergefahren wird oder falls es keine Threads mehr in der VM gibt.
Interessante Konstruktoren:
- public ForkJoinPool(): default Konstruktor, erzeugt einen Pool mit so vielen Threads wie der Rechner Hyperthreads besitzt
- public ForkJoinPool(int parallelism): erzeugt einen Pool mit einer definierten Anzahl Threads
Paralleles Abarbeiten ohne Rückgabewerte
Ein Beispiel hierfür ist der Quicksort. Man kann parallel das linke und das rechte Teilintervall sortieren nachdem die Vorarbeit (seriell) erledigt wurde.
Hierzu nutzt man die abstrakte Klasse RecursiveAction die aus der abstrakten Klasse ForkJoinTask spezialisiert wird. Die Klasse ForkJoinPool kann Tasks die die Bedingungen der Klasse ForkJoinTask erfüllen, parallel ausführen. Hierzu gibt es in der Klasse die Methoden:
- invoke(): startet den Task in dem man sich gerade befindet
- invokeAll(ForkJoinTask<?> ... tasks): startet eine Liste von Tasks (wird im Quicksort verwendet)
Es verbleibt das Problem, dass man einen bestimmten Code ausführen möchte. Hierzu dient die abstrakte Klasse RecursiveAction. Sie besitzt eine abstrakte Methode:
- compute(): führt den Code aus. Diese Methode ist abstrakt!
|
Wie implementiert man so etwas?
|
Paralleles Abarbeiten mit Rückgabewerte
Die Aufgabe parallelisieren und als Aufgabe starten reicht oft nicht. Oft müssen die Ergebnisse entgegen genommen werden und dann rekursiv zu neuen Ergebnissen aggregiert werden.
Hierzu benötigt man einen Mechanismus der
- die Eingabeparameter für jede Aufgabe (Task) entgegennimmt
- die Aufgaben (Tasks) ausführt
- und die Ergebnisse erst zurückgibt wenn die Ergebnisse vorliegen
Die Schnittstelle Callable
Die Schnittstelle java.util.concurrent.Callable muss implementiert werden um die Ausgabeparameter einer Aufgabe (Task) entgegenzunehmen. Hierfür muss man
- einen generischen Typen wählen der das Ergebnis zur Verfügung stellt
- einen Konstruktor implementieren der alle Eingabeparameter entgegen nimmt.
- alle Parameter als Attribute implementiert
- die Methode V call() die das Ergebnis zurückliefert
Ein Beispiel auf der Programmierübung Ariadnefaden
public class SearchCallable implements Callable<List<Position>> {
Position von;
Position nach;
Ariadne4Parallel a;
/**
*
* @param a Instanz von Ariadne
* @param von Start
* @param nach Ziel
*/
SearchCallable(Ariadne4Parallel a,Position von, Position nach) {
this.a =a;
this.von = von;
this.nach = nach;
}
/**
* Führe Task in eigenem Thread aus und nutze Instanzvariablen
* als Parameter um Aufgabe auszuführen.
* @throws java.lang.Exception
*/
@Override
public List<Position> call() throws Exception {
return a.suche(von, nach);
}
}In diesem Beispiel ist das Ergebnis eine Liste von Positionen die den Web aus dem Labyrinth weisen.
Die Eingabeparameter sind ein Labyrinth, die Startposition und die Position mit dem Ausgang ais dem Labyrinth.
Die Schnittstelle Future
Die Schnittstelle Future erlaubt es das Ergebnis einer Aufgabe zu analysieren. Die Schnittstelle ist generisch und erlaubt es daher nur einen bestimmten Type einer Klasse auszulesen.
Die beiden wichtigsten Methoden der Schnittstelle sind:
- V get(): wartet falls notwendig auf das Beenden der Aufgabe und liefert das Ergebnis ab
- V get(long timeout, TimeUnit unit): wartet eine bestimmte Zeit auf auf ein bestimmtes Ergebnis
In der Schnittstellendefinition sind noch weitere Methoden zum Kontrollieren und Beenden von Aufgaben (Tasks) vorhanden.
Abschicken von Aufgaben (Tasks)
Die Klasse java.util.concurrent.ForkJoinPool verfügt über eine Methode
- public <T> ForkJoinTask<T> submit(Callable<T> task)
Diese Methode nimmt die Eingaben für die Aufgabe (Task) an solange es eine Spezialierung der Klasse Callable<T> ist. Das Ergebnis ist ein Objekt vom Typ ForkJoinTask. Die Klasse ForkJoinTask implementiert die Schnittstelle Future. Das Ergebnis der Aufgabe (Task) wird hier abgeliefert sobald die Aufgabe abgearbeitet ist.
|
Wie implementiert man so etwas?
|
- 1946 views
Aufgaben (Threads)
Aufgaben (Threads)Programmieraufgabe JoinAndSleep
Ziel der Aufgabe ist es drei Threads zu programmieren die auf das Beenden des anderen Warten und dann eine Zeit schlafen:
- Sie drucken jeden neuen Zustand auf der Konsole aus
- Als erstes nach ihrem Start warten sie bis ein anderer Thread auf den sie zeigen sich beendet hat. Zeigen sie auf keinen anderen Thread so gehen sie sofort über zum nächstens Schritt.
- Die Threads schlafen für eine vorgegebene Zeit in ms
- Die Threads beenden sich
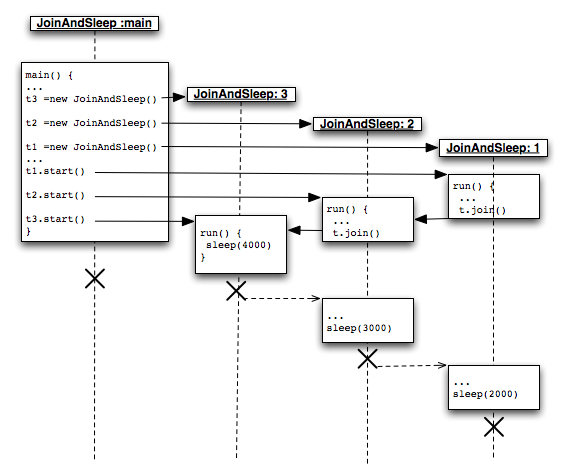
Die geforderte Aufgabe soll in einer Klasse implementiert werden
- Erweitern Sie die Klasse JoinAndSleep aus der Klasse Thread
- Attribute: Die Klasse hat ein Ganzzahlattribut sleep zur Verwaltung der Schlafzeit
- Die Klasse hat ein Ganzzahlattribut sleep zur Verwaltung der Schlafzeit
- Die Klasse hat eine Referenz auf ein Objekt der Klasse JoinAndSleep
- Konstruktor
- Der Konstruktor der Klasse erlaubt es die Schlafzeit zu übergeben und eine Referenz auf einen anderen Thread. Dies ist der Thread auf den gewartet werden soll.
- run() Methode: Diese Methode implementiert die oben genannte Semantik zum Warten und Schlafen
- Falls ein Thread gegeben ist soll auf sein Ende gewartet werden
- Anschliesend soll eine bestimmte Zeit geschlafen werden
- Fügen Sie zwischen allen Schritten Konsolenausgaben ein um den Fortschritt zu kontrollieren. Geben Sie hier immer auch den aktuellen Thread aus!
- main() Methode
- Erzeuge Thread 3: Er soll auf keinen Thread warten und dann 4000ms schlafen
- Erzeuge Thread 2: Er soll auf Thread 3 warten und dann 3000ms schlafen
- Erzeuge Thread 1: Er soll auf Thread 2 warten und dann 2000ms schlafen
- Starten Sie Thread 1
- Starten Sie Thread 2
- Starten Sie Thread 3
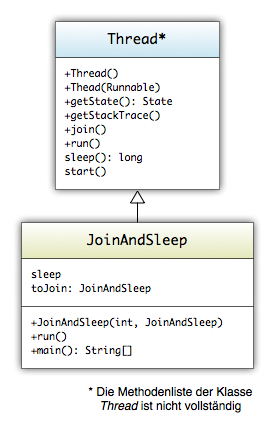
Hinweise:
Ich welchen Thread bin ich gerade?
- Die statische Methode Thread.currentThread() liefert einen Zeiger auf den aktuellen Thread
- Diesen kann man direkt ausdrucken
Wie warte ich auf einen anderen Thread?
Die Methode Thread.join() erlaubt auf das Beenden eines anderen Threads zu warten. Man muss auf eine InterruptedException vorbereitet sein, da man aufgeweckt werden kann:
Thread aThread;
...
try {
aThread.join();
} catch (InterruptedException e) {}
Wie lasse ich einen Thread schlafen?
Die Methode Thread.sleep() ist eine statische Methode. Man muss seinen eigenen Thread nicht kennen um ihn ruhen zulassen! Auch diese Methode kann eine InterruptedException werfen und muss mit einer Ausnahmebehandlung versehen werden:
try {
Thread.sleep(schlafen);
} catch (InterruptedException e) {}
Verständnisfragen
- Wer wartet hier auf wen?
- Ist dies an den Konsolenaufgaben zu erkennen?
- Woran erkenne ich bei den Konsolenausgaben, das der Code in einem eigenen Thread läuft?
- 11250 views
Lösungen (Threads)
Lösungen (Threads)Programmieraufgabe JoinAndSleep
package s2.thread;public class JoinAndSleep extends Thread{
/**
* Der Thread auf dessen Beendigung gewartet wird
*/
Thread joinIt;
/**
* Zeit in Millisekunden zum Schlafen
*/
int schlafen;
/**
* Der Konstruktor
* @param sleeptime Die Zeit in msdie der Thread schlafen soll
* @param toJoin der Thread auf den gewartet werden solll bis er beendet ist
*/
public JoinAndSleep(int sleeptime, Thread toJoin) {
joinIt = toJoin;
schlafen = sleeptime;
System.out.println("Thread: " + this + " erzeugt");
}
/**
* Die überschriebene Methode run() sie führt den Code aus
*/
public void run() {
System.out.println("Thread: " +Thread.currentThread() + " gestartet");
try {
if (joinIt!=null) {
joinIt.join();
System.out.println("Thread: " +Thread.currentThread()
+ " join auf " + joinIt + " fertig");
}
} catch (InterruptedException e) {}
System.out.println("Thread: " +Thread.currentThread()
+ " schlaeft jetzt fuer " + schlafen + "ms");
try {
Thread.sleep(schlafen);
} catch (InterruptedException e) {}
System.out.println("Thread: " +Thread.currentThread() + " endet");
}
/**
* Das Hauptprogramm
* @param args keine Parameter benoetigt!
*/
public static void main (String[] args) {
JoinAndSleep s3= new JoinAndSleep(2003, null);
JoinAndSleep s2= new JoinAndSleep(2002, s3);
JoinAndSleep s1= new JoinAndSleep(2001, s2);
s1.start();
s2.start();
s3.start();
}
}
- 4662 views
Lernziele (Threading)
Lernziele (Threading)|
|
Am Ende dieses Blocks können Sie:
|
Lernzielkontrolle
Sie sind in der Lage die folgenden Fragen zu beantworten: Fragen zur Nebenläufigkeit ( Multithreading)
Feedback
- 2877 views
Algorithmen
AlgorithmenZeitkomplexität von Algorithmen
Ziel ist immer die effiziente Ausführung von Algorithmen in einer minimalen Zeit, mit einem minimalen Aufwand (Ausführungsaufwand).
Der Ausführungsaufwand ist zu unterscheiden vom Aufwand den Algorithmus zu entwickeln, dem Entwicklungsaufwand. Langsame Anwendungen sind leider oft das Resultat von Implementierungen bei denen die Kostengründe für den Entwicklungsaufwand zu einem höheren Ausführungsaufwand führen...

Der Ausführungsaufwand hängt von vielen Faktoren ab. Viele Faktoren beruhen auf den unbekannten Komponenten des Ausführungssystems:
- Betriebssystem
- Prozessor, Prozessorgeschwindigkeit
- Hauptspeichergröße und - geschwindigkeit
- etc.
Die verlässlichste Art und Weise zur Beurteilung der Zeiteffizienz von Algorithmen ist die Abschätzung der Anzahl der Verarbeitungsschritte in Abhängigkeit von der Anzahl der Daten die zu verarbeiten sind.
| Ordnung "O" eines Algorithmus |
|---|
| Die funktionale Abhängigkeit (bzw. Proportionalität) zwischen der Zahl der Ausführungsprogrammschritte und der Zahl (n) der zu verarbeitenden Datenelemente |
Beispiele
- O(n): Ein Algorithmus hat eine lineare, proportionale Abhängigkeit von der Anzahl der Elemente. Verdoppelt sich die Anzahl der Elemente, so verdoppelt sich auch die Anzahl der Ausführungsschritte und damit die Ausführungsdauer
- O(n2): Die Anzahl der Ausführungsschritte steigt mit dem Quadrat der zu behandelten Element. Der Ausführungsaufwand vervierfacht sich bei der Verdopplung der Ausführungsschritte.
- O(log n): Die Anzahl der Ausführungsschritte steigt mit dem Logarithmus der Anzahl der Elemente
Hierdurch ergeben sich verschiedene Kategorien von Problemen:
Praktisch ausführbare Algorithmen
|
Algorithmen die auch bei einer sehr viel größeren Zahl von Elementen in einer akzeptablen Zeit ausgeführt werden können. Dies sind im Idealfall: O(n), O(log n), O (n*log n) Man zählt hierzu aber auch Algorithmen mit einer polynomialen Ordnung wie O(n2) oder O(n3). |
 |
Praktisch nicht mehr ausführbare Algorithmen
Praktisch nicht mehr ausführbare Algorithmen lassen sich nicht in akzeptabler Zeit bei größer werdenden Datenbeständen ausführen. Dies sind Algorithmen mit einer exponentiellen Ordnung. O(xn). Hierzu zählt auch das Problem des Handlungsreisenden mit einer Ordnung von O(n!).
- 7293 views
Rechenregeln für die Aufwandsbestimmung
Rechenregeln für die AufwandsbestimmungDie Rechenregeln für die Aufwände von Algorithmen erlauben dem Entwickler die Komplexitätsklasse eine Algorithmus abzuschätzen.
Hierzu muß der Entwickler zuerst bestimmen von welchem Parameter die Ausführungszeit primär abhängt.
 |
Ein Beispiel: Konvertierung von Bildern Der Algorithmus soll eine Anzahl von n Bildern mit einer mittleren Größe vom m Byte konvertieren.
Sehr wahrscheinlich wird die Anzahl der Bilder n nach dem bekanntmachen des Dienstes sehr schnell steigen. Die Größe m von Bildern, ist aber in der Vergangenheit durch neue Technologien, auch gestiegen. Es kann also sein, daß sich die Kriterien mit der Zeit ändern! |
Hierzu geht der Entwickler in zwei Schritten vor:
- Man bestimmt die Anzahl der auszuführenden Befehle eines Algorithmus in Abhängigkeit von den zu verarbeitenden Datenelementen n
- Man vereinfacht den Term mit dem Gesamtaufwand derart, dass der Term und jeder Teilterm in der gleichen Komplexitätsklasse bleibt
Am Ende bleibt dann ein einfacher Ausdruck für die Komplexitätsklasse übrig.
Klassen von Komplexität
- konstant: O(1)
- logarithmisch: O(log(n))
- linear: O(n)
- jenseits von linear: O(n*log(n))
- polynomial: O(n2), O(n3), O(n4) etc.
- exponentiell: O(kn)
Rechenregeln für einfache Betrachtungen
Gegeben sei eine Funktion f(n) mit dem Aufwand O(n). n sei die variable Anzahl der zu verarbeitenden Datenelemente
- Konstanten: Konstanten haben keinen Einfluss:
- O(f(n)+k) = O(f(n))+k = O(f(n)) für k konstant
- O(f(n)*k)=O(f(n))*k = O(f(n)) für k konstant
- O(k) = O(1)
- konstante Aufwände werden nicht einberechnet. Dies gilt für Multiplikation, sowie für die Addition.
- Nacheinander ausgeführte Funktion f und g
- Der Aufwand O(f(n)) sei größer als der Aufwand von O(g(n))
- O(f(n)+g(n))=O(f(n))+O(g(n)) = O(f(n))
- ... der größere Aufwand gewinnt.
- Ineinander geschachtelte Funktionen oder Programmteile wie Schleifen f(g(n))
- O(f(g(n))) = O(f(n))*O(g(n))
- der Aufwand multipliziert sich.
- Einschränkung: Hier wird davon ausgegangen, dass beide Schleifen von der gleichen Variablen abhängen!
Weitere Informationen
- bigocheatsheet.com: Know Thy Complexities!
- 5660 views
Vorbereitung Gruppenarbeit
Vorbereitung GruppenarbeitDie Vorlesung wird virtuell oder in einem Klassenraum gegeben. Sie müssen nichts vorbereiten fall die Vorlesung im Klassenraum gehalten wird, der Referent wird alles nötige zur Gruppenarbeit mitbringen!
Es wird eine Gruppenarbeit durchgeführt in der sich jede Gruppe einen Sortieralgorithmus erarbeitet und dem Kurs vorstellt. Hierzu ist es nützlich das Folgende zu haben:
1. Literatur
Das Skript ist hilfreich. Das Internet ist hilfreich. Ein Buch wie "Algorithmen und Datenstrukturen" von Ottmann und Wildmayer ist sehr hilfreich.
2. Didaktische Hilfsmittel
Sie werden den Algorithmus im Team diskutieren und Sie werden den Algorithmus im Kurs vorstellen müssen. Man benötigt etwas zum Sortieren was auf den Schreibtisch passt. Hier sind zwei "Lowtech" Optionen.
 |
Spielkarten: Sie haben eine Kardinalität (Ordnung). Sie müssen sortiert werden. Man kann Sie gut zeigen. Sie sind transportabel |
Noch besser sind Stifte!
und man hat meistens sowieso ein paar im Mäppchen... 😀 |
 |
Die genauen Anweisungen sind im Übungsteil des Skripts zu finden.
- 266 views
Suchalgorithmen
Suchalgorithmen |
Such- und Sortiervorgänge sind sehr häufige Aufgaben die in Anwendungen gelöst werden müssen. Suchen ist ein Vorgang der komplementär zum Sortieren ist. Datenbestände die vollständig oder teilweise sortiert sind, lassen sich wesentlich einfacher durchsuchen. Ungeordnete Datenbestände lassen sich lassen sich im schlechtesten Fall nur linear durchsuchen. Suchvorgänge lassen wie folgt kategorisieren:
|
Internes und externes Suchen
Man unterscheidet zwischen Suchvorgängen bei denen man den gesamten Datenbestand im Hauptspeicher verwalten kann (internes Suchen) und Suchvorgängen bei denen der Datenbestand nur teilweise in den Hauptspeicher geladen werden kann(externes Suchen).
Beim externen Suchen muss man also einen schnellen, aber begrenzten Hauptspeicher geschickt einsetzen um einen langsamen, aber kostengünstigeren Massenspeicher zu durchsuchen.
Die Unterscheidung zwischen den beiden Suchverfahren ist sehr wichtig für produktiv eingesetzte Anwendungen, in der Berechung der Zeitaufwände ist sie nicht hilfreich!
Ein Festplattenspeicher mag etwa 1000 mal langsamer als der Hauptspeicher eines Rechners sein. Dies macht bei einer echten Anwendung einen großen Unterschied. Bei der Berechnung der Zeitkomplexität wird dieser Faktor jedoch als "unbedeutend" weggekürzt.
Suchverfahren
- 7648 views
Sequentielle Suche (lineare Suche)
Sequentielle Suche (lineare Suche)Die sequentielle Suche beruht auf dem naiven Ansatz einen Datenbestand vollständig zu durchsuchen bis das passende Element gefunden wird. Dieses Verfahren nennt man auch erschöpfende Suche oder im englischen das Greedy-Schema (engl. für gefräßig). Der Algorithmus für das Durchsuchen eines Felds ist der folgende:
- Spezifiziere Suchschlüssel
- Vergleiche jedes Element mit dem Suchschlüssel
- Erfolgsfall: Liefere Indexposition beim ersten Auffinden des Objekts und beende das Suchen
- Kein Erfolg: Gehe zum nächsten Objekt und vergleiche es.
- Gib eine Meldung über das erfolglose Suchen zurück wenn das Ende des Datenbestands erreicht wurde, ohne daß, das Objekt gefunden wird. Dies kann eine java-Ausnahme sein oder ein spezieller Rückgabewert (z.Bsp .1)
Der Aufwand für diesen Algorithmus ist linear, also O(n). Die Anzahl der nötigen Vergleichsoperationen hängt direkt von der Anzahl der Elemente im Datenbestand ab. Im statischen Mittel sind dies n/2 Vergleiche.
Sequentielle Suche in einem unsortierten Datenbestand
In diesem Fall muss bei jeder Suche der gesamte Datenbestand durchlaufen werden bis ein Element gefunden wurde
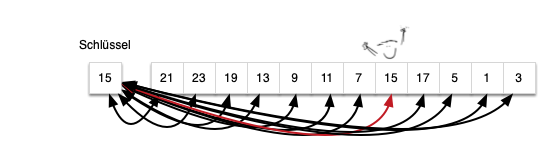
Beispiel einer Javaimplementierung
Die Methode sequentielleSuche() durchsucht ein Feld von 32 Bit Ganzzahlen nach einem vorgegebenen Schlüssel schluessel und gibt den Wert -1 zurück wenn kein Ergebnis gefunden wird.
public static int sequentielleSuche() (int[] feld, int schluessel) {
int suchIndex = 0;
while (suchIndex< feld.length && feld[suchIndex] != schluessel) suchIndex++;
if (suchIndex == feld.length) suchindex = -1; // Nichts gefunden
return suchindex;
}
Sequentielle Suche in einem sortierten Datenbestand
Bei einem sortierten Datenbestand kann man die Suche optimieren in dem man sie abbricht so bald man weiß, das die folgenden Elemente alle größer bzw. kleiner als das gesucht Element sind. Man muss also nicht das Feld vollständig durchlaufen. Hierdurch lässt sich Zeit sparen. Der durchschnittliche Aufwand von n/2 bleibt jedoch ein linearer Aufwand.
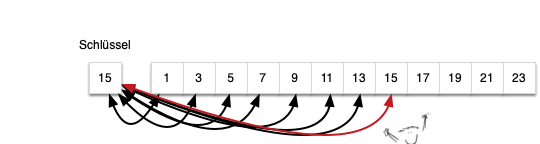
Beispiel einer Javaimplementierung
Die Methode sequentielleSuche() durchsucht ein Feld von 32 Bit Ganzzahlen nach einem vorgegebenen Schlüssel schluessel und gibt den Wert -1 zurück wenn kein Ergebnis gefunden wird.
public static int sequentielleSuche() (int[] feld, int schluessel)
int suchIndex = 0;
while (suchIndex< feld.length && feld[suchIndex] < schluessel) suchIndex++;
if ((suchindex < feld.length) && (feld[suchIndex] == feld[schluessel]))
return suchindex; // Erfolg
else return -1; //kein Erfolg
}- 25858 views
Binäre Suche
Binäre SucheDie binäre Suche erfolgt nach dem "Teile und Herrsche" Prinzip (divide et impera) durch Teilen der zu durchsuchenden Liste.
Voraussetzung: Die Folge muss steigend oder fallend sortiert sein!
Der Algorithmus lässt sich sehr gut rekursiv beschreiben:
Suche in einer sortierten Liste L nach einem Schlüssel k:
- Beende die Suche erfolglos wenn die Liste leer ist
- Nimm das Element auf der mittleren Position m der Liste und Vergleiche es mit dem Schlüssel
- Falls der Schlüssel k kleiner als dasElement L[m] is (k<L[m]) durchsuche die linke Teilliste bis zum Element L[m]
- Falls der Schlüssel k größer als dasElement L[m] is (k>L[m]) durchsuche die rechte Teilliste vom Element L[m] bis zum Ende
- Beende die Suche wenn der Schlüssel k gleich L[m] ist (k=L[m])
Das binäre Suchen ist ein Standardverfahren der Informatik da es sehr effizient ist. Der Aufwand beträgt selbst im ungünstigsten Fall O(N)=log2(N).
Im günstigsten Fall ist der Aufwand O(N)=1 da eventuell der gesuchte Schlüssel sofort gefunden wird.
Beispiel einer binären Suche
Das folgende Feld hat 12 Elemente zwischen 1 und 23. Es wird ein Element mit dem Wert 15 gesucht. Zu Beginn ist das Suchintervall das gesamte Feld von Position 0 (links) bis 11 (rechts). Der Vergleichswert (mitte) wird aus dem arithmetischen Mittel der Intervallgrenzen berechnet.
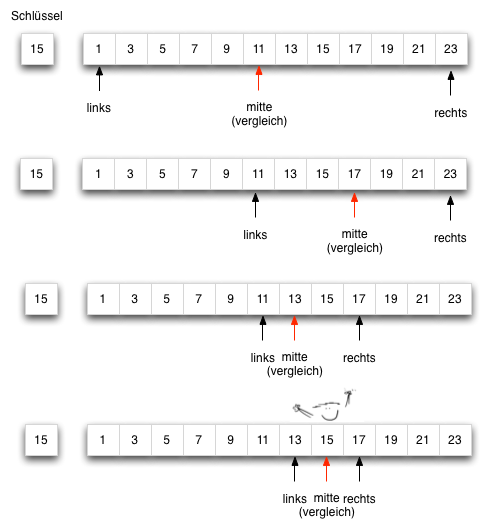
Beispielimplementierung in Java
Die Methode binaerSuche() sucht einen Kandidaten in einem aufsteigend sortierten Feld von Ganzzahlen. Das Hauptprogramm erzeugt ein Feld mit der Größe 200 und aufsteigenden Werten
public class Binaersuche {
int[] feld;
/**
*
* @param feld: Das zu durchsuchende Feld
* @param links: linker Index des Intervalls
* @param rechts: rechter Index des Intervalls
* @param kandidat: der zu suchende Wert
*/static void binaerSuche(int[] feld, int links,int rechts, int kandidat) {
int mitte;
do{
System.out.println("Intervall [" + links +
"," + rechts + "]");
mitte = (rechts + links) / 2;
if(feld[mitte] < kandidat){
links = mitte + 1;
} else {
rechts = mitte - 1;
}
} while(feld[mitte] != kandidat && links <= rechts);
if(feld[mitte]== kandidat){
System.out.println("Position: " + mitte);
} else {
System.out.println("Wert nicht vorhanden!");
}
}
public static void main(String[] args) {
int groesse=200;
int[] feld = new int[groesse];
for (int i=0; i<feld.length;i++)
feld[i] = 2*i; //Feld besteht aus geraden Zahlen
System.out.println("Suche feld["+ 66 + "]=" + feld[66]);
binaerSuche(feld, 0,(feld.length-1), feld[66]);
}
}
Programmausgabe auf Konsole:
Suche feld[66]=132
Intervall [0,199]
Intervall [0,98]
Intervall [50,98]
Intervall [50,73]
Intervall [62,73]
Intervall [62,66]
Intervall [65,66]
Intervall [66,66]
Position: 66
Tipp: Nutzen Sie Arrays.binarySearch()
Die Systemklasse Arrays bietet nützliche Methoden zum Arbeiten mit Feldern an. Nutzen Sie die überladene, statische Methode Arrays.binarySearch() zum Suchen in einem Feld.
Das funktioniert natürlich nur in einem sortierten Feld. Dafür gibt es ja die überladene, statische Methode Arrays.sort()...
Ein Beispiel mit der main() Methode von oben:
public static void main(String[] args) {
int groesse=200;
int[] feld = new int[groesse];
for (int i=0; i<feld.length;i++)
feld[i] = 2*i; //Feld besteht aus geraden Zahlen
System.out.println("Suche feld["+ 66 + "]=" + feld[66]);
Arrays.sort(feld);
int ergebnis = Arrays.binarySearch(feld,feld[66]);
}
Weiterführende Quellen und Beispiele
- 39451 views
Wieso Feldgröße / 3
Wieso teile ich meine groesse = 200 durch 3 und nicht durch 2? der suchalgorithmus fängt doch in der Mitte an oder ist mit der ersten Ausgabe etwas anderes gemeint?
- Log in to post comments
Beispielanwendung zum Suchen
Beispielanwendung zum SuchenDas folgende Programm zeigt eine sequentielle und eine binäre Suche in einem Feld mit zufälligen Werten.
Die Variable groesse erlaubt es die Größe des Felds zu verändern. Mit dem Nanotimer werden die benötigten Zeiten gemessen. Vergleichen Sie die Zeitaufwände für das sequentielle und das binäre Suchen mit dem Zeitaufwand für das Sortieren mit der Hilfklasse Arrays!
package s2.sort;
import java.util.Arrays;
/**
*
* @author sschneid
* @version 1.0
*/
public class Suchen {
public static int[] feld;
public static int groesse = 10000000;
/**
* Hauptprogramm
* @param args
*/
public static void main(String[] args) {
erzeugeFeld();
int suchwert =feld[groesse-2];
System.out.println("Suche feld["+ (groesse-2) +"] = " + suchwert);
sucheSequentiell(suchwert);
sortiere();
binaereSucheSelbst(suchwert);
binaereSuche(suchwert);}
/**
* Erzeuge ein Feld mit Zufallszahlen
*/
public static void erzeugeFeld() {
feld = new int[groesse];
for (int i=0; i<feld.length;i++) {
feld[i]=(int)(Math.random() * (double)Integer.MAX_VALUE);
}
System.out.println("Feld mit "+ groesse + " Elementen erzeugt.");
}
/**
* Suche sequentiell einen Wert in einem unsortierten Feld
* @param suchwert der gesuchte Wert
*/
public static void sucheSequentiell(int suchwert) {
System.out.println("Sequentielle Suche nach Schlüssel");
long t = System.nanoTime();
int i=0;
while ( (i<groesse) && (suchwert != feld[i])) i++;
t = (System.nanoTime() -t)/1000000;
if (i== groesse) {
System.out.println(" Der Wert: " + suchwert +
" wurde nicht gefunden");
}
else {
System.out.println(" Der Suchwert wurde auf Position " + i +
" gefunden");
}
System.out.println(" Dauer sequentielle Suche: " + t +"ms");
}
/**
* Sortiere ein Feld mit der Klasse Arrays und messe die Zeit
* @param suchwert der gesuchte Wert
*/
public static void sortiere() {
System.out.println("Sortieren mit Arrays.sort()");
long t = System.nanoTime();
Arrays.sort(feld);
t = (System.nanoTime() -t)/1000000;
System.out.println(" Feld sortiert in " + t +" ms");
}
/**
* Suche binär einen Wert in einem sortierten Feld
* @param suchwert der gesuchte Wert
*/
public static void binaereSucheSelbst(int suchwert) {
System.out.println("Selbstimplementierte binäre Suche");
long t = System.nanoTime();
int intervall = (feld.length+1)/2;
int pos = intervall;
while ((intervall > 1) && (feld[pos] != suchwert)) {
intervall =(intervall+1)/2;
if ((feld[pos] > suchwert)) {pos -= intervall;}
else {pos += intervall;}
}
t = (System.nanoTime() -t);
if (feld[pos]== suchwert) {
System.out.println(" Der Suchwert wurde auf Position " +
pos +" gefunden");
}
else {
System.out.println(" Der Wert: " + suchwert +
" wurde nicht gefunden");
}
System.out.println(" Dauer binäre Suche " + (t/1000000) +"ms" +
" (" + t + " ns)");
}
/**
* Suche binär einen Wert in einem sortierten Feld
* Nutze die binäre Suchmethode der Klasse Arrays
* @param suchwert der gesuchte Wert
*/
public static void binaereSuche(int suchwert) {
System.out.println("Binäre Suche mit Arrays.binarySearch()");
long t = System.nanoTime();
int pos = Arrays.binarySearch(feld, suchwert);
t = (System.nanoTime() -t);
System.out.println(" Der Suchwert wurde auf Position " +
pos +" gefunden");
System.out.println(" Dauer binäre Suche " + (t/1000000) +
"ms" + " (" + t + " ns)");
}}
Klasse in github.
Typische Konsolenausgabe:
Feld mit 10000000 Elementen erzeugt.
Suche feld[9999998] = 1719676120
Sequentielle Suche nach Schlüssel
Der Suchwert wurde auf Position 9999998 gefunden
Dauer sequentielle Suche: 28ms
Sortieren mit Arrays.sort()
Feld sortiert in 1296 ms
Selbstimplementierte binäre Suche
Der Suchwert wurde auf Position 8008593 gefunden
Dauer binäre Suche 0ms (6000 ns)
Binäre Suche mit Arrays.binarySearch()
Der Suchwert wurde auf Position 8008593 gefunden
Dauer binäre Suche 0ms (11000 ns)
- 8123 views
Sortieralgorithmen
SortieralgorithmenIn diesem Abschnitt gehen wir davon aus, dass die zu sortierenden Datensätze in einem Feld f der Größe N in aufsteigender Reihenfolge sortiert werden. Die Feldelemente sollen in aufsteigender Reihenfolge sortiert werden.
Das Feld f dient als Eingabe für die Folge des Sortierverfahrens sowie als Ausgabedatenstruktur. Die Elemente müssen also innerhalb des Folge umsortiert werden. Nach dem Sortieren gilt für das Feld f:
f[1].wert <= f[2].wert ...<=f[N].wert
Beispiel
|
Unsortierte Folge mit N=7 Elementen:
|
Sortierte Folge mit N=7 Elementen
|
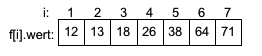
Bewertungskriterien
Bei der Bewertung der der Sortieralgorithmen wird jeweils in Abhängigkeit der Größe des zu sortierenden Feldes
- die Anzahl der Schlüsselvergleiche C (englisch comparisons) und
- die Anzahl der Bewegungen M (englisch: movements) der Elemente
gemessen.
Bei diesen zwei Parametern interessieren
- der beste Fall (die wenigsten Operationen)
- der schlechteste Fall (die meisten Operationen)
- der durchschnittliche Fall
Schlüsselvergleiche sowie Bewegungen tragen beide zur Gesamtlaufzeit bei. Man wählt den größeren der beiden Werte um eine Abschätzung für die Gesamtlaufzeit zu erlangen.
Stabilität von Sortierverfahren
Ein weiteres Kriterium für die Bewertung von Sortiervorgängen ist die Stabilität.
| Definition: Stabiles Sortierverfahren |
|---|
| Ein Sortierverfahren ist stabil wenn nach dem Sortieren die relative Ordnung von Datensätzen mit dem gleichen Sortierschlüssel erhalten bleibt. |
Beispiel: Eine Folge von Personen die ursprünglich nach der Mitarbeiternummer (id) sortiert. Diese Folge soll mit dem Nachnamen als Sortierschlüssel sortiert werden.
Im folgenden Beispiel wurde ein stabiles Sortierverfahren angewendet. Die relative Ordnung der beiden Personen mit dem Namen "Schmidt" bleibt erhalten. Der Mitarbeiter mit der Nummer 18 bleibt vor dem Mitarbeiter mit der Nummer 21.
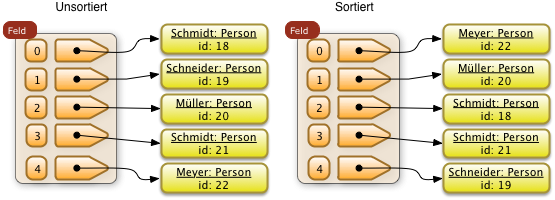
Bei nicht stabilen Sortierverfahren bleibt diese relative Ordnung nicht unbedingt erhalten. Hier könnte eine sortierte Folge so aussehen:
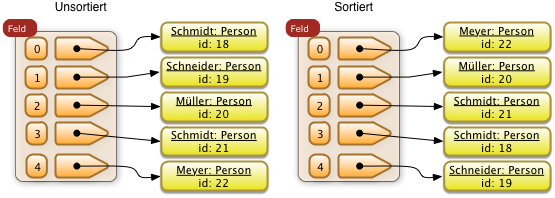
Stabile Sortierverfahren erlauben das Sortieren nach mehreren Prioritäten da eine Vorsortierung erhalten wird.
Im oben gezeigten Beispiel kann man eine Folge
- primär nach Nachnamen sortierten und
- sekundär nach der Personalnummer (id).
Man sortiert die Personen zuerst nach dem Kriterium mit der niedrigen Priorität. Dies ist hier die Personalnummer. Diese Vorsortierung war schon gegeben. Anschließend sortiert man nach dem wichtigeren Kriterium, dem Nachnamen. Die so entstandene Folge ist primär nach Nachnamen sortieret, sekundär nach Personalnummer.
- 17871 views
Beispielprogramme
BeispielprogrammeDie folgenden Beispielprogramme erlauben das Testen von unterschiedlichen Sortieralgorithmen.
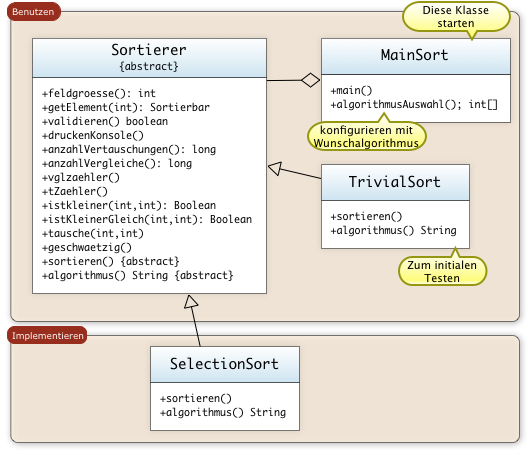
Hinweis: Die Implementierungen der Sortieralgorithmen selbst sind in den Abschnitten der Algorithmen zu finden. Im Hauptprogramm MainSort kann man durch Instanziieren einen Sortieralgorithmus wählen.
Arbeitsanweisung
Kopieren, Bauen und Starten der Referenzimplementierung
- Legen Sie in Ihrer Entwicklungsumgebung das Paket s2.sort an
- Kopieren Sie die Quellen der unten aufgeführten Klassen (inklusive Trivialsort) in Ihre Entwicklungsumgebung. Achten Sie darauf, daß alle Klassen im Paket s2.sort angelegt werden.
- Übersetzen Sie alle Klassen
- Starten Sie Anwendung durch Aufruf der Klasse s2.sort.MainSort
Auf der Kommandozeile geschieht das mit dem Befehl
$ java s2.sort.MainSort
Die Konsolenausgabe dieser Anwendung ist:
Phase 1: Einfacher Test mit 6 Elementen Algorithmus: Sortiere drei Werte Unsortiert: feld[0]=6 feld[1]=2 feld[2]=4 feld[3]=3 feld[4]=5 feld[5]=7 Zeit(ms): 0 Vergleiche: 2 Vertauschungen: 2. Fehler in Sortierung Sortiert: feld[0]=2 feld[1]=4 feld[2]=6 feld[3]=3 feld[4]=5 feld[5]=7 Keine Phase 2 (Stresstest) aufgrund von Fehlern...
Der Trivialsort hat leider nur die Schlüssel auf der Position 0 und 1 sortiert.
Effizienz des Algorithmus messen
Das Hauptprogramm MainSort wird bei einer korrekten Sortierung eines Testfelds mit 6 Werten automatisch in die zweite Phase eintreten.
Hier wird es ein Feld mit 5 Werten und Zufallsbelegungen Generieren und Sortieren.
Die Feldgröße wird dann automatisch verdoppelt und es wird eine neue Sortierung mit neuen Zufallswerten durchgeführt. Dies wird solange wiederholt bis ein Sortiervorgang eine voreingestellte Maximalzeit (3 Sekunden) überschritten hat.
Mit Hilfe dieser Variante kann man die benötigte Zeit pro Anzahl sortierter Elemente beobachten und die Effizienz des gewählten Algorithmus abschätzen.
Beim Sortieren durch Auswahl ergibt die die folgende Konsolenausgabe:
Phase 1: Einfacher Test mit 6 Elementen Algorithmus: Sortieren durch Auswahl Unsortiert: feld[0]=6 feld[1]=2 feld[2]=4 feld[3]=3 feld[4]=5 feld[5]=7 Zeit(ms): 0 Vergleiche: 15 Vertauschungen: 5. Korrekt sortiert Sortiert: feld[0]=2 feld[1]=3 feld[2]=4 feld[3]=5 feld[4]=6 feld[5]=7 Phase 2: Stresstest Der Stresstest wird beendet nachdem mehr als 3 Sekunden benötigt werden. Maximalzeit(s): 3 Sortieren durch Auswahl. Feldgroesse: 10 Zeit(ms): 0 Vergleiche: 45 Vertauschungen: 9. Korrekt sortiert Sortieren durch Auswahl. Feldgroesse: 20 Zeit(ms): 0 Vergleiche: 190 Vertauschungen: 19. Korrekt sortiert Sortieren durch Auswahl. Feldgroesse: 40 Zeit(ms): 0 Vergleiche: 780 Vertauschungen: 39. Korrekt sortiert Sortieren durch Auswahl. Feldgroesse: 80 Zeit(ms): 1 Vergleiche: 3160 Vertauschungen: 79. Korrekt sortiert Sortieren durch Auswahl. Feldgroesse: 160 Zeit(ms): 5 Vergleiche: 12720 Vertauschungen: 159. Korrekt sortiert Sortieren durch Auswahl. Feldgroesse: 320 Zeit(ms): 14 Vergleiche: 51040 Vertauschungen: 319. Korrekt sortiert Sortieren durch Auswahl. Feldgroesse: 640 Zeit(ms): 14 Vergleiche: 204480 Vertauschungen: 639. Korrekt sortiert Sortieren durch Auswahl. Feldgroesse: 1280 Zeit(ms): 19 Vergleiche: 818560 Vertauschungen: 1279. Korrekt sortiert Sortieren durch Auswahl. Feldgroesse: 2560 Zeit(ms): 26 Vergleiche: 3275520 Vertauschungen: 2559. Korrekt sortiert Sortieren durch Auswahl. Feldgroesse: 5120 Zeit(ms): 84 Vergleiche: 13104640 Vertauschungen: 5119. Korrekt sortiert Sortieren durch Auswahl. Feldgroesse: 10240 Zeit(ms): 575 Vergleiche: 52423680 Vertauschungen: 10239. Korrekt sortiert Sortieren durch Auswahl. Feldgroesse: 20480 Zeit(ms): 1814 Vergleiche: 209704960 Vertauschungen: 20479. Korrekt sortiert
Warnung
- Diese zweite Phase funktioniert nicht mit dem Trivialsort. Hier werden nur zwei Vergleiche und zwei Vertauschnungen durchgeführtImplementieren der eigenen Algorithmen
Nutzen Sie die vorgebenen Klassen zum Testender eigener Algorithmen
- Erzeugen Sie eine eigene Klasse für den Sortieralgorithmus
- Sie können die Klasse TrivialSort übernehmen.
- Ändern Sie den Klassennamen
- Ändern Sie in der Methode algorithmus() den Namen des Algorithmus
- Implementieren Sie die Methode sortieren(int von, int bis) die ein bestimmtes Intervall der Folge sortiert
- Sie können die Klasse TrivialSort übernehmen.
- Ändern Sie in der Klasse MainSort in der Methode algorithmusWahl() den benutzten Algorithmus.
- Tipps: Nutzen Sie die Infrastruktur der Oberklasse Sortierer beim Testen
- istKleiner(int a, int b), istKleinerGleich(int a, int b) : Vergleichen Sie die Werte des Feldes indem Sie bei diesen beiden Methoden den jeweiligen Index angeben. Es wird ein Zähler gepflegt der die Anzahl der gesamten Vergleiche beim Sortiervorgang zählt!
- tausche(int i, int j): tauscht die Werte auf Index i mit dem Wert von Index j. Es wird ein Zähler gepflegt der die Anzahl der Vertauschungen zählt
- tZaehler(): Inkrementiert die Anzahl der Vertauschungen falls nicht die Methode tausche() verwendet wurde. Dieser Zähler ist multi-threading (mt) save!
- vglZaehler(): Inkrementiert die Anzahl der Vergleiche falls nicht die Methoden istKleiner() oder istKleinerGleich() verwendet werden. Dieser Zähler ist mt-save!
- druckenKonsole() : druckt das Feld in seiner aktuellen Sortierung aus.
- Tracing: Ihre Klasse mit dem Sortieralgorithmus erbt eine statische boolsche Variable geschwaetzig. Sie können diese Variable jederzeit setzem mit geschwaetzig=true. Es werden alle Vertauschungen und Vergleiche auf der Konsole ausgegeben:
Beim TrivialSort führt das Setzen dieser Variable zur folgenden Konsolenausgabe:
Phase 1: Einfacher Test mit 6 Elementen Algorithmus: Sortiere drei Werte Unsortiert: feld[0]=6 feld[1]=2 feld[2]=4 feld[3]=3 feld[4]=5 feld[5]=7 Vergleich:feld[1]<feld[0] bzw. 2<6 Getauscht:feld[0<->1];f[0]=2;feld[1]=6 Vergleich:feld[2]<feld[1] bzw. 4<6 Getauscht:feld[1<->2];f[1]=4;feld[2]=6 Zeit(ms): 0 Vergleiche: 2 Vertauschungen: 2. Fehler in Sortierung Sortiert: feld[0]=2 feld[1]=4 feld[2]=6 feld[3]=3 feld[4]=5 feld[5]=7 Keine Phase 2 (Stresstest) aufgrund von Fehlern...
Quellcode
Klasse MainSort.java
Warnung: Diese Klasse lädt die Algorithmen dynamisch. Sie funktioniert nur wenn
- Die Namen der Klassen beibehalten werden. Die Namen der Klassen werden als Zeichenkette angegeben. Die Namen müssen vorhanden sein und die Klasse muss übersetzt worden sein.
- Das Paket s2.sort bleibt. Wenn die Paketstruktur geändert wird muss auch die fett gedruckte Zeichenkette angepasst werden.
Die Klasse MainSort.java in GitHub.
Klasse Sortieren.java
Die Klasse Sortierer ist eine abstrakte Klasse die die Infrastruktur zum Sortieren zur Verfügung stellt.
- Sie verwaltet ein Feld von ganzen Zahlen (int).
- Sie stellt Operationen zum Vergleichen und Tauschen von Elementen zur Verfügung
- Sie hat Zähler für durchgeführte Vertauschungen
- Sie kann ein Feld auf korrekte Sortierung prüfen
- Sie kann das Feld mit neuen Zufallszahlen belegen
- Sie hat eine statische Variable geschwaetzig mit der man bei Bedarf jeden Vergleich und jede Vertauschung auf der Kommandozeile dokumentieren kann.
- Die Klasse verwendete mt-sichere Zähler vom Typ AtomicInteger bei parallelen Algorithmen. Diese Zähler sind langsamer aber Sie garantieren ein atomares Inkrement.
Die Klasse Sortierer.java in GitHub.
Die Klasse TrivialSort.java
Diese Klasse ist ein Platzhalter der nur die beiden ersten Elemente eines Intervalls sortieren kann.
Das Programm dient zum Testen des Beispiels und es zeigt den Einsatz der schon implementierten istKleiner() und tausche() Methoden die von der Oberklasse geerbt werden.
Die Klasse TrivialSort.java in GitHub.
- 8909 views
MainSort.java: Ein Testprogramm
MainSort.java: Ein TestprogrammKlasse MainSort.java
Warnung: Diese Klasse lädt die Algorithmen dynamisch. Sie funktioniert nur wenn
- Die Namen der Klassen beibehalten werden. Die Namen der Klassen werden als Zeichenkette angegeben. Die Namen müssen vorhanden sein und die Klasse muss übersetzt worden sein.
- Das Paket s2.sort bleibt. Wenn die Paketstruktur geändert wird muss auch die fett gedruckte Zeichenkette angepasst werden.
package s2.sort;
import java.lang.reflect.Constructor;
import java.lang.reflect.InvocationTargetException;
import java.util.Arrays;
/**
*
* @author sschneid
* @version 2.0
*/
public class MainSort {
private static String algorithmusName;
/**
*
* Das Hauptprogramm sortiert sechs Zahlen in Phase 1
* Phase 2 wird nur aufgerufen wenn der Sortieralgorithmus
* für die erste Phase korrekt war
* @param args
*/
public static void main(String[] args) {
if (args.length > 0)
algorithmusName = args[0];
else
algorithmusName="";
int zeit = 3;
System.out.println("Phase 1: Einfacher Test mit 6 Elementen");
boolean erfolg = phase1();
if (erfolg) {
System.out.println ("Phase 2: Stresstest");
System.out.print("Der Stresstest wird beendet nachdem mehr ");
System.out.println("als " + zeit + " Sekunden benötigt werden.");
phase2(zeit);
}
else {System.out.println("Keine Phase 2 (Stresstest) " +
"aufgrund von Fehlern...");}
}
/**
* Auswahl des Sortieralgorithmus
* @ param das zu sortierende Feld
* @ return der Sortieralgorithmus
*/
public static Sortierer algorithmusWahl(int[] feld) {
Sortierer sort= null;
// Wähle ein Sortieralgorithmus abhängig von der
// gewünschten Implementierung
String nameSortierKlasse;
if (algorithmusName.equals("")) {
algorithmusName = "TrivialSort";
//algorithmusName = "SelectionSort";
//algorithmusName = "InsertionSort";
//algorithmusName = "BubbleSort";
//algorithmusName = "QuickSort";
//algorithmusName = "QuickSortParallel";
}
Class<?> meineKlasse;
Constructor<?> konstruktor;
try {
// Dynamisches Aufrufen einer Klasse
// Hole Metainformation über Klasse
meineKlasse = Class.forName("s2.sort."+ algorithmusName);
// Hole alle Konstruktoren
Constructor[] konstruktoren = meineKlasse.getConstructors();
// Nimm den Ersten. Es sollte nure einen geben
konstruktor = konstruktoren[0];
// Erzeuge eine Instanz dynamisch
sort = (Sortierer) konstruktor.newInstance((Object)feld);
} catch (ClassNotFoundException ex) {
System.out.println("Klasse nicht gefunden. Scotty beam me up");
} catch (InstantiationException ex) {
System.out.println("Probleme beim Instantieren. Scotty beam me up");
} catch (IllegalAccessException ex) {
System.out.println("Probleme beim Zugriff. Scotty beam me up");
} catch (SecurityException ex) {
System.out.println("Sicherheitsprobleme. Scotty beam me up");
} catch (IllegalArgumentException ex) {
System.out.println("Falsches Argument. Scotty beam me up");
} catch (InvocationTargetException ex) {
System.out.println("Falsches Ziel. Scotty beam me up");
}
//sort.geschwaetzig = true;
return sort;
}
/**
* Sortiere 6 Zahlen
* @return wurde die Folge korrekt sortiert?
*/
public static boolean phase1() {
long anfangszeit = 0;
long t = 0;
int[] gz = new int[6];
gz[0] = 6;
gz[1] = 2;
gz[2] = 4;
gz[3] = 3;
gz[4] = 5;
gz[5] = 7;
Sortierer sort = algorithmusWahl(gz);
System.out.println("Algorithmus: " + sort.algorithmus());
System.out.println("Unsortiert:");
sort.druckenKonsole();
anfangszeit = System.nanoTime();
sort.sortieren(0, gz.length - 1);
t = System.nanoTime() - anfangszeit;
System.out.print(
" Zeit(ms): " + t / 1000000
+ " Vergleiche: " + sort.anzahlVergleiche()
+ " Vertauschungen: " + sort.anzahlVertauschungen());
boolean erfolg = sort.validierung();
if (erfolg) {System.out.println(". Korrekt sortiert");}
else {
System.out.println(". Fehler in Sortierung");
}
System.out.println("Sortiert:");
sort.druckenKonsole();
return erfolg;
}
/**
* Sortieren von zufallsgenerierten Feldern bis eine maximale
* Zeit pro Sortiervorgang in Sekunden erreicht ist
* @param maxTime
*/
public static void phase2(int maxTime) {
// Maximale Laufzeit in Nanosekunden
long maxTimeNano = (long) maxTime * 1000000000L;
long t = 0;
// Steigerungsfaktor für Anzahl der zu sortierenden Elemente
double steigerung = 2.0; // Faktor um dem das Feld vergrößert wird
int anzahl = 5; // Größe des initialen Felds
long anfangszeit;
int[] gz;
Sortierer sort;
System.out.println("Maximalzeit(s): " + maxTime);
while (t < maxTimeNano) {
// Sortiere bis das Zeitlimit erreicht ist
anzahl = (int) (anzahl * steigerung);
// Erzeugen eines neuen Feldes
gz = new int[anzahl];
for (int i = 0; i < gz.length; i++) {
gz[i] = 1;
}
sort = algorithmusWahl(gz);
sort.generiereZufallsbelegung();
sort.zaehlerRuecksetzen();
anfangszeit = System.nanoTime();
sort.sortieren(0, gz.length - 1);
t = System.nanoTime() - anfangszeit;
System.out.print(
sort.algorithmus() +
". Feldgroesse: " + anzahl + " Zeit(ms): " + t / 1000000 +
" Vergleiche: " + sort.anzahlVergleiche() +
" Vertauschungen: " + sort.anzahlVertauschungen());
if (sort.validierung()) {System.out.println(". Korrekt sortiert");}
else {
System.out.println(". Fehler in Sortierung");
break;
}
sort.zaehlerRuecksetzen();
}
}
}Die Quellen bei github.
- 4012 views
MainSort unvollständig
Die Implementierung der MainSort ist auf dieser Seite nicht ganz vollständig. Die Imports und ein Return-Statement fehlen. Auf github ist die Version richtig :-)
- Log in to post comments
Sortierer.java
Sortierer.javaDie Klasse Sortierer ist eine abstrakte Klasse die die Infrastruktur zum Sortieren zur Verfügung stellt.
- Sie verwaltet ein Feld von ganzen Zahlen (int).
- Sie stellt Operationen zum Vergleichen und Tauschen von Elementen zur Verfügung
- Sie hat Zähler für durchgeführte Vertauschungen
- Sie kann ein Feld auf korrekte Sortierung prüfen
- Sie kann das Feld mit neuen Zufallszahlen belegen
- Sie hat eine statische Variable geschwaetzig mit der man bei Bedarf jeden Vergleich und jede Vertauschung auf der Kommandozeile dokumentieren kann.
- Die Klasse verwendete mt-sichere Zähler vom Typ AtomicInteger bei parallelen Algorithmen. Diese Zähler sind langsamer aber Sie garantieren ein atomares Inkrement.
Implementierung
package s2.sort;
import java.util.concurrent.atomic.AtomicInteger;
/**
*
* @author sschneid
* @version 2.1
*/
public abstract class Sortierer {
/**
* Das zu sortierende Feld
*/
protected int[] feld;
private int maxWert = Integer.MAX_VALUE;
// Zähler für serielle Sortieralgorithmen
private long tauschZaehlerSeriell;
private long vergleichszaehlerSeriell;
// Zähler für paralelle Sortieralgorithmen
private AtomicInteger tauschZaehlerParallel;
private AtomicInteger vergleichszaehlerParallel;
/**
* Der Algorithmus arbeitet parallel
*/
private final boolean parallel;
/**
* erweiterte Ausgaben beim Sortieren
*/
public static boolean geschwaetzig = false;
/**
* Initialisieren eines Sortierers mit einem
* unsortierten Eingabefeld s
* @param s ein unsortiertes Feld
* @param p der Algorithmus is parallel implementiert
*/
public Sortierer(int[] s, boolean p) {
feld = s;
parallel = p;
if (parallel) {
tauschZaehlerParallel = new AtomicInteger();
vergleichszaehlerParallel = new AtomicInteger();
}
else {
tauschZaehlerSeriell = 0;
vergleichszaehlerSeriell = 0;
}
}
/**
* die Groesse des zu sortierenden Feldes
*/
public int feldgroesse() {
return feld.length;
}
/**
* Gibt ein Feldelement auf gegebenem Index aus
* @param index
* @return
*/
public int getElement(int index) {
return feld[index];
}
/**
* sortiert das Eingabefeld
* @param s ein unsortiertes Feld
*/
abstract public void sortieren(int startIndex, int endeIndex);
/**
* Eine Referenz auf das Feld
* @return
*/
public int[] dasFeld() {
return feld;
}
/**
* kontrolliert ob ein Feld sortiert wurde
* @return
*/
public boolean validierung() {
boolean korrekt;
int i = 0;
while (((i + 1) < feld.length) &&
(feld[i]<=feld[i + 1])) {i++;}
korrekt = ((i + 1) == feld.length);
return korrekt;
}
/**
* Liefert den Namen des implementierten Sortieralgorithmus
* @return
*/
abstract public String algorithmus();
/**
* Drucken des Feldes auf System.out
*/
public void druckenKonsole() {
for (int i = 0; i < feld.length; i++) {
System.out.println("feld[" + i + "]=" + feld[i]);
}
}
/**
* Anzahl der Vertauschungen die zum Sortieren benoetigt wurden
* @return Anzahl der Vertauschungen
*/
public long anzahlVertauschungen() {
if (parallel) return tauschZaehlerParallel.get();
else return tauschZaehlerSeriell;
}
/**
* Anzahl der Vergleiche die zum Sortieren benoetigt wurden
* @return Anzahl der Vergleiche
*/
public long anzahlVergleiche() {
if (parallel) return vergleichszaehlerParallel.get();
else return vergleichszaehlerSeriell;
}
/**
* vergleicht zwei Zahlen a und b auf Größe
* @param a
* @param b
* @return wahr wenn a kleiner b ist
*/
public boolean istKleiner(int a, int b) {
vglZaehler();
if (geschwaetzig) {
System.out.println("Vergleich:feld["+a+"]<feld["+b+"] bzw. " +
feld[a] +"<"+ feld[b]);}
return (feld[a]<(feld[b]));
}
/**
* vergleicht zwei Zahlen a und b auf Größe
* @param a
* @param b
* @return wahr wenn a kleiner oder gleich b ist
*/
public boolean istKleinerGleich(int a, int b) {
vglZaehler();
if (geschwaetzig) {
System.out.println("Vergleich:feld["+a+"]<=feld["+b+"] bzw. " +
feld[a] +">"+ feld[b]);}
return (feld[a]<=(feld[b]));
}
/**
* diese Methode zaehlt alle Vergleiche. Sie ist mt-sicher
* für alle Algorithmen die das parallel Flag gesetzt haben
*/
public void vglZaehler() {
if (parallel) vergleichszaehlerParallel.getAndIncrement();
else vergleichszaehlerSeriell++;
}
/**
* Tausche den Inhalt der Position a mit dem Inhalt der Position b
* @param a
* @param b
*/
public void tausche(int a, int b) {
tZaehler();
if (geschwaetzig)
System.out.println("Getauscht:feld["+a+"<->"+b+"];f["+a
+ "]="+feld[b]+";feld["+b+"]="+feld[a]);
int s = feld[a];
feld[a] = feld[b];
feld[b] = s;
}
/**
* diese Methode zaehlt alle Vertauschungen. Sie ist mt-sicher
* für alle Algorithmen die das parallel Flag gesetzt haben
*/
public void tZaehler() {
if (parallel) tauschZaehlerParallel.getAndIncrement();
else tauschZaehlerSeriell++;
}
/**
* Belege das Feld mit Zufallswerten. Alte Belegungen werden gelöscht!
*/
public void generiereZufallsbelegung() {
// Generiere neue Belegung
maxWert = 2 * feld.length;
for (int i = 0; i < feld.length; i++) {
feld[i]=(int)(Math.random() * (double) maxWert);
}
}
/**
* Setzt Zaehler für Vertauschungen und Vergleiche zurueck auf Null
*/
public void zaehlerRuecksetzen() {
if (parallel) {
tauschZaehlerParallel.set(0);
vergleichszaehlerParallel.set(0);
}
else {
tauschZaehlerSeriell = 0;
vergleichszaehlerSeriell = 0;
}
}
}
- 3785 views
TrivialSort.java
TrivialSort.javaDiese Klasse ist ein Platzhalter der nur die beiden ersten Elemente eines Intervalls sortieren kann.
Das Programm dient zum Testen des Beispiels und es zeigt den Einsatz der schon implementierten istKleiner() und tausche() Methoden die von der Oberklasse geerbt werden.
package s2.sort;
/**
*
* @author sschneid
* @version 2.0
*/
public class TrivialSort extends Sortierer{
/**
* Konstruktor: Akzeptiere ein Feld von int. Reiche
* das Feld an die Oberklasse weiter.
* Der Algorithmus ist nicht parallel (false Argument)
* @param s
*/
public TrivialSort(int[] s) { super(s,false); }
/**
* Diese Methode sortiert leider nur die beiden ersten Elemente
* auf der Position von und (von+1)
* @param von
* @param bis
*/
@Override
public void sortieren(int von, int bis) {
geschwaetzig = false;
int temp; // Zwischenspeicher
if (istKleiner(von+1,von)) {
tausche(von,von+1);
}
if (istKleiner(von+2,von+1)) {
tausche(von+1,von+2);
}
//druckenKonsole();
}
@Override
public String algorithmus() {
return "Sortiere drei Werte";
}
}
- 3135 views
Sortieren durch Auswahl (Selectionsort)
Sortieren durch Auswahl (Selectionsort)Beim Suchen durch Auswahl durchsucht man das jeweilige Feld nach dem kleinsten Wert und tauscht den Wert an der gefundenen Position mit dem Wert an der ersten Stelle.
Anschließend sucht man ab der zweiten Position aufsteigend nach dem zweitkleinsten Wert und tauscht diesen Wert mit dem Wert der zweiten Position.
Man fährt entsprechend mit der dritten und allen weiteren Positionen fort bis alle Werte aufsteigend sortiert sind.
Verfahren
- Man suche im Feld f[1] bis f[N] die Position i1 an der sich das Element mit dem kleinsten Schlüssel befindet und vertausche f[1] mit f[i1]
- Man suche im Feld f[2] bis f[N] die Position i2 an der sich das Element mit dem kleinsten Schlüssel befindet und vertausche f[2] mit f[i2]
- Man verfahre wie oben weiter für Position i3 bis iN-1
Beispiel
Ausgangssituation: Ein Feld mit 7 unsortierten Ganzzahlwerten (N=7)
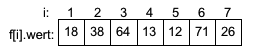
Die Zahl 12 auf Position 5 ist die kleinste Zahl im Feld f[1] bis f[7]. Somit ist i1=5. Nach Vertauschen von f[1] mit f[5] ergibt sich:
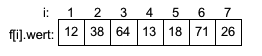
Die Zahl 13 auf Position 4 ist die kleinste Zahl im Feld f[2] bis f[7]. Somit ist i2=4. Nach Vertauschen von f[2] mit f[4] ergibt sich:
Die Zahl 18 auf Position 5 ist die kleinste Zahl im Feld f[3] bis f[7]. Somit ist i3=5. Nach Vertauschen von f[3] mit f[5] ergibt sich:
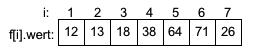
Das Verfahren wird entsprechend weiter wiederholt bis alle Werte sortiert sind.
Aufwand
Der minimale Aufwand Mmin(N), der maximale Aufwand Mmax(N) und er mittlere Aufwand Mmit(N) ist bei diesem naiven Verfahren gleich, da immer die gleiche Anzahl von Operationen (N-1) ausgeführt wird. Der Faktor 3 ensteht dadurch, dass bei einer Vertauschung zweier Werte insgesamt drei Operationen braucht:
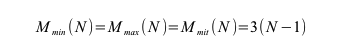
Die Anzahl der Vergleiche sind die Summe von n-1, n-1 etc. unabhängig davon ob das Feld sortiert oder unsortiert ist:
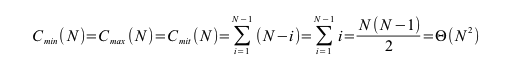
Implementierung
Die Implementierung der Klasse SelectionSort.java ist bei Github zu finden.
- 17265 views
Lautet das erste Element
Lautet das erste Element eines Feldes nicht f[0]?
Dann würde man dementsprechend ab der Position f[0] anfangen, das Feld zu durchsuchen!
- Log in to post comments
Antwort: Beginn einer Folge
Sehr gute Beobachtung,
Java fängt bei Null an zu zählen. Menschen beginnen oft bei Eins. Ich kann Ihnen da leider keine einfache Lösung bieten. Das ist Definitionssache. Man muß immer schauen was die Definition des ersten Elements ist.
- Log in to post comments
Selectionsort: Implementierung in Java
Selectionsort: Implementierung in JavaDie folgende Implementierung implementiert die abstrakte Klasse Sortierer die in den Beispielprogrammen zum Sortieren zu finden ist.
Implementierung: Klasse SelectionSort
package s2.sort;
/**
*
* @author sschneid
* @version 2.0
*/
public class SelectionSort extends Sortierer{
/**
* Konstruktor: Akzeptiere ein Feld von int. Reiche
* das Feld an die Oberklasse weiter.
* Der Algorithmus ist nicht parallel (false Argument)
* @param s
*/
public SelectionSort(int[] s) {super(s,false);}
/**
* sortiert ein Eingabefeld s und gibt eine Referenz auf dea Feld wieder
* zurück
* @param s ein unsortiertes Feld
* @return ein sortiertes Feld
*/
@Override
public void sortieren(int startIndex, int endeIndex){
//geschwaetzig=true;
int minimumIndex;
for (int unteresEnde=startIndex; unteresEnde<endeIndex; unteresEnde++) {
minimumIndex = unteresEnde; //Vergleichswert
// Bestimme Position des kleinsten Element im Intervall
for (int j=unteresEnde+1; j<=endeIndex; j++) {
if (istKleiner(j,minimumIndex)) {
minimumIndex=j; // neuer Kandidat
}
}
// Tausche kleinstes Element an den Anfang des Intervalls
tausche(unteresEnde,minimumIndex);
// das kleinste Element belegt jetzt das untere Ende des Intervalls
}
}
/**
* Liefert den Namen des SelectionSorts
* @return
*/
@Override
public String algorithmus() {return "Sortieren durch Auswahl";}
}
- 9000 views
Sortieren durch Einfügen (Insertionsort)
Sortieren durch Einfügen (Insertionsort)Verfahren
Das Sortieren durch Einfügen ist ein intuitives und elementare Verfahren:
- Man teilt die zu sortierende Folge f mit N Elementen in eine bereits sortierte Teilfolge f[0] bis f[s-1] und in eine unsortierte Teilfolge f[s] bis f[n].
- Zu Beginn ist die sortierte Teilfolge leer.
- Der Beginn der unsortierten Folge f[s] wird die Sortiergrenze genannt.
- Man setzt eine Sortiergrenze hinter der bereits durch Zufall sortierte Teilfolge f[1] bis f[s-1]
- Vergleiche f[s] mit f[s-1] und vertausche die beiden Elemente falls f[s]<f[s-1]
- Führe weitere Vergleiche und absteigende Vertauschungen durch bis man ein f[s-j] gefunden hat für das gilt f[s-j-1]<f[s-j]
- Erhöhe die Sortiergrenze von f[i] auf f[i+1] und wiederhole die Vergleichs- und Vertauschungsschritte wie im vorhergehenden Schritt beschrieben.
- Die Folge ist sortiert wenn die Sortiergrenze das Ende des Folge erreicht hat.
Beispiel
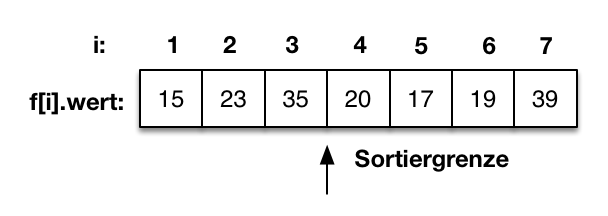 |
Gegeben sei eine Folge in einem Feld mit sieben Elementen. Die ersten drei Elemente sind bereits sortiert und die Sortiergrenze wird mit 4 belegt. Die unsortierte Folge beginnt auf dem Feldindex vier. |
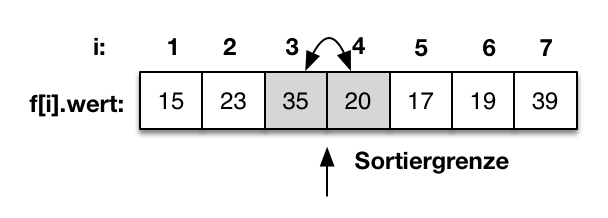 |
Als erstes wird der Wert f[4]=20 mit f[3]=35 verglichen. Da f[4] größer als f[3] ist, werden die beiden Werte getauscht. |
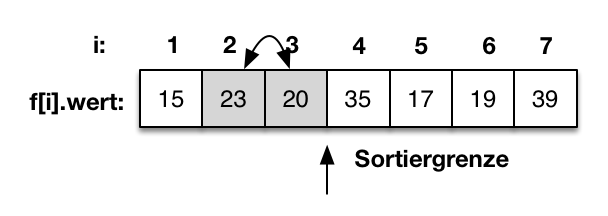 |
Anschließend folgt der Vergleich von f[3]=20 mit f[2]=23. Der Wert von f[3] ist größer als f[2]. Die beiden Werte werden getauscht. |
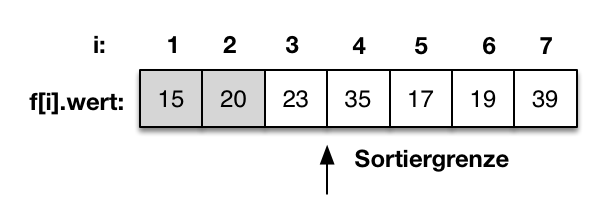 |
Der Vergleich von f[2] mit f[1] zeigt, dass f[2] größer als f[1] ist. f[2]=20 hat also seine korrekte Position in der sortierten Teilfolge gefunden. |
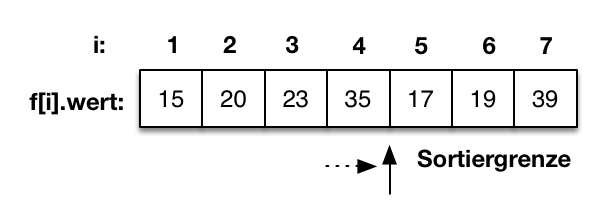 |
Der aktuelle Durchlauf ist hiermit beendet. Die Sortiergrenze wird um eins erhöht und erhält den Wert 5. |
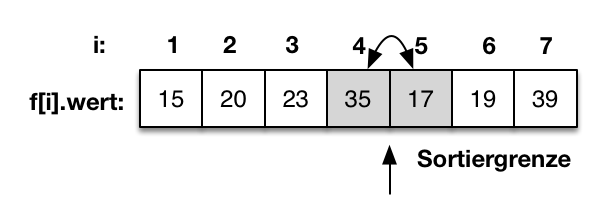 |
Die sortierte Teilfolge ist um eins größer geworden. Es wird wieder f[5]=17 mit f[4]=35 verglichen. Da f[5] größer als f[4] ist, werden die beiden Werte getauscht. Jeder Durchlauf endet, wenn der Wert nicht mehr getauscht werden muss. Der Algorithmus endet wenn die Sortiergrenze die gesamt Folge umfasst. |
Aufwand
Das Sortieren durch Einfügen braucht im günstigsten Fall nur N-1 Vergleiche für eine bereits sortierte Folge. Im ungünstigsten Fall (fallend sortiert) ist aber ein quadratisches Aufwand nötig.
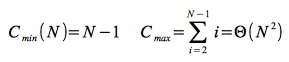
Das gleiche gilt für die Vertauschungen. Hier müssen im ungünstigsten Fall Vertauschungen in einer quadratischen Größenordnung durchgeführt werden.
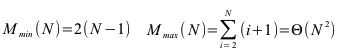
Implementierung
Die Implementierung der Klasse InsertionSort.java ist bei Github zu finden.
- 14016 views
Insertionsort: Implementierung in Java
Insertionsort: Implementierung in JavaDie folgende Implementierung implementiert die abstrakte Klasse Sortierer die in den Beispielprogrammen zum Sortieren zu finden sind.
Implementierung: Klasse InsertionSort
package s2.sort;
/**
*
* @author sschneid
* @version 2.0
*/
public class InsertionSort extends Sortierer {
/**
* Konstruktor: Akzeptiere ein Feld von int. Reiche
* das Feld an die Oberklasse weiter.
* Der Algorithmus ist nicht parallel (false Argument)
* @param s
*/
public InsertionSort(int[] s) {
super(s,false);
}
/**
* sortiert ein Feld im Bereich startIndex bis endeIndex
* @param startIndex
* @param endeIndex
*/
public void sortieren(int startIndex, int endeIndex) {
for (int sortierGrenze = startIndex;sortierGrenze < endeIndex;
sortierGrenze++) {
int probe = sortierGrenze + 1;
int j = startIndex;
while (istKleiner(j, probe)) {
j++;
}
// Verschiebe alles nach rechts.
// Tausche den Probenwert gegen den unteren Nachbarn
// bis man bei der Position j angekommen ist
for (int k = probe - 1; k >= j; k--) {
tausche(k, k + 1);
}
}
}
/**
* Liefert den Namen des Insertion Sorts
* @return
*/
public String algorithmus() {
return "Sortieren durch Einfuegen";
}
}
- 6426 views
Bubblesort
BubblesortDer Bubblesort hat seinen Namen von dem Prinzip erhalten, dass der größte Wert eine Folge durch Vertauschungen in der Folge austeigt wie eine Luftblase im Wasser.
Verfahren
- Vergleiche in aufsteigender Folge die Werte einer unsortierten Folge und vertausche die Werte wenn f(i) > f(i+1) ist
- Wiederhole die Vergleiche und eventuell nötige Vertauschungen bis keine Vetauschung bei einem Prüfdurchlauf vorgenommen werden muss.
Beispiel
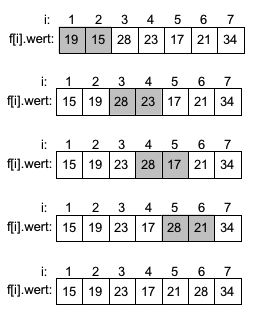 |
Es werden die Werte aufsteigen auf ihre korrekte Reihenfolge verglichen. Im ersten "Durchlauf" müssen die Werte 19 und 15 (in grau) getauscht werden. Anschließend werden die Werte 28 und 23 getauscht und im nächsten Schritt die Werte 28 und 17. Die letzte Vertauschung findet zwischen 28 auf Position 5 und 21 auf Position 6 statt. Der erste Durchlauf ist beendet und der zweite Durchlauf beginnt mit den Vergleichen ab Index 1. |
| Im zweiten Durchlauf sind die Werte auf Index 1 und 2 in der richtigen Reihenfolge. Die Werte 23 und 17 sind die ersten die getauscht werden müssen. Der Wert 23 steigt weiter auf und wird noch mit dem Wert 21 getauscht. Die letzten beiden Werte auf Index 6 und 7 sind in der richtigen Reihenfolge und müssen nicht getauscht werden. Der zweite Durchlauf ist beendet. | 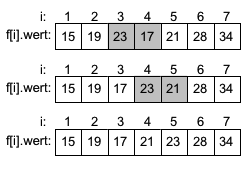 |
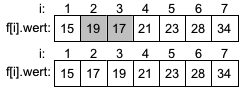 |
Im dritten Durchlauf muß die 19 auf Position 2 mit der 17 auf Position 3 getauscht werden. Auf den höheren Positionen sind keine Veratuschungen mehr nötig. |
Der vierte Durchlauf ist der letzte Durchlauf. In ihm finden keine weiteren Vertauschungen statt. Alle Elemente sind aufsteigend sortiert. Der Algorithmus bricht nach dem vierten Durchlauf ab, da keine Vertauschungen nötig waren. Alle Elemente sind sortiert.
Aufwand
Der günstigste Fall für den Bubblesort ist eine sortierte Folge. In diesem Fall müssen nur N-1 Vergleiche und keine Vertauschungen vorgenommen werden.
Ungünstige Fälle sind fallende Folgen. Findet man das kleinste Element auf dem höchsten Index sind N-1 Durchläufe nötigt bei denen das kleinste Element nur um eine Position nach vorne rückt.
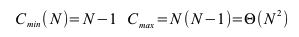
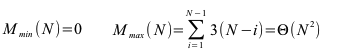
In ungünstigen Fällen ist der Aufwand N2. Man kann zeigen, dass der mittlere Aufwand bei N2 liegt:
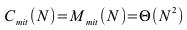
Effizienzsteigerungen
Es gibt eine Reihe von Verbesserungen die darauf beruhen, dass man nicht bei jedem Durchlauf in der ganzen Folge die Nachbarn vergleichen muss. Nach dem ersten Durchlauf ist das größte Element auf dem Index N angekommen. Man muss im nächsten Durchlauf also nur noch alle Nachbarn bis zur Position N-1 kontrollieren.
Implementierung
Die Implementierung der Klasse BubbleSort.java ist bei Github zu finden.
- 7846 views
BubbleSort: Implementierung in Java
BubbleSort: Implementierung in JavaDie folgende Implementierung implementiert die abstrakte Klasse Sortierer die in den Beispielprogrammen zum Sortieren zu finden sind.
Implementierung: Klasse BubbleSort
package s2.sort;
/**
*
* @author sschneid
* @version 2.0
*/
public class BubbleSort extends Sortierer {
/**
* Konstruktor: Akzeptiere ein Feld von int. Reiche
* das Feld an die Oberklasse weiter.
* Der Algorithmus ist nicht parallel (false Argument)
* @param s
*/
public BubbleSort(int[] s) {super(s, false); }
/**
* sortiert ein Eingabefeld s und gibt eine Referenz auf dea Feld wieder
* zurück
* @param s ein unsortiertes Feld
* @return ein sortiertes Feld
*/
public void sortieren(int startIndex, int endeIndex) {
boolean vertauscht;
do {
vertauscht = false;
for (int i = startIndex; i+1 <= endeIndex; i++) {
if (istKleiner(i + 1,i)) {
tausche(i,i+1);
vertauscht = true;
}
}
} while (vertauscht);
}
/**
* Liefert den Namen des Bubble Sorts
* @return
*/
public String algorithmus() {
return "Bubble Sort";
}
}
- 5778 views
Quicksort: Sortieren durch rekursives Teilen
Quicksort: Sortieren durch rekursives TeilenDer Quicksort ist ein Verfahren welches auf dem Grundprinzip des rekursiven Teilens basiert:
- Man nimmt ein beliebiges Pivotelement als Referenz (Pivotpunkt: Drehpunkt, Angelpunkt)
- Man teilt die unsortierte Folge in drei Unterfolgen
- Alle Elemente die kleiner oder gleich dem Pivotelement sind
- Das Pivotelement
- Alle Element die größer oder gleich dem Pivotelement sind
Die Unterfolgen die größer bzw. kleiner als das Pivotelement sind, sind selbst noch unsortiert. Das Pivotelement steht bereits an der richtigen Position zwischen den zwei Teilfolgen.
Durch rekursives Sortieren werden auch sie sortiert.
Der Quicksort wurde 1962 von C.A.R. Hoare (Computer Journal) veröffentlicht.
Verfahren
- Folgen die aus keinem oder einem Element bestehen bleiben unverändert.
- Wähle ein Pivotelement p der Folge F und teile die Folge in Teilfolgen F1 und F2 derart das gilt:
- F1 enhält nur Elemente von F ohne das Pivotelement p die kleiner oder gleich p sind
- F2 enhält nur Elemente von F ohne das Pivotelement p die größer oder gleich p sind
- Die Folgen F1 und F2 werden rekursiv nach dem gleichen Prinzip sortiert
- Die Ergebnis der Sortierung ist eine Aneinanderreihung der der Teilfolgen F1, p, F2.
Anmerkung: Der Quicksort folgt dem allgemeinen Prinzip von "Teile und herrsche" (lat.: "Divide et impera", engl. "Divide and conquer")
Beispiel
Im ersten Schritt wird das vollständige Feld vom Index 1 bis 7 sortiert, indem der Wert 23 auf dem Index 7 als Pivotwert (Vergleichswert) gewählt.
Es wird nun vom linken Ende des Intervals (Index 1) aufsteigend das erste Element gesucht welches größer als das Pivotelement ist. Hier ist es der Wert 39 auf dem Index 2. Anschließend wird vom oberen Ende des Intervals von der Position links vom Pivotelement absteigend das erste Element gesucht welches kleiner als das Pivotelement ist. Hier ist es der Wert 19 auf dem Index 6.
Im nächsten Schritt werden die beiden gefundenen Werte getauscht und liegen nun in der "richtigen" Teilfolge.
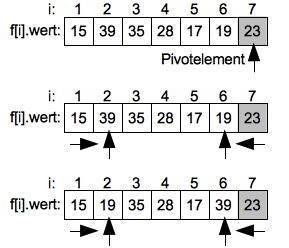
Jetzt wird die Suche von links nach rechts weitergeführt bis das nächste Element gefunden ist welches größer als das Pivotelement ist. Hier ist es 35 auf Position 3. Die fallende Suche von Rechts endet bei dem Wert 17 auf Index 5. Die beiden Werte werden dann getauscht.
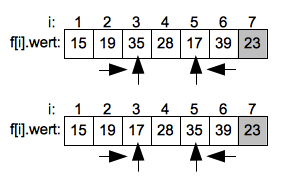
Nach der Vertauschung wird die aufsteigende Suche von Links weitergeführt und endet beim Wert 28 auf dem Index 4. Die fallende Suche von Rechts endet sofort da der Suchindex der steigenden Suche erreicht ist.
Der Pivotwert 23 auf Index 7 wird jetzt mit 28 auf dem Index getauscht und hat seine korrekte Endposition erreicht.
Der Sortiervorgang wird jetzt rekursiv im Intervall 1 bis 3 und 5 bis 7 fortgeführt. Wie zuvor werden die Werte auf dem höchsten Index der Unterintervalle wieder als Pivotwerte gewählt.
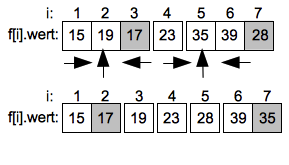
Im linken Unterintervall endet die aufsteigende Suche schnell beim Wert 19 auf Index 2 der dann mit dem Pivotwert 17 getauscht wird. Im rechten Unterintervall muss bei der aufsteigenden suche der Wert 35 auf Index 5 mit dem Pivotwert 28 getauscht werden.
Bei den weiteren Teilungen in Unterintervalle bleiben nur noch das Intervall von Index 1 bis 2 sowie das Intervall von Index 6 bis 7 übrig. Hier werden wieder die Elemente am rechten Rand als Pivotwerte gewählt.
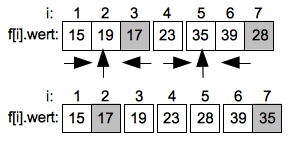
Im linken Unterintervall durchläuft die aufsteigende Suche das einzige Element und endet ohne Vertauschung. Im rechten Intervall muss ein letztes mal der Wert 39 mit 35 getauscht werden.
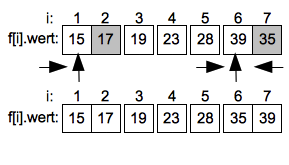
Aufwand
Der Quicksort ist in normalen Situationen mit einem Aufwand von n*log(n) sehr gut für große Datenmengen geeignet. Er ist einer der schnellsten Algorithmen. Bei sehr ungünstigen Sortierfolgen (schon sortiert) kann er aber auch mit einem quadratischen Aufwand sehr ineffizient sein.
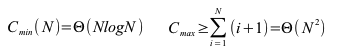
Vorsortierte Folgen sind durchaus häufig bei realen Problemen zu finden. Der Quicksort ist bei schon sortierten Folgen sehr ineffizient ist und daher ist der Einsatz bei realen Anwendungen durchaus heikel.
Implementierung
Serieller Quicksort
Die Implementierung der Klasse QuickSort.java ist bei Github zu finden.
Parallelisierter Quicksort
Die unten aufgeführte Klasse nutzt die "Concurrency Utilities" die in Java 7 eingeführt wurden. Aus der Sammlung wird das Fork/JoinFramework verwendet. Die Implementierung der Klasse QuickSortParallel.java ist bei Github zu finden.
Das Aufteilen des Sortierintervalls erfolgt hier seriell in einer eigenen Methode.
Das Sortieren der Teilintervalle erfolgt parallel solange das Intervall eine bestimmte Mindestgröße (100) besitzt.
Die Fork/Join Klassen stellen dem Algorithmus einen Pool von Threads zur Verfügung die sich nach der Anzahl des Prozessoren des Rechners richten.
Hierzu dient eine Spezialisierung der Klasse RecursiveAction.
- Die Methode compute() wird in einem eigenen Thread durchgeführt wenn das dazugehörige Objekt mit der Methode invokeAll()aufgerufen wird. Diese Methode wird überschrieben.
- Die Methode invokeAll() erlaubt es neue Tasks zu in Auftrag zu geben. Diese Methode wird erst beendet wenn alle Tasks ausgeführt sind.
In der vorliegenden Implementierung erfolgt ein paralleler Aufruf eines Task zum Sortieren der Teilintervalle und nicht ein sequentieller Methodenaufruf.
Die Implementierung des Task erfolgt in der inneren Klasse Sorttask. Diese Klasse ummantelt quasi die Sortiermethode.
- 13301 views
Verfahren
Im Abschnitt "Verfahren" wird das Pivotelement zuerst "p" genannt. Im weiteren Verlauf wird jedoch "k" als Pivotelement bezeichnet. Richtig müsste es aber auch "p" heißen, oder?
Folgen die aus keinem oder einem Element bestehen bleiben unverändert.
Wähle ein Pivotelement p der Folge F und teile die Folge in Teilfolgen F1 und F2 derart das gilt:
F1 enhält nur Elemente von F ohne das Pivotelement k die kleiner oder gleich k sind
F2 enhält nur Elemente von F ohne das Pivotelement k die größer oder gleich k sind
Die Folgen F1 und F2 werden rekursiv nach dem gleichen Prinzip sortiert
Die Ergebnis der Sortierung ist eine Aneinanderreihung der der Teilfolgen F1, k, F2.
- Log in to post comments
typo
Beispiel
[...](nach dem zweiten Bild)
Der Pivotwert 23 auf Index 7 wird jetzt mit 28 auf dem Index getauscht und hat seine korrekte Endposition erreicht.
[...]
Aufwand
Der Quicksort ist in normalen Situationen mit einem Aufwand von n*log(n) sehr gut für große Datenmengen geeignet. Er ist einer der schnellsten Algorithmen. Bei sehr ungünstigen Sortierfolgen (schon sortiert) kann er aber auch mit einem quadratischen Aufwand sehr ineffizient sein.
- Log in to post comments
Verfahren (Intervallbildung)
Sie beschreiben das Ergebnis des Teilsortierverfahres als eine Aneinanderreihung von F1, p, F2 (also quasi 3 Intervalle).
Nachdem 17 aber in dem linken Teilintervall als Pivotelement für die weitere Ausführung verwendet wird, ist 17 also p kein eigenes Teilintervall sondern laut ihrer Darstellung Teil des Intervalls 15,17. Wie kommt das?
- Log in to post comments
Sehr gut beobachtet
Das Pivotelement kann ein kleines Intervall bilden. Es steht halt zwischen den beiden großen Intervallen. Schlechte Erklärung meiner Seite.
Ein Gedankenexperiment:
* Ein anderes Element kann den gleichen Schlüssel wie das Pivotelement haben. Das wurde in den Beispielen nie durchgespielt...
* Gleich ob man mit ,>= tested, das andere Element gehört zum Intervall links oder rechts.
* Deswegen sollte auch das Pivotelement so behandelt werden. Es gehört in das linke oder rechte Intervall.
* Das mittlere Intervall macht nicht richtig Sinn.
Das dritte Intervall macht auch keinen Unterschied bei der Komplexität des Algorithmus. Es ist sehr klein im vergleich zu den beiden anderen Intervallen. Ich würde es als eine Variante akzeptieren.
- Log in to post comments
Quicksort: Implementierung in Java
Quicksort: Implementierung in JavaDie folgende Implementierung implementiert die abstrakte Klasse Sortierer die in den Beispielprogrammen zum Sortieren zu finden sind.
Implementierung: Klasse Quicksort
package s2.sort;
/**
*
* @author sschneid
*/
public class QuickSort extends Sortierer{
/**
* Konstruktor: Akzeptiere ein Feld von int. Reiche
* das Feld an die Oberklasse weiter.
* Der Algorithmus ist nicht parallel (false Argument)
* @param s
*/
public QuickSort(int[] s) {
super(s,false);
}
/**
* sortiert ein Eingabefeld s und gibt eine Referenz auf dea Feld wieder
* zurück
* @param s ein unsortiertes Feld
* @return ein sortiertes Feld
*/
@Override
public void sortieren(int startIndex, int endeIndex) {
int i = startIndex;
int j = endeIndex;
int pivotWert = feld[startIndex+(endeIndex-startIndex)/2];
//System.out.println("von"+ startIndex+", bis:"+endeIndex +
// " pivot:" + pivotWert);
while (i<=j) {
// Suche vom unteren Ende des Bereichs aufsteigend einen
// Feldeintrag welcher groesser als das Pivotelement ist
while (feld[i] < pivotWert) {i++;vglZaehler();}
// Suche vom oberen Ende des Bereichs absteigend einen
// Feldeintrag der kleiner als das Pivotelement ist
while (feld[j] > pivotWert) {j--;vglZaehler();}
// Vertausche beide Werte falls die Zeiger sich nicht
// aufgrund mangelnden Erfolgs überschnitten haben
if (i<=j) {
tausche(i,j);
i++;
j--;
}
}
// Sortiere unteren Bereich
if (startIndex<j) {sortieren(startIndex,j);}
// Sortiere oberen Bereich
if (i<endeIndex) {sortieren(i,endeIndex);}
}
/**
* Liefert den Namen des Insertion Sorts
* @return
*/
@Override
public String algorithmus() {
return "QuickSort";
}
}
Implementierung: Parallelisierter Quicksort
Die unten aufgeführte Klasse nutzt die "Concurrency Utilities" die in Java 7 eingeführt wurden. Aus der Sammlung wird das Fork/Join Framework verwendet.
Das Aufteilen des Sortierintervalls erfolgt hier seriell in einer eigenen Methode.
Das Sortieren der Teilintervalle erfolgt parallel solange das Intervall eine bestimmte Mindestgröße (100) besitzt.
Die Fork/Join Klassen stellen dem Algorithmus einen Pool von Threads zur Verfügung die sich nach der Anzahl des Prozessoren des Rechners richten.
Hierzu dient eine Spezialisierung der Klasse RecursiveAction.
- Die Methode compute() wird in einem eigenen Thread durchgeführt wenn das dazugehörige Objekt mit der Methode invokeAll() aufgerufen wird. Diese Methode wird überschrieben.
- Die Methode invokeAll() erlaubt es neue Tasks zu in Auftrag zu geben. Diese Methode wird erst beendet wenn alle Tasks ausgeführt sind.
In der vorliegenden Implementierung erfolgt ein paralleler Aufruf eines Task zum Sortieren der Teilintervalle und nicht ein sequentieller Methodenaufruf.
Die Implementierung des Task erfolgt in der inneren Klasse Sorttask. Diese Klasse ummantelt quasi die Sortiermethode.
package s2.sort;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.RecursiveAction;
/**
*
* @author sschneid
* @version 2.0
*/
public class QuickSortParallel extends Sortierer{
static int SIZE_THRESHOLD=100; // Schwellwert für paralleles Sortieren
private static final ForkJoinPool THREADPOOL = new ForkJoinPool();
/**
* Konstruktor: Akzeptiere ein Feld von int. Reiche
* das Feld an die Oberklasse weiter.
* Der Algorithmus ist parallel (true Argument)
* @param s
*/public QuickSortParallel(int[] s) {
super(s, true);
}
/**
* Innere statische Klasse die Fork and Join aus dem Concurrency package
* implementiert. Sie macht aus Methodenaufrufen, Taskaufrufe von Threads
*/
static class SortTask extends RecursiveAction {
int lo, hi;
QuickSortParallel qsp;
/**
* Speichere alle wichtigen Parameter für den Task
* @param lo untere Intervallgrenze
* @param hi obere Intervallgrenze
* @param qsp Referenz auf das zu sortierende Objekt
*/
SortTask(int lo, int hi, QuickSortParallel qsp) {
this.lo = lo;
this.hi = hi;
this.qsp =qsp;
}
/**
* Führe Task in eigenem Thread aus und nutze Instanzvariablen
* als Parameter um Aufgabe auszuführen.
*/
@Override
protected void compute() {
//System.out.println(" Thread ID => " + Thread.currentThread().getId());
if (hi - lo < SIZE_THRESHOLD) {
// Sortiere kleine Intervalle seriell
qsp.sortierenSeriell(lo, hi);}
else { // Sortiere große Intervalle parallel
int obergrenzeLinkesIntervall;
obergrenzeLinkesIntervall = qsp.teilsortieren(lo,hi);
// der serielle rekursive Aufruf wird ersetzt durch
// den parallelen Aufruf zweier Threads aus dem Threadpool
//System.out.println("Parallel: "+
// lo+","+obergrenzeLinkesIntervall+","+hi);
invokeAll(new SortTask(lo,obergrenzeLinkesIntervall,qsp),
new SortTask(obergrenzeLinkesIntervall+1,hi,qsp));
}
}
}
/**
* sortiert ein Eingabefeld s und gibt eine Referenz auf dea Feld wieder
* zurück
* @param s ein unsortiertes Feld
* @return ein sortiertes Feld
*/
@Override
public void sortieren(int startIndex, int endeIndex) {
THREADPOOL.invoke(new SortTask(startIndex,endeIndex,this));
}
/**
* sortiert ein Eingabefeld s und gibt eine Referenz auf dea Feld wieder
* zurück
* @param s ein unsortiertes Feld
* @return ein sortiertes Feld
*/
public void sortierenSeriell(int startIndex, int endeIndex) {
if (endeIndex > startIndex) {
int obergrenzeLinkesIntervall= teilsortieren(startIndex, endeIndex);
//System.out.println("Seriell: "+
// startIndex+","+obergrenzeLinkesIntervall+","+endeIndex);
// Sortiere unteren Bereich
if (startIndex<obergrenzeLinkesIntervall) {
sortierenSeriell(startIndex,obergrenzeLinkesIntervall);}
// Sortiere oberen Bereich
if (obergrenzeLinkesIntervall+1<endeIndex) {
sortierenSeriell(obergrenzeLinkesIntervall+1,endeIndex);}
}
}
public int teilsortieren(int startIndex, int endeIndex) {
int i = startIndex;
int j = endeIndex;
int pivotWert = feld[startIndex+(endeIndex-startIndex)/2];
//druckenKonsole();
while (i<=j) {
// Suche vom unteren Ende des Bereichs aufsteigend einen
// Feldeintrag welcher groesser als das Pivotelement ist
while (feld[i] < pivotWert) {i++;vglZaehler();}
// Suche vom oberen Ende des Bereichs absteigend einen
// Feldeintrag der kleiner als das Pivotelement ist
while (feld[j]> pivotWert) {j--;vglZaehler();}
// Vertausche beide Werte falls die Zeiger sich nicht
// aufgrund mangelnden Erfolgs überschnitten haben
if (i<=j) {
tausche(i,j);
i++;
j--;
}
}
//System.out.println("von"+ startIndex+", bis:"+endeIndex +
// " pivot:" + pivotWert + " , return: " +i);
return i-1;
}
/**
* Liefert den Namen des Insertion Sorts
* @return
*/
public String algorithmus() {
return "QuickSort mit Fork and Join";
}
}
Hinweis: Dieser Algorithmus ist parallel. Er teilt dies der Oberklasse im Konstruktor als Parameter mit. Hierdurch werden die Zähler für die Vergleiche von Vertauschungen und Vergleichen vor einem parallelen Inkrement geschützt. Die Synchronisierung dieser Zählvariablen ist leider so aufwendig, dass der Algorithmus nicht mehr schneller als der seriell Algorithmus ist...
Man muss hier leider eine Entscheidung treffen:
- setzen des Flag auf true: Die Vertauschungen werden korrekt gezählt. Der Algorithmus ist korrekt und langsam.
- setzen des flag auf false: Die Veretauschungen und Vergleiche werden nicht korrekt gezählt. Der Algorithmus ist korrekt und schnell. Das bedeutet, er skaliert auf Mehrprozessorsystemen.
- 8234 views
Übung (Quicksort)
Übung (Quicksort)Führen Sie einen Durchlauf des Quicksorts manuell durch. Teilen Sie ein gegebenes Sortierintervall (Aufgabe: Vorher) nach den Regeln des Quicksorts in zwei Unterintervalle die noch sortiert werden müssen.
- Sortieren Sie aufsteigend
- Wählen Sie das Pivotelement ganz rechts im Intervall.
- Markieren Sie das Pivotelement in der Aufgabe mit einem Pfeil von unten (siehe Beispiel).
- Wenden Sie die Regeln des Quicksorts an. Zeichnen Sie zweiseitige Pfeile im "Vorher" Diagramm ein, um die notwendigen Vertauschungen zu markieren.
- Zeichnen Sie mit einem zweiseitigen Pfeil die nötige Vertauschung des Pivotelements im "Vorher" Diagramm ein.
- Tragen Sie alle neuen Werte im "Nachher" Diagramm ein.
- Zeichnen sie die beiden verbliebenen zu sortierenden Zahlenintevalle mit eckigen Linien (siehe "Vorher" Diagramm) ein.
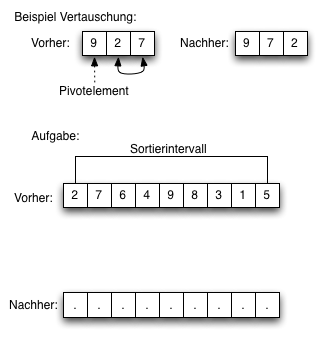
- 7763 views
Lösung (Quicksort)
Lösung (Quicksort) 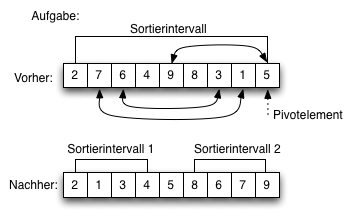
- 5274 views
Heapsort
HeapsortDer Heapsort (Sortieren mit einer Halde) ist eine Variante des Sortierens durch Auswahl. Er wurde in den 1960er Jahren von Robert W. Floyd und J. W. J. Williams entwickelt (siehe: Artikel in Wikipedia).
Der Heapsort hat den Vorteil, dass er auch im ungünstigsten Fall in der Lage ist mit einem Aufwand von O(N*log(N)) zu sortieren.
Hierfür wird eine Datenstruktur (der Heap) verwendet mit der die Bestimmung des Maximums einer Folge in einem Schritt möglich ist.
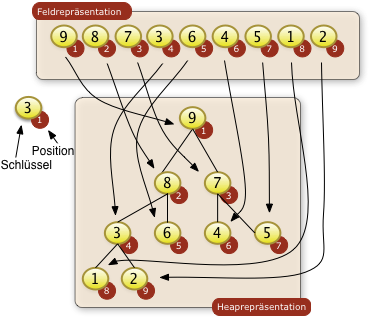 |
Beim Heapsort werden die zu sortierenden Schlüssel einer Folge in zwei Repräsentation betrachet:
Beide Repräsentationen sind Sichten auf die gleichen Daten. Beim Heapsort werden nicht die Schlüssel in einen Binärbaum umkopiert. Die Heaprepräsentation dient nur dem Betrachter zur Verdeutlichung der Beziehung gewisser Feldpositionen. Die Grundidee des Heapsorts besteht darin, daß an der Wurzel des Binärbaums immer der größte Schlüssel stehen muss. Diesen größten Schlüssel kann man dann dem Binärbaum entnehmen und als größtes Element der Folge benutzen. Die verbliebene unsortierte Teilfolge muss dann wieder so als ein Baum organisiert werden in dem das größte Element an der Wurzel steht. Durch sukzessives Entnehmen der verbliebenen gößten Elemente kann man die gesamte Folge sortieren. |
Beim Heapsort muss nicht nur an der Wurzel des Baums der größte Schlüssel stehen. Jeder Knoten im Binärbaum muss größer als die Unterknoten sein. Diese Bedingung nennt man die Heapbedingung.
Verfahren
Beim Heapsort wird auf eine Feld mit N unsortierten Schlüsseln das folgende Verfahren wiederholt angewendet:
- Herstellen der Heapbedingung durch das Bootom-Up für ein Feld mit N Schlüsseln
- Tauschen des ersten und größten Schlüssels auf der Position 1 mit dem letzten unsortierten Schlüssel auf Position N.
- Wiederherstellen des Heapbedingung durch Versickern (Top-Down Verfahren)
- Wiederholen des Verfahrens für die Positionen 1 bis N-1. Ab der Position N ist das Feld schon sortiert.
Beispiel
| Grafische Visualisierung | Beschreibung |
|---|---|
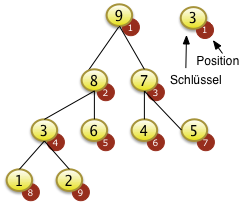 |
Das Beispiel links zeigt nicht eine vollständige Sortierung der gesamten Folge. Es zeigt nur das Einsortieren eines Elements für eine Feldstruktur die schon der Heapbedingung genügt. Das Feld mit den N=9 Elementen wurde so vorsortiert, dass es der Heapdebingung genügt. Das Herstellen der Heapbedingung wird später erläutert. |
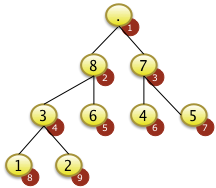 |
Das Element mit dem Schlüssel 9 wird von der Spitze des Baums f[1] entfernt... |
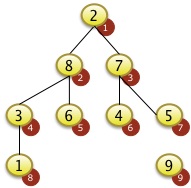 |
... und mit dem Wert 2 der Position N=9 getauscht. Der größte Schlüssel der Folge befindet sich jetzt auf der Position 9. Alle Elemente ab f[9]= F[N] aufwärts sind jetzt aufsteigend sortiert. Alle Elemente von f[1] bis f[N-1]=f[8] sind unsortiert und müssen noch sortiert werden. Die Elemente von f[1] bis f[8] genügen auch nicht mehr der Heapbedingung. Der Wert f[1]=2 ist nicht größer als f[2]=8 oder f[3]=7 |
Weitere Ressourcen
- Sehr schöne Visualisierung der Universität San Francisco (gefunden von der WIMBIT20A!)
Implementierung
Die Implementierung der Klasse HeapSort.java ist bei Github zu finden.
- 5827 views
Die Heapbedingung
Die HeapbedingungEin Feld f[1] bis f[N] mit Schlüsseln bildet einen Heap wenn die folgende Bedingung gilt:
| Heapbedingung |
|---|
|
f[i]<=f[i/2] für 2<= i <= N] |
Die Heapbedingung lässt sich leichter grafisch in einer Baumdarstellung verdeutlichen:
|
Das Feld f mit der Feldgröße N=9
genügt der Heapbedingung da jeder obere Knoten größer als die beiden Unterknoten ist. Die Position im Feld wird hier in rot dargestellt. Der Schlüssel (Wert) des Feldelements hat einen gelben Hintergrund |
- 5200 views
Herstellen der Heapbedingung für einen unsortierten Heap (Bottom-Up Methode)
Herstellen der Heapbedingung für einen unsortierten Heap (Bottom-Up Methode)Mit dem Bottom-Up Verfahren kann man die Heapbedingung für vollständig unsortierte Folgen von Schlüsseln herstellen.
Das Verfahren basiert auf der Idee, dass beginnend mit dem Schlüssel auf der höchsten Feldposition f[N] der Wert versickert wird um anschließend den nächst niedrigeren Wert F[N-1] zu versickern bis man den größten Wert f[1] versickert hat.
Beispiel
| Grafische Visualisierung | Beschreibung |
|---|---|
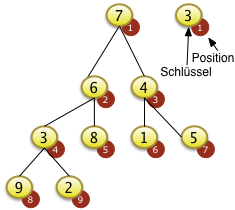 |
Der gegebene Baum sei vollständig mit Zufallsschlüsseln belegt. Alle Werte sind zufällig. Die Positionen 5, 6,7,8 und 9 können nicht versickert werden, da sie keine Unterblattknoten zum Versickern haben. |
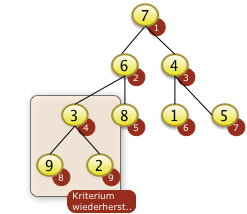 |
Das Bottom-Up Verfahren beginnt mit dem ersten Knoten i der über Unterknoten verfügt. Dieser Knoten ist immer die Position N/2 abgerundet. Bei N=9 ist die 9/2= 4.5. Der abgerundete Wert ist i=4. Hier muß f[8]=9 mit f[4]=3 getauscht werden um den Schlüssel zu versickern. |
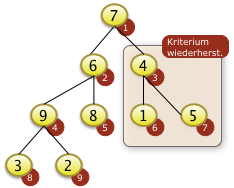 |
Bei i=3 muss f[3]=4 mit f[7]=5 getauscht werden und ist damit auch versickert. |
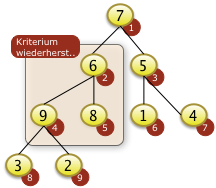 |
Bei i=2 muss f[4] mit f[2] getauscht werden. Das rekursives Versickern bei f[4]=9 is nicht notwendig. f[4]=9 ist größer als f[8]=3 und f[9]=2 |
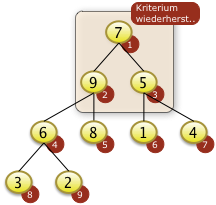 |
Bei i=1 muss f[1] mit f[2]=9 getauscht werden.
|
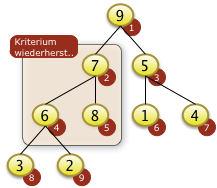 |
Nach dem Neubesetzen der Position f[2]=7 zeigt sich aber, dass die Heapbedingung für den entsprechenden Teilbaum von f[2] nicht gilt da f[2|<f[2*i+1] ist. f[2] muss also rekursiv weiter versickert werden. |
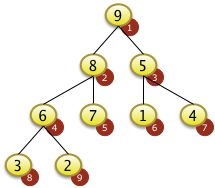 |
Nach dem Tauschen von f[2]=7 mit f[5]=8 ist das rekursive Versickern beendet. f[5] hat keine Unterknoten da 5 > N/2 ist. Der Baum genügt jetzt der Heapbedingung |
- 10616 views
3ter Schritt...
Beim dritten Schritt müsste es doch f[4]=6 sein,welches größer ist als f[8] und f[9]...?
Bei i=2 muss f[4] mit f[2] getauscht werden. Das rekursives Versickern bei f[4]=9(6) ist nicht notwendig. f[4]=9(nicht 6?) ist größer als f[8]=3 und f[9]=2
- Log in to post comments
Positionen
1. Spalte:
Die Schlüssel f[9] bis f[5] können nicht versickert werden, da sie keine Blattknoten zum Versickern haben.
- Log in to post comments
Herstellen der Heapbedingung durch Versickern (Top-Down Methode)
Herstellen der Heapbedingung durch Versickern (Top-Down Methode)Herstellen der Heapbedingung
Top-Down-Verfahren
Dieses Verfahren dient der Herstellen der Heapbedingung, wenn schon für die Unterheaps für die Heapbedingung gilt.
Man wendet es an, nachdem man den größten Schlüssel entnommen hat und ihn durch den Wert mit dem größten Index im unsortierten Baum ersetzt hat.
Das Versickern dieses neuen Schlüssels an der Wurzel des Baums erfolgt mit den folgenden Schritten:
- Beginne mit der Position i=1 im Baum
- Der Schlüssel f[i] hat keine Unterknoten da 2*i>N ist,
- Der Schlüssel kann nicht mehr versickert werden. Das Verfahren ist beendet.
- Der Schlüssel f[i] hat noch genau einen Unterknoten f[i*2]
- Der Schlüssel f[i] wird mit dem Schlüssel f[i*2] getauscht falls f[i]<f[i*2]. Das Verfahren ist nach diesem Schritt beendet.
- Der Schlüssel f[i] hat noch Unterknoten f[2*i] und f[2*i+1]
- Der Schlüssel f[i] ist der größte der drei Schlüssel f[i], f[i*2],f[i*2+1]
- Das Verfahren ist beendet die Heapbedingung ist gegeben
- Der Schlüssel f[i*2] ist der größte der drei Schlüssel f[i], f[i*2],f[i*2+1]
- Tausche die Schlüssel f[i] mit f[2*i]
- Versickere den Schlüssel f[i*2] nach dem Top-Down Verfahren
- Der Schlüssel f[i*2+1] ist der größte der drei Schlüssel f[i], f[i*2],f[i*2+1]
- Tausche die Schlüssel f[i] mit f[2*i+1]
- Versickere den Schlüssel f[i*2+1] nach dem Top-Down Verfahren
- Der Schlüssel f[i] ist der größte der drei Schlüssel f[i], f[i*2],f[i*2+1]
Diese rekursive Verfahren wird hier an einem Beispiel gezeigt:
| Grafische Visualisierung | Beschreibung |
|---|---|
|
Durch das Entfernen des größten Schlüssels f[1] entstehen zwei Unterbäume für die die Heapbedingung nach wie vor gilt. |
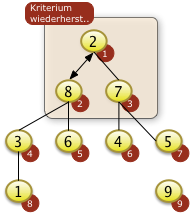 |
Durch das Einsetzen eines Schlüssel von der Position N ist nicht mehr garantiert, dass die Heapbedingung für den gesamten Restbaum f[1] bis f[N-1]=f[8] gegeben ist. Der Schlüssel f[1]=2 ist eventuell größer als die Schlüssel f[2*1] und f[2*1+1]. In diesem Fall ist die Heapbedingung für f[1] bis f[8] schon gegeben. Es muss nichts mehr getan werden. Im vorliegenden Fall ist f[1]=2 aber nicht der größte Schlüssel. Er muss rekursiv versickert werden. Dies geschieht durch das Vertauschen mit f[2] = 8. f[3] = 7 ist nicht der richtige Kandidat. 7 ist nicht der größte der drei Schlüssel. |
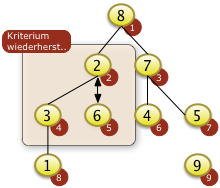 |
Nach dem Vertauschen von f[1] mit f[2] gilt die Heapbedingung zwar für den obersten Knoten. Sie gilt jedoch nicht für den Teilbaum unter f[2]= 2. Der Schlüssel 2 muss weiter versickert werden. In diesem Fall ist f[5]=6 der größte Schlüssel mit dem f[2]= 2 vertauscht weden muss. |
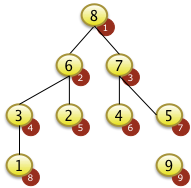 |
Nach dem Vertauschen von f[2] mit f[5] gilt die Heapbedingung wieder für den gesamten Baum. |
- 6990 views
Der Satz "Man wendet es an,
Der Satz "Man wendet es an, nachdem man den größten Schlüssel entnommen hat und ihn durch einen zufälligen Wert ersetzt hat." ist missverständlich formuliert.
Der Wert wird nicht zufällig ausgewählt, sondern ist der letzte im Baum verbliebene Knoten.
- Log in to post comments
Im Schritt 2 ist auch wieder
Im Schritt 2 ist auch wieder das "zufällig" irreführend, da der Wert ja nicht aus der Luft gezaubert wird, sondern von/auf Position N vorgegeben ist. (Ob die Werte des Heaps zufällig erstellt wurden, ist hier ja nicht von Bedeutung.)
( + typo )
"Durch das Einsetzen eines zufälligen Schlüssels von der Position N ist nicht mehr garantiert, dass die Heapbedingung für den gesamten Restbaum f[1] bis f[N-1]=f[8] gegeben ist."
- Log in to post comments
Dieses Verfahren dient der Herstellen der Heapbedingung wenn sch
Sollte geändert werden in: "Dieses Verfahren dient dem Herstellen der Heapbedingung, wenn schon für Unterheaps die Heapbedingung gilt."
- Log in to post comments
Danke, für das Feedback
Das Kommando habe ich eingefügt. Der Artikel "die" habe ich gelassen.
- Log in to post comments
Heapsort: Implementierung in Java
Heapsort: Implementierung in Javapackage s2.sort;
/**
*
* @author sschneid
* @version 2.0
*/
public class HeapSort extends Sortierer{
/**
* Konstruktor: Akzeptiere ein Feld von int. Reiche
* das Feld an die Oberklasse weiter.
* Der Algorithmus ist nicht parallel (false Argument)
* @param s
*/
public HeapSort(int[] s) {super(s,false);}
/**
* sortiert ein Eingabefeld s
* @param s ein unsortiertes Feld
* @return ein sortiertes Feld
*/
public void sortieren(int startIndex, int endeIndex){
// Erzeugen der Heapbedingung, Bottom up...
for (int i=(endeIndex-1)/2; i>=0; i--) versickere (i,endeIndex);
//System.out.println("Heapbedingung hergestellt");
for (int i=endeIndex; i>0; i--) {
// Tausche das jeweils letzte Element mit dem Groeßten an der
// Wurzel. Versickere die neue Wurzel und verkürze
// das zu sortierende Intervall von hinten nach vorne
tausche(0,i); // Groesstes Element von der Wurzel an das Ende
// des Intervals getauscht
versickere(0,i-1); // versickere die neue Wurzel um Heapbedingung
// herzustellen
}
}
/**
* Berechne Index des linken Sohns für gegebenen Index
* liefere -1 zurück falls keine linker Sohn existiert
* @param index für den Sohn berechnet wird
* @param endeIndex letzter belegter Indexplatz
* @return
*/
private int linkerSohn(int index, int endeIndex) {
int ls = index*2+1;
if (ls > endeIndex)
return -1;
else return ls;
}
/**
* Berechne Index des linken Sohns für gegebenen Index
* liefere -1 zurück falls keine linker Sohn existiert
* @param index für den Sohn berechnet wird
* @param endeIndex letzter belegter Indexplatz
* @return
*/
private int rechterSohn(int index, int endeIndex) {
int rs = (index+1)*2;
if (rs > endeIndex)
return -1;
else return rs;
}
/**
* Versickere ein Element auf der Position "vers"
* @param vers Index des zu versickernden Elements
* @param endeIndex hoechste Indexposition die zum Verisckern zur Verfügung
* steht. Sie wird bei der Berechnung des rechts Sohns
* benötigt
*/
private void versickere (int vers, int endeIndex) {
int ls = linkerSohn(vers,endeIndex);
int rs = rechterSohn(vers,endeIndex);
int groessererSohn;
while (ls != -1) { // Es gibt einen linken Sohn
// Versickere bis Heapbedingung erfüllt ist oder keine
// Söhne mehr vorhanden sind
groessererSohn =ls; // linker Sohn als groesseren Sohn nominieren
if ((rs != -1) && (istKleiner(ls,rs))) groessererSohn = rs;
// der rechte Sohn existiert und war groesser...
if (istKleiner(vers,groessererSohn)) {
tausche(vers,groessererSohn); // beide Felder wurden getauscht
vers = groessererSohn;
ls = linkerSohn(vers,endeIndex);
rs = rechterSohn(vers,endeIndex);
}
else ls=-1; // Abbruchbedingung für while Schleife
}
}
/**
* Liefert den Namen des Heap Sorts
* @return
*/
public String algorithmus() {return "Heap Sort";}
}
- 5983 views
Zusammenfassung
ZusammenfassungAufwände der vorgestellten SortieralgorithmenO(N2)
| Cmin | Caver | Cmax | Mmin | Maver | Mmax | |
|---|---|---|---|---|---|---|
| Selectionsort | O(N2) | O(N2) | O(N2) | O(N) | O(N) | O(N) |
| Insertionsort | O(N) | O(N2) | O(N2) | O(N) | O(N2) | O(N2) |
| Bubblesort | O(N) | O(N2) | O(N2) | O(0) | O(N2) | O(N2) |
| Quicksort | O(NlogN) | O(NlogN) | O(N2) | O(0) | O(NlogN) | O(NlogN) |
| Heapsort* | O(NlogN) | O(NlogN) | O(NlogN) | O(NlogN) | O(NlogN) | O(NlogN) |
* Der Heapsort ist ein nicht stabiles Sortierverfahren!
Bei der Betrachtung der Gesamtlaufzeit muss auch der Speicherplatzverbrauch berücksichtigt werden:
| Min | Average | Max | Speicher | |
|---|---|---|---|---|
| Selectionsort | O(N2) | O(N2) | O(N2) | O(1) |
| Insertionsort | O(N) | O(N2) | O(N2) | O(1) |
| Bubblesort | O(N) | O(N2) | O(N2) | O(1) |
| Quicksort | O(NlogN) | O(NlogN) | O(N2) | O(logN) |
| Heapsort | O(NlogN) | O(NlogN) | O(NlogN) | O(1) |
Der Quicksort benötigt Speicherplatz der dem Logarithmus der zu sortierenden Anzahl der Werte abhängt. Die rekursiven Aufrufe benötigen zusätzlichen Platz zum Verwalten der Intervallgrenzen.
- 4454 views
Übungen (Sortieren)
Übungen (Sortieren)Teamübung: Analyse und Implementierung eines Sortieralgorithmus
Wählen Sie einen Algorithmus
- recherchieren Sie seine Funktion
- implementieren Sie den Algorithmus
1. Konfiguration der Laufzeitumgebung
Benutzen Sie die Beispielprogramme zum Sortieren:
- Kopieren Sie sich die Klassen Sortierer, MainSort auf ihr System
- Kopieren Sie sich die Klasse SelectionSort auf Ihr System
- "Aktivieren" Sie sich den gewünschten Sortieralgorithmus in der Klasse MainSort, Methode algorithmusAuswahl(). Alle Sortieralgorithmen sind als Kommentarzeilen vorhanden. Das Entfernen genau eines Kommentar's aktiviert den gewünschten Algorithmus. Beginnen Sie zum Testen mit der Referenzimplementierung der Klasse SelectionSort.
Testen Sie die Gesamtanwendung durch das Aufrufen des Hauptprogramms MainSort.
In diesem Fall beginnt das Programm ein kleines Feld zu sortieren und gibt die Anzahl der Vergleiche, Vertauschungen, Größe des Feldes und die benötigte Zeit in Millisekunden aus. Dies ist die Phase 1. Wurde das kleine Feld erfolgreich sortiert beginnt Phase 2. Hier wird die Feldgröße jeweils verdoppelt. Das Programm bricht ab nachdem zum ersten Mal eine Zeitgrenze (3 Sekunden) beim Sortieren überschritten wurde. Hiermit lässt sich die Effizienz des Algorithmus testen und die Komplexitätsabschätzungen kontrollieren.
2. Implementieren Sie den neuen Sortieralgorithmus
Orientieren Sie sich am Beispiel der Klasse SelectionSort
- Erzeugen Sie eine neue Klasse, die aus der Klasse Sortierer abgeleitet wird
- Implementieren sie einen einfachen Konstruktor der das übergebene Feld an die Oberklasse Sortierer weiterreicht:
-
public XYSort(Sortierbar[] s) {super(s);}
-
- Implementieren Sie eine Methode mit dem Namen algorithmus() die den Namen des Algorithmus ausgibt
-
public String algorithmus() {return "XYsort";}
-
- Implementieren Sie den eigentlichen Sortieralgorithmus in der Methode public void sortieren(anfang, ende)
- Diese Methode soll als Ergebnis alle Elemente von der Position anfang im Feld bis zum Feldelement ende aufsteigend sortiert haben.
2.1 Infrastruktur für die Methode sortieren(anfang, ende)
Die Oberklasse Sortierer stellt alles zur Verfügung was man zum Sortieren benötigt
- tausche(x,y) erlaubt das Tauschen zweier Feldelemente auf der Position x mit dem Element auf der Position y
- boolean istKleiner(x,y) gibt den Wert true (wahr) zurück wenn der Inhalt der Feldposition x kleiner als der Inhalt der Feldposition y ist
Diese beiden Hilfsmethoden sind die einzigen Methoden die zum Implementieren benötigt werden. Der Typ des zu sortierenden Feldes bleibt hinter dem Interface Sortierbar verborgen. Im vorliegenden Fall sind es ganze Zahlen.
Um die Entwicklung zu Vereinfachen bietet die abstrakte Klasse Sortieren eine Reihe von Hilfsmethoden:
- druckenKonsole(): druckt das gesamt Feld mit seiner Belegung auf der Konsole aus
- generiereZufallsbelegung(): Belegt ein existierendes Feld mit neuen Testdaten
- long anzahlVertauschungen(): Gibt die Zahl der Vertauschungen an. Sie werden durch Aufrufe von tausche() gezählt
- long anzahl Vergleiche(): Gibt die Zahl der Vergleiche aus. Sie werden durch Aufrufe von istKleiner() gezählt
- boolean validierung(): Erlaubt die Prüfung eines sortierten Felds. Der Wert ist wahr wenn das Feld korrekt sortiert ist.
3. Anpassen des Hauptprogramms MainSort
Das Hauptprogramm MainSort erzeugt an einer Stelle eine Instanz der Klasse SelectionSort. Ändern Sie diese Stelle im Programm derart, dass eine Instanz Ihrer neuen Sortierklasse aufgerufen wird.
4. Vorbereitende Tests für die Präsentation
Ändern Sie die zu sortierenden Testdaten im Programm MainSort derart ab, dass Sie
- den ungünstigsten Fall für den Sortieralgorithmus wählen (Vertauschungen, Prüfungen)
- den günstigsten Fall wählen (Vertauschungen, Prüfungen)
Tragen Sie die abgelesen Werte in eine Tabellenkalkulation ein und prüfen Sie ob die Aufwände mit den Vorhersagen des Lehrbuchs übereinstimmen (Grafiken!)
Bereiten Sie eine 15-20 minütige Vorstellung/Präsentation des Algorithmus vor:
- Erklären des Algorithmus (mit Beispiel)
- Tafel, Folie, Overheadprojektor genügen
- Vorführen einer Implementierung
- Komplexitätsüberlegungen und Bewertung
- Was ist der durchschnittliche Aufwand?
- Was ist der minimale Aufwand (Beispiel)?
- Wählen Sie die Anzahl der Vertauschungen oder der Vergleiche
- Was ist der Aufwand im ungünstigsten Fall (Beispiel)?
- Wählen Sie die Anzahl der Vertauschungen oder der Vergleiche
- Wichtige Punkte die abhängig vom Algorithmus beachtet werden sollen
- Sortieren durch Auswahl
- Präsentation
- Erklären Sie die "Sortiergrenze"
- Präsentation
- Bubblesort
- Präsentation
- Welche Elemente werden immer vertauscht?
- Warum ist diese Strategie intuitiv aber nicht effizient?
- Präsentation
- Quicksort
- Nutzen Sie Bleistifte oder Streichhölzer zum Visualieren des Verfahrens.
- Legen Sie das Pivotelement in Ihrer Implementierung der Einfachheit halber an eine feste Intervallgrenze!
- Algorithmus:
- Erklären Sie das grundlegende Konzept des Quicksorts (3 Sätze reichen hier!)
- Erklären Sie die Rekursion (Teile und Herrsche) und das Ende der Rekursion (Abbruch)
- Implementierung
- Erklären Sie den Begriff des "Pivotelement"
- Die Implementierung ist durchaus kompliziert. Skizieren Sie sie nur.
- Heapsort
- Diskutieren Sie den Dualismus der beiden Zugriffstrukturen
- Sie arbeiten auf einem Feld (Array)
- Sie betrachten auf der abstrakten Ebene einen Baum
- Wie ist der Zusammenhang zwischen Blattknoten und Feldpositionen?
- Implementierung
- Schreiben Sie Methoden zur Bestimmung der linken und rechten Blattknoten
- Schreiben Sie eine Methode zum Versickern
- Präsentation
- Erläutern Sie den Dualismus
- Erläutern Sie die Bestimmung der Blattknoten
- Erläutern Sie die "Heapbedingung"
- Wie wird sie hergestellt
- Erläutern Sie das Konzept des "Versickerns"
- Diskutieren Sie den Dualismus der beiden Zugriffstrukturen
- Referenzen aus dem Internet
- Zeigen die Referenzen, die Sie am besten mögen: Lustig, lehrreich, witzig
- Zusammenfassung:
- Wie mögen Sie den Algorithmus?
- Wie aufwendig war die Implementierung?
- Sortieren durch Auswahl
- 4991 views
Backtracking
BacktrackingEs gibt drei Arten von Backtracking:
- Entscheidungsproblem: Hier wird eine Lösung gesucht
- Optimierungsproblem: Hier wird die beste Lösung gesucht.
- Aufzählungsproblem: Hier werden alle Lösungen gesucht.
|
Welche Beispiele aus dem echten Leben gibt es für diese drei Kategorien? |
| Definition (nach Wikipedia) |
|---|
| Backtracking geht nach dem Versuch-und-Irrtum-Prinzip (trial and error) vor, das heißt, es wird versucht, eine erreichte Teillösung zu einer Gesamtlösung auszubauen. Wenn absehbar ist, dass eine Teillösung nicht zu einer endgültigen Lösung führen kann, wird der letzte Schritt beziehungsweise werden die letzten Schritte zurückgenommen, und es werden stattdessen alternative Wege probiert. Auf diese Weise ist sichergestellt, dass alle in Frage kommenden Lösungswege ausprobiert werden können (Prinzip des Ariadnefadens). Mit Backtracking-Algorithmen wird eine vorhandene Lösung entweder gefunden (unter Umständen nach sehr langer Laufzeit), oder es kann definitiv ausgesagt werden, dass keine Lösung existiert. Backtracking wird meistens am einfachsten rekursiv implementiert und ist ein prototypischer Anwendungsfall von Rekursion. |
Zeitkomplexität (nach Wikipedia)
Bei der Tiefensuche werden bei maximal z möglichen Verzweigungen von jeder Teillösung aus und einem Lösungsbaum mit maximaler Tiefe von N im schlechtesten Fall 1+z+z2+z3+⋯+zN Knoten erweitert.
Die Tiefensuche und somit auch Backtracking haben im schlechtesten Fall mit O(zN) und einem Verzweigungsgrad z>1 eine exponentielle Laufzeit. Je größer die Suchtiefe n, desto länger dauert die Suche nach einer Lösung. Daher ist das Backtracking primär für Probleme mit einem kleinen Lösungsbaum geeignet.
Resourcen
- 1274 views
Hashverfahren
HashverfahrenHashverfahren helfen Datensätze zu speichern und effizient Operationen wie Suchen, Einfügen und Entfernen zu unterstützen.
Die Datensätze werden mit Hilfe eines eindeutigen Schlüssels gesucht bzw. sortiert. Die Idee der Hashverfahren basiert auf dem Fakt, dass in einer zu verwaltenden Menge, die Anzahl der Schlüssel normalerweise deutlich kleiner als die Wertemenge K der Schlüssel ist. Zu jedem Zeitpunkt ist also nur eine (kleine) Teilmenge K aller möglichlichen Schlüssel gespeichert. Dies geschehe in einem linearen Feld mit Indizes 0, ... , m-1. Diese nennt man Hashtabelle. m ist die Größe der Hashtabelle.
Eine Hashfunktion h ordnet jedem Schlüssel k einen Index h(k) zu. Für h(k) gilt: 0 <= h(k) <) m-1. Im Allgemeinen ist m-1 sehr viel kleiner als der Wertebereich der Schlüssel. Die Hashfunktion kann im Allgemeinen nicht injektiv und weist unterschiedlichen Werten die gleiche Hashadresse zu.
Zwei Schlüssel h(k) und h(k') mit h(k)=h(k') nennt man Synonyme.
Treten in der Menge K keine Synonyme auf, können Sie direkt in der Hashtabelle an der entsprechenden Stelle gespeichert werden.
Im folgenden Beispiel wird als h(k) h(k)= k mod 10 verwendet. Es wird hier also von jeder Jahl der Rest einer Division durch 10 verwendet (Man könnte auch sagen die letzte Stelle...)
|
Hier treten keine Synonyme auf. Die Abildung ist eineindeutig.
|
Hier tritt eine Kollision mit Synonymen auf die Werte 0 und 50 werden auf den Tabellenwert 0 abgebildet.
|
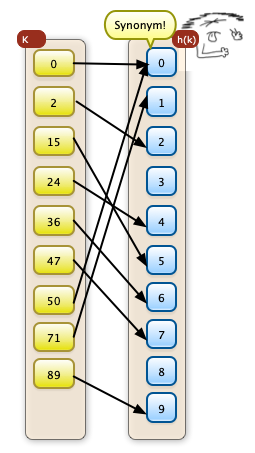
Treten Synonyme auf, ist dies schlecht für ein Hashverfahren. Der konstante Aufwand der Berechnung der Hashfunktion und der Zugriff im Feld führen zu einer Kollision die aufgelöst werden muss.
Ein Hashverfahren soll
- möglichst wenige Kollisionen aufweisen
- Adresskollisionen sollen möglichst effizient aufgelöst werden
| Aufwand | minimaler Aufw. | maximaler Aufw. | Kommentar |
|---|---|---|---|
| Suchen/Einfügen | O(1) | O(n) | Das Auftreten von Synonymen macht den Unterschied! |
Die Berechnung der Hashfunktion sollte einen konstanten Aufwand haben.
Der Zugriffsaufwand steigt aber beim Auftreten von Kollisionen. Die Probleme bei den Hashverfahren liegen in der Auflösung von Kollisionen und beim Wachsen über die Größe eines Feldes. Für eine tiefere Diskussion fehlt in dieser Vorlesung leider die Zeit. Anbei zwei gängige Strategien:
Hashverfahren mit Verkettung der Überläufer
|
Ein Lösungsansatz besteht in der Verkettung von Überläufern deren Hashfunktion Synonyme produziert. Dies geschieht rechts bei den Werten 0 und 50. Der Zugriffsaufwand ohne Synonyme für EInfügen und Lesen ist hier O(1). Liegen Synonyme vor ist der Aufwand O(n). Die Verkettung funktioniert wenn in die Hashtabelle nur Zeiger eingetragen werden. |
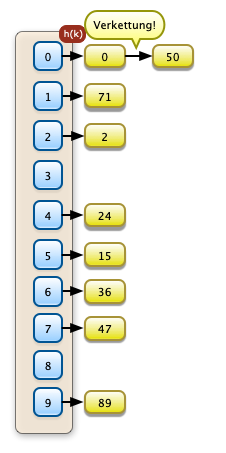 |
Offene Hashverfahren
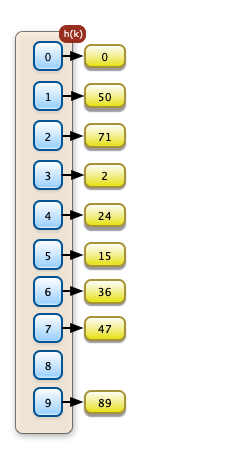 |
Sollen die Objekte direkt im Feld gespeichert werden, muß man sich im Feld einen neuen Platz suchen. Im Schaubild links, wurde zuerst die "0" auf ihrem Platz korrekt eingetragen. Als nächstes wurde die "50" eingetragen. Für sie war der Platz 0 schon belegt. Sie wurde auf dem Platz 1 eingetragen. Dann wurde die "71" eingetragen. Ihre Position 1 war schon belegt. Sie wurde auf der Position 2 eingetragen. Der Eintrag der "2" auf der Position 2 war auch nicht mehr möglich. Sie musste auf der Position 3 gespeichert werden. Ein Überläufer kann hier einen Ketteneffekt produzieren. Das Einfügen und das Finden können aufwendiger werden. Diese Operationen können im schlimmsten Fall den Aufwand O(n) haben. |
Hashverfahren robust gegen Sonderfälle zu machen ist recht aufwendig und sprengt den Rahmen dieser Vorlesung.
- 527 views
Teile und Herrsche Paradigma
Teile und Herrsche ParadigmaGrundprinzip[ (nach Wikipedia)
Bei einem Teile-und-herrsche-Ansatz wird das eigentliche – in seiner Gesamtheit – als zu schwierig erscheinende Problem so lange rekursiv in kleinere und einfachere Teilprobleme zerlegt, bis diese gelöst („beherrschbar“) sind. Anschließend wird aus diesen Teillösungen eine Lösung für das Gesamtproblem (re-)konstruiert.
Resourcen
- 1179 views
Lernziele
Lernziele|
|
Am Ende dieses Blocks können Sie:
|

Referenzen
T.Ottmann / P.Widmayer: Algorithmen und Datenstrukturen: Kapitel Sortieren
Lernzielkontrolle
Sie sind in der Lage die folgenden Fragen zu beantworten: Fragen zu Algorithmen
Feedback
- 3378 views
Datenstrukturen
DatenstrukturenEinführung
Das Zusammenfassen von Objekten, Datenstrukturen zu einer Menge von Objekten ist eine typische Anforderung in der Informatik. Zur Lösung dieses Anforderung müssen die folgenden Aspekte betrachtet werden:
- Ist die Menge der Objekte statisch oder kann sie sich veränderen. Ist sie dynamisch?
- Bilden die Elemente der Menge eine bestimmte Reihenfolge?
- Ist die Position des Elements in der Menge wichtig? Muss das Objekt über seine Position zugreifbar sein?
- Sollen Elemente zur Laufzeit zur Menge hinzugefügt oder entfernt werden können?
- Reicht es zu wissen, dass ein Element zur Menge gehört?
- Muss der Zugriff der Elemente über eine Nachbarschaftsbeziehung gegeben sein?
- Müssen die Elemente einer bestimmten Sortierreihenfolge genügen (z. Bsp. lexikographische Ordnung?)
- Ist es erlaubt Duplikate in der Menge zu verwalten?
Beispiele aus dem echten Leben
Welche der oben geforderten Kriterien gelten hier?
- Bierkasten mit Bierflaschen (Antialkoholiker mögen mit einem Kasten Sprudel arbeiten)
- Schulheft mit Seiten
- Ringbuch mit Seiten
- Ringbuch mit Seiten und Trennern
Felder
Die bisher verwendete Datenstruktur zum Verwalten von Objekten war das Feld (Array). Ein Feld hat die folgenden Vorteile:
- Sehr schneller, indexierter Zugriff auf ein Objekt über dessen Position im Feld: O(1)
- Konstante Größe
Diesen Vorteilen stehen die folgenden Nachteile gegenüber:
- Aufwändiges Einfügen: O(n)
- Feld muss bei einer nötigen Vergrößerung umkopiert werden.
Die Referenz ist die zweite Datenstruktur mit der Objekte verwaltet werden können. Sie erlaubt jedoch nur den direkten Zugriff auf ein einzelnes Objekt.
Dynamische Datenstrukturen
Zur Verwaltung von beliebig vielen Objekten verwendet man dynamische Datenstrukturen in Java die man durch Verkettung von Objekten mit Objektreferenzen erhält.
Die Datenstrukturen sind dynamisch, da während der Laufzeit beliebig viele Objekte in sie eingefügt oder aus ihnen entfernt werden können. Die Anzahl ihrer Objekte (Knoten) ist nicht vorab festgelegt.
| Knoten |
|---|
| Ein Knoten ist ein Bestandteil einer verkettenden, dynamischen Datenstruktur. In Java werden Knoten durch Objekte und Referenzen, die auf die Knoten zeigen, realisiert |
Verketteten Datenstrukturen können linear (nicht verzweigt) oder auch verzweigt sein.
- Lineare Datenstrukturen sind typischerweise Listen, Warteschlangen, Stacks
- Verzweigte Datenstrukturen finded man typischerweise in Bäumen
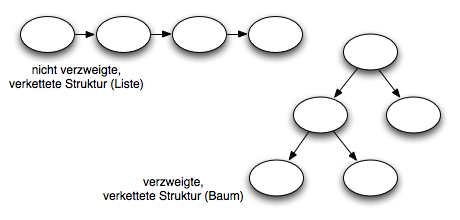
Vertreter dynamischer Datenstrukturen
- 8101 views
Listen
ListenListen sind verkettete Datenstrukturen, die im Gegensatz zu Feldern dynamisch wachsen können um beliebig viele Elemente (Knoten) zu verwalten. Sie werden anstatt Felder verwendet wenn
- die maximale Größe nicht vorab bekannt ist
- kein wahlfreier Zugriff auf beliebige Listenelemente (bzw. Knoten) benötigt wird.
- die Reihenfolge der Knoten wichtig ist.
Typische Operationen die für Listen zur Verfügung stehen sind:
| Operation | Beschreibung | Aufwand |
|---|---|---|
| Einfügen | Einfügen von Knoten in die Liste | O(n) |
| Entfernen | Entfernen von Knoten aus der Liste | O(n) |
| Tauschen | Veränderung der Knotenreihenfolge | O(n) |
| Länge bestimmen | Bestimmung der Länge der Liste (bei Pflege der Länge) | O(1) |
| Existenz | Abfrage ob ein Knoten in der Liste enthalten ist | O(n) |
| Einfügen am Kopf/Ende | Bei Pflege von Zeigern auf Anfang und Ende der Liste! | O(1) |
Mit Hilfe von Listen können auch spezialisiertere Datenstrukturen wie Warteschlangen (engl. queues) oder Stapel (engl. stack) implementiert werden.
Listen in Java
Eine verkettete Datenstruktur kann mit jeder Javaklasse aufgebaut werden die in der Lage ist auf Objekte der gleichen Klasse zu zeigen.
Eine solche Verkettung kann man zum Beispiel mit jeder Klasse implementieren, die die folgende Schnittstelle implementiert:
package s2.listen;
/**
*
* @author s@scalingbits.com
*/
public interface EinfacherListenknoten {
/**
* Einfuegen eines Nachfolgers
* @param n einzufuegender Listenknoten
*/
public void setNachFolger(EinfacherListenknoten n);
/**
* Auslesen des Nachfolgers
* @return der Nachfolger
*/
public EinfacherListenknoten getNachfolger();
}
Dies geschieht im folge für die Klasse Ganzzahl, die neben der Listeneigenschaft auch in der Lage ist eine Ganzzahl zu verwalten:
package s2.listen;
/**
*
* @author s@scalingbits.com
*/
public class Ganzzahl implements EinfacherListenknoten {
public int wert;
private EinfacherListenknoten naechsterKnoten;
public Ganzzahl(int i) {
wert = i;
naechsterKnoten = null;
}
/**
* Einfuegen eines Nachfolgers
* @param n einzufuegender Listenknoten
*/
@Override
public void setNachFolger(EinfacherListenknoten n) {
naechsterKnoten = n;
}
/**
* Auslesen des Nachfolgers
* @return der Nachfolger
*/
@Override
public EinfacherListenknoten getNachfolger() {
return naechsterKnoten;
}
/**
* Hauptprogramm zum Testen
* @param args
*/
public static void main(String[] args) {
Ganzzahl z1 = new Ganzzahl(11);
Ganzzahl z2 = new Ganzzahl(22);
Ganzzahl z3 = new Ganzzahl(33);
z1.setNachFolger(z2);
z2.setNachFolger(z3);
}
}In UML:
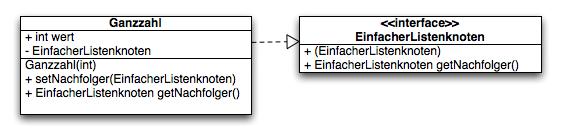
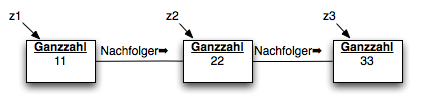
Zum Zugriff auf diese Liste reicht jetzt die Referenzvariable z1. Alle anderen Knoten können mit Hilfe der Methode getNachfolger() erreicht werden. Es existiert jedoch kein wahlfreier Zugriff auf die Knoten der Liste.
Werden die beiden Variablen z2 und z3 dereferenziert, können die einzelnen Knoten nach wie vor erreicht werden:
z2 = null; z3 = null;
Wird die Variable z1 dereferenziert,
z1 = null;
sind alle drei Objekte nicht mehr erreichbar und können vom Garbagekollektor gelöscht werden.
Unsortierte Listen
Im einfachsten Fall kann eine Liste als einfach verzeigerte Liste implementiert die nur auf den Kopfknoten zeigt.
- Das Einfügen und Löschen am Kopfende hat einen konstanten Aufwand
- Das Suchen bzw. Löschen von Knoten hat einen Aufwand von O(n)
- Relativer Zugriff von einem bekannten Knoten ist nur in Richtung der Nachfolger möglich.
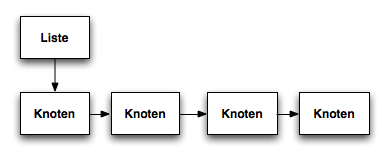
Bei Listen kann man auch das Ende der Liste im Listenobjekt mit pflegen. Einfüge- und Entnahmeoperationen werden hierdurch aufwendiger zu implementieren. Der Vorteil liegt jedoch darin, dass auf das Ende der Liste wahlfrei zugegriffen werden kann.
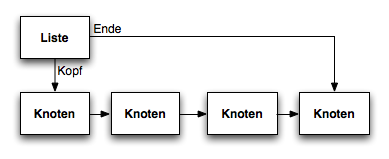
Vorteile einfach verzeigerter Listen mit Referenz auf das Ende der Liste
- Zugriff auf das und erste und letzte Element der Liste mit konstantem Aufwand
- Iterieren über die Menge aller Listenelemente ist möglich
- Löschen des letzten Elements ist mit konstantem Aufwand möglich (Hierdurch kann eine Warteschlange implementiert werden)
Nachteile
- Kein wahlfreier Zugriff auf alle Elemente
- Man kann nur auf ein Nachbarelement (den Nachfolger) mit konstantem Aufwand zugreifen
Zweiseitig verzeigerte Listen haben den Vorteil, dass sie einen direkten Zugriff auf den Vorgängerknoten sowie auf den Nachfolgerknoten haben:
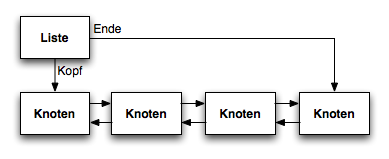
Vorteile (über die einfach verzeigerte Liste hinaus):
- Iterieren ist in zwei Richtungen möglich
- Der Vorgängerknoten eines Listenknoten kann auch mit konstantem Aufwand errreicht werden
- 6867 views
Übungen (Listen)
Übungen (Listen)Doppelt verzeigerte Liste mit Referenz auf das Ende der Liste
Implementieren Sie eine doppelt verzeigerte Liste zur Verwaltung ganzer Zahlen. Der Listenkopf referenziert auf das Kopfelement sowie auf das letzte Element der Liste
Eine Liste mit drei Knoten soll wie folgt implementiert sein:
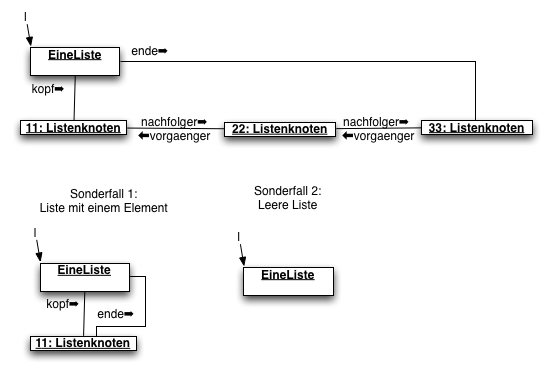
Beachten Sie die die beiden Sonderfälle einer Liste mit einem Element und den Sonderfall einer leeren Liste.
Zur beschleunigten Implementierung sind alle Klassen schon gegeben
- ListenKnoten: Eine einfache Klasse zur Verwaltung ganzer Zahlen mit Referenzen auf Vorgänger- und Nachfolgerknoten
- MainTestListe: Ein Hauptprogramm mit diversen Testroutinen zum Testen der Liste
- EineListe: Eine Rahmenklasse die vervollständigt werden soll. Implementieren Sie die folgenden Methoden:
- einfuegeAnKopf(einfuegeKnoten): Einfügen eines Knotens am Kopf der Liste
- laenge(): Berechnung der Länger der Liste
- loesche(Knoten): Löschen eines Knotens einer Liste
- enthaelt(Knoten): Prüfung ob ein Knoten in der Liste enthalten ist. Die Prüfung erfolgt auf Objektidentität, nicht auf Wertgleichheit
- einfuegeNach(nachKnoten,einfuegeKnoten): Einfügen eines neuen Knotens einfuegeKnoten hinter dem Knoten nachKnoten
 |
Warum werden die Methoden in EineListe und nicht in ListenKnoten implementiert?
|
UML Diagramm der drei Klassen:
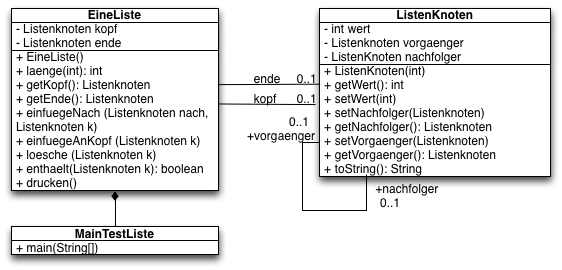
Klasse Listenknoten
package s2.listen;
/**
*
* @author s@scalingbits.com
*/
public class Listenknoten {
private Listenknoten vorgaenger;
private Listenknoten nachfolger;
private int wert;
public Listenknoten(int einWert) { wert=einWert;}
public Listenknoten getNachfolger() { return nachfolger;}
public void setNachfolger(Listenknoten nachfolger) {
this.nachfolger = nachfolger;
}
public Listenknoten getVorgaenger() {
return vorgaenger;
}
public void setVorgaenger(Listenknoten vorgaenger) {
this.vorgaenger = vorgaenger;
}
public int getWert() {
return wert;
}
public void setWert(int wert) {
this.wert = wert;
}
/**
* Erlaubt den Zahlenwert als Text auszudrucken
* @return
*/
@Override
public String toString() { return Integer.toString(wert);}
}Klasse EineListe
Vervollständigen Sie die folgende Klasse
package s2.listen;
/**
*
* @author s@scalingbits.com
*/
public class EineListe {
protected Listenknoten kopf;
protected Listenknoten ende;
/**
* Konstrukor. Erzeuge eine leere Liste
*/
public EineListe() {
kopf = null;
ende = null;
}
/**
* Berechne die Länge der Liste
* @return Länge der Liste
*/
public int laenge() {
int laenge = 0;
System.out.println("1. Implementieren Sie EineListe.laenge()");
return laenge;
}
/**
* Liefert den Kopf der Liste oder einen Null Zeiger
* @return
*/
public Listenknoten getKopf() {
return kopf;
}
/**
* Liefert das Ende der Liste oder einen Null Zeiger
* @return
*/
public Listenknoten getEnde() {
return ende;
}
/**
* Drucke eine Liste alle Objekte auf der Konsole
*/
public void drucken() {
System.out.println("Länge Liste: " + laenge());
Listenknoten k = kopf;
while (k != null) {
System.out.println("Knoten: " + k);
k = k.getNachfolger();
}
}
/**
* Füge hinter dem Listenknoten "nach" den Knoten "k"ein.
* Füge nichts ein wenn der Listenknoten "nach" nicht in der Liste
* vorhanden ist
* @param nach
* @param k
*/
public void einfuegeNach(Listenknoten nach, Listenknoten k) {
System.out.println("5. Implementieren Sie EineListe.einfuegeNach()");
}
/**
* Füge einen Listenknoten am Kopf der Liste ein
* @param k neuer Listenknoten
*/
public void einfuegeAnKopf(Listenknoten k) {
System.out.println("2. Implementieren Sie EineListe.einfuegeAnKopf()");
}
/**
* Lösche einen Knoten aus der Liste. Mache nichts falls es nichts zu
* gibt
* @param k zu löschender Listenknoten
*/
public void loesche(Listenknoten k) {
System.out.println("3. Implementieren Sie EineListe.loesche()");
} // Ende Methode loesche()
/**
* Ist wahr wenn ein Knoten mit dem gleichen Wert existiert
* @param k
* @return
*/
public boolean enthaelt(Listenknoten k) {
boolean result = false;
System.out.println("4. Implementieren Sie EineListe.enthaelt()");
return result;
} // Ende Methode enhaelt()
} // Ende der Klasse EineListeKlasse MainTestListe
package s2.listen;
/**
*
* @author s@scalingbits.com
*/
public class MainTestListe {
/**
* Testroutinen für einfache Listen
* @param args
*/
public static void main(String[] args) {
EineListe testListe = new EineListe();
einfuegeTest(testListe, 4, 6);
System.out.println("Kontrolle: Drei Knoten von 4 bis 6");
einfuegeTest(testListe, 1, 3);
System.out.println("Kontrolle: Sechs Knoten von 1 bis 6");
einfuegeTest(testListe, 21, 27);
System.out.println("Kontrolle: 13 Knoten von 21 bis 27, 1 bis 6");
loeschenEndeTest(testListe, 3);
System.out.println("Kontrolle: 10 Knoten von 21 bis 27, 1 bis 3");
loeschenKopfTest(testListe, 8);
System.out.println("Kontrolle: 2 Knoten von 2 bis 3");
loeschenKopfTest(testListe, 3);
System.out.println("Kontrolle: 0 Knoten. Versuch löschen in leerer Liste");
enthaeltTest(testListe, 10);
System.out.println("Kontrolle: Einfügen in der Liste");
testListe = new EineListe();
einfuegeNachTest(testListe, 10);
}
/**
* Einfügen einer Reihe von Zahlen in eine gegebene Liste
* @param l Liste in die eingefügt wird
* @param min kleinster Startknoten der eingefügt wird
* @param max größter Knoten der eingefügt werden
*/
public static void einfuegeTest(EineListe l, int min, int max) {
System.out.println("Test: Einfügen am Kopf [" + min + " bis " + max + "]");
for (int i = max; i >= min; i--) {
l.einfuegeAnKopf(new Listenknoten(i));
System.out.println("Länge der Liste: " + l.laenge());
}
l.drucken();
}
/**
* Lösche eine bestimmte Anzahl von Knoten am Ende der Liste
* @param l Liste aus der Knoten gelöscht werden
* @param anzahl der zu loeschenden Knoten
*/
public static void loeschenEndeTest(EineListe l, int anzahl) {
System.out.println("Test: Löschen am Ende der Liste " + anzahl + "fach:");
for (int i = 0; i < anzahl; i++) {
l.loesche(l.ende);
System.out.println("Länge der Liste: " + l.laenge());
}
l.drucken();
}
public static void loeschenKopfTest(EineListe l, int anzahl) {
System.out.println("Test: Löschen am Kopf der Liste " + anzahl + "fach:");
for (int i = 0; i < anzahl; i++) {
l.loesche(l.getKopf());
System.out.println("Länge der Liste: " + l.laenge());
}
l.drucken();
}
public static void enthaeltTest(EineListe l, int groesse) {
System.out.println("Test: enhaelt() " + groesse + " Elemente");
Listenknoten[] feld = new Listenknoten[groesse];
for (int i = 0; i < groesse; i++) {
feld[i] = new Listenknoten(i * 10);
l.einfuegeAnKopf(feld[i]);
}
l.drucken();
for (int i = 0; i < groesse; i++) {
if (l.enthaelt(feld[0])) {
System.out.println("Element " + feld[i] + " gefunden");
}
}
System.out.println("Erfolg wenn alle Elemente gefunden wurden");
Listenknoten waise = new Listenknoten(4711);
if (l.enthaelt(waise)) {
System.out.println("Fehler: Element gefunden welches nicht zur Liste gehört!");
} else {
System.out.println("Erfolg: Element nicht gefunden welches nicht zur Liste gehört");
}
}
public static void einfuegeNachTest(EineListe l, int max) {
System.out.println("Test: einfügen nach " + max + "fach");
Listenknoten[] feld = new Listenknoten[max];
for (int i = 0; i < max; i++) {
feld[i] = new Listenknoten(i*10);
l.einfuegeAnKopf(feld[i]);
}
System.out.println("Länge der Liste: " + l.laenge());
for (int i = 0; i < max; i++) {
l.einfuegeNach(feld[i], new Listenknoten(feld[i].getWert()+1));
System.out.println("Länge der Liste: " + l.laenge());
}
l.einfuegeNach(l.ende, new Listenknoten(111));
l.drucken();
}
}
- 5557 views
Lösungen
LösungenDoppelt verzeigerte Liste mit Referenz auf das Ende der Liste
Klasse EineListe
Hinweis: Ändern Sie den Namen von EineListeLoseung an den zwei Stellen zu EineListe.
package s2.listen;/**
*
* @author s@scalingbits.com
*/
public class EineListeLoesung {
protected Listenknoten kopf;
protected Listenknoten ende;
public EineListeLoesung() {
kopf = null;
ende = null;
}
/**
* Berechnet die Anzahl der Listenelemente
* @return Anzahl der Listenelemente
*/
public int laenge() {
int laenge = 0;
Listenknoten zeiger = kopf;
while (zeiger != null) {
laenge++;
zeiger = zeiger.getNachfolger();
}
return laenge;
}
/**
* Liefert den Kopf der Liste oder einen Null Zeiger
* @return Zeiger auf Kopf der Liste
*/
public Listenknoten getKopf() {
return kopf;
}
/**
* Liefert das Ende der Liste oder einen Null Zeiger
* @return Zeiger auf das Ende der Lister
*/
public Listenknoten getEnde() {
return ende;
}
/**
* Drucke eine Liste alle Objekte auf der Konsole
*/
public void drucken() {
System.out.println("Länge Liste: " + laenge());
Listenknoten k = kopf;
while (k != null) {
System.out.println("Knoten: " + k);
k = k.getNachfolger();
}
}
/**
* Füge hinter dem Listenknoten "nach" den Knoten "k"ein.
* Füge nichts ein wenn der Listenknoten "nach" nicht in der Liste
* vorhanden ist
* @param nach
* @param k
*/
public void einfuegeNach(Listenknoten nach, Listenknoten k) {
Listenknoten t;
t = kopf; // Diese Variable wird über die Listenknoten laufen
while ((t != null) && (t != nach)) {
// Iteriere über die Liste solange Knoten existieren
// und kein passender gefunden hier
t = t.getNachfolger();
}
if (t == nach) { // Der Knoten wurde gefunden
// Merken des Nachfolger hinter der Einfuegestelle
Listenknoten derNaechste = nach.getNachfolger();
if (derNaechste != null) {
// Setzen des neuen Vorgängers falls es einen Nachfolger gab
derNaechste.setVorgaenger(k);
} else { // Wir haben am Ende eingefuegt. Ende-Zeiger korrigieren
ende = k;
}
// Der neu eingefügte Knoten soll auf den Nachfolger zeigen
k.setNachfolger(derNaechste);
// Der gesuchte Knoten ist der Vorgaenger. Der neue Knoten
// soll auf ihn zeigen
k.setVorgaenger(t);
// Der Vorgaenger soll auf den neu einfeügten Knoten zeigen
t.setNachfolger(k);
}
}
/**
* Füge einen Knoten am Anfang der Liste ein
* @param k
*/
public void einfuegeAnKopf(Listenknoten k) {
k.setVorgaenger(null);
if (kopf == null) { // Die Liste ist leer
ende = k; // Das Ende ist auch der Kopf
k.setNachfolger(null); // Sicherstellen das kein Nachfolger benutzt wird
} else { // Liste ist nicht leer
k.setNachfolger(kopf); // Neuer Nachfolger ist alter Kopf
kopf.setVorgaenger(k); // Alter Kopf bekommt Vorgaenger
}
kopf = k; // Es gibt einen neuen Kopf. Heureka
}
public void loesche(Listenknoten k) {
Listenknoten t = kopf; // Diese Variable wird über die Listenknoten laufen
if (kopf == null) {
System.out.println("Löschversuch auf leerer Liste");
} else {
//Pflege der Kopf- bzw Endezeiger
if (kopf == k) {
// Das Kopfelement wir geloescht
kopf = k.getNachfolger(); //Kann auch Null sein...
}
if (ende == k) {
// Das zu loeschende Objekt ist das Letzte
ende = k.getVorgaenger(); // Kann auch Null sein...
}
while ((t != null) && (t != k)) {
// Iteriere über Liste solange Nachfolger da sind
// und nichts passendes gefunden wird
t = t.getNachfolger();
}
if (t == k) { // Der Knoten wurde gefunden
Listenknoten nachf = k.getNachfolger();
Listenknoten vorg = k.getVorgaenger();
if (nachf != null) {
// Es gibt einen Nachfolger. Pflege dessen Vorgaenger
nachf.setVorgaenger(vorg);
}
if (vorg != null) {
// Es gibt einen Vorgaenger. Pflege dessen Nachfolger
vorg.setNachfolger(nachf);
}
// Entfernen aller Referenzen des geloeschten Objekts
t.setNachfolger(null);
t.setVorgaenger(null);
} // Ende der Knoten wurde gefunden
} // Ende Loeschen aus einer nicht leeren Liste
} // Ende Methode loesche
/**
* Ist wahr wenn ein Knoten mit dem gleichen Wert existiert
* @param k
* @return
*/
public boolean enthaelt(Listenknoten k) {
Listenknoten t = kopf;
boolean result = false;
while ((result == false) && (t != null)) {
result = (t == k);
if (!result) {
t = t.getNachfolger();
}
}
return result;
} // Ende Methode enhaelt()
} // Ende der Klasse EineListe
- 3713 views
Stapel (Stack)
Stapel (Stack)Der Stapel (engl. Stack) ist eine der wichtigsten Grundstrukturen der Informatik. Er funktioniert nach dem Prinzip, dass man bildlich gesprochen Elemente stapelt und immer nur auf das oberste Element des Stapels zugreifen kann um es zu lesen oder zu entfernen. Stapel werden daher im Englischen auch mit LIFO abgekürzt:
| LIFO: Last In First Out |
Hierdurch ergeben sich die typischen Operationen die für einen Stapel (in englisch) definiert sind:
| Operation | Erklärung | Aufwand |
|---|---|---|
| peek | Lesen der obersten Datenstruktur ohne sie zu entfernen | O(1) |
| pop | Lesen der obersten Datenstruktur und gleichzeitiges Entfernen | O(1) |
| push | Einfügen einer neuen Datenstruktur als oberste Datenstruktur | O(1) |
| search | Suche nach einer Datenstruktur im Stapel und Rückgabe der Position (naive Implementierung) | O(n) |
Java verfügt bereits über eine Implementierung von Stapeln in der Klasse java.util.Stack in der die oben genannten Operationen als Methoden für beliebige Instanzen der Klasse Object zur Verfügung stehen.
Stapel sind im realen Leben nicht ganz so häufig anzutreffen wie in der Informatik. Ein sehr gutes Beispiel aus dem realen Leben sind
- Teller die typischerweise aufeinander gestapelt werden. Der letzte Teller den man auf einen Stapel von Tellern legt ist auch typischerweise der erste Teller den man wieder von einem Stapel nimmt.
- Passagiere die eine Flugzeug besteigen und es dann in umgekehrter Reihenfolge verlassen. (Die strenge Implementierung eines Stapel/Stacks ohne Ausnahmen ist hier weder für die Fluggesellsschaft noch für die Passagiere akzeptabel)
- Eine Einzelgarage mit einem Fahrzeugabstellplatz vor der Garage. Dies ist ein Stapel/Stack der Tiefe zwei
- Ein Abstellgleis mit Prellbock.
In der Informatik sind Stapel sehr nützlich, wann immer man einen Zustand speichern muss um sich etwas Anderem zu widmen, und dann wieder auf den alten Zustand zurückzugreifen. Beispiele hierfür sind
- Verwalten von Variablen bei Methodenaufrufen in Java: Beim jedem Aufruf einer Methode werden die Variablen der aktuellen Methode auf von den Variablen der aufgerufenen Methode verdeckt(Push). Die Variablen der aufgerufenen Methode sind eine Datenstruktur die neu auf den Stapel gelegt wurden und die Variablen der alten Methode verdecken. Nach dem Abarbeiten der neuen Methode werden deren Variablen wieder gelöscht(Pop) und die Variablen der vorhergehenden Methode stehen wieder zur Verfügung
- Parsen (Analysieren) von Programiersprachen, Ausdrücken und Termen wie zum Beispiel ein mathematischer Term: 5 + 4*3. Hier wird bei der Analyse von 5 und "+" festgestellt, dass der zweite Operand (4*3) selbst wieder ein Term ist. Das Parsen der Addition wird angehalten. Die nötigen Datenstrukturen zum Parsen der Multiplikation werden angelegt und verdecken die Addition(Pop). Der Wert von 4*3 wird berechnet. Alle Datenstrukturen die zur Berechnung der Multiplikation benötigt wurden können jetzt wieder gelöscht werden (POP) um mit der ursprünglichen Multiplikation fortzufahren.
Beispiel: Die Auswertung des Terms 5+4*3
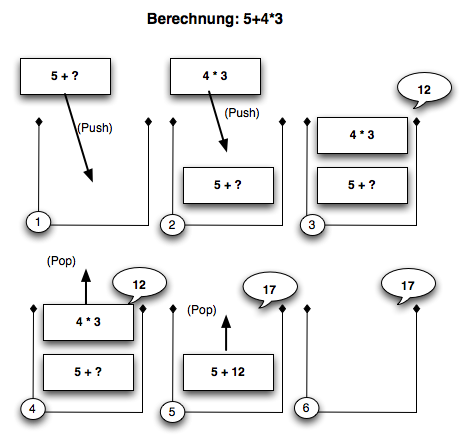
- 11536 views
Warteschlangen (Queues)
Warteschlangen (Queues)Warteschlangen (engl. queues) sind Datenstrukturen die auf dem FIFO Prinzip basieren:
| FIFO: First In, First Out |
Die Objekte die zuerst eingefügt werden, werden auch als erstes wieder ausgelesen. Warteschlangen erhalten die Reihenfolge der Ankunft indem Sie immer nur Objekte am Kopf entnehmen und immer nur Objekte am Ende der Warteschlange einfügen. Typische Operationen auf einer Warteschlange sind:
| Operation | Erklärung | Aufwand |
|---|---|---|
| peek | Lesen der Datenstruktur am Kopf der Warteschlange ohne sie zu entfernen | O(1) |
| read | Lesen der vordersten Datenstruktur am Kopf und gleichzeitiges Entfernen | O(1) |
| write | Einfügen einer neuen Datenstruktur am Ende der Warteschlange | O(1) |
| search | Suche nach einer Datenstruktur in der Warteschlange und Rückgabe der Position | O(n) |
| empty | Testen ob die Warteschlange leer ist | O(1) |
Wichtig: Warteschlangen bieten keinen wahlfreien Zugriff auf alle ihre Elemente
Warteschlangen sind im realen Leben häufig anzutreffen wenn es sich um Prozesse handelt die alle Beteiligten demokratisch, transparent (fair?) behandeln soll:
- Fließband
- Rolltreppe
- Warten bei vielen Dienstleistern wird als FIFO organisiert
In der Informatik sind Warteschlangen immer dann anzutreffen wenn die Erhaltung einer Ankunftsreihenfolge eine Rolle spielt:
- Datenbanksperren
- Eingehende Webserveranforderungen
- Transaktionales Arbeiten (Sitzplatzreservierung)
Implementierung
Warteschlange sind Spezialfälle von Listen. Im Unterschied zu einer Liste erlauben sie nur das Einfügen von Objekten am Ende und das Entfernen am Kopf der Warteschlange:
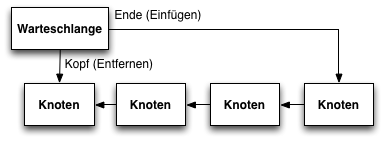
Ringpuffer
Warteschlangen die auf einfach oder zweifach verketteten Knoten beruhen sind sehr flexibel. Sie sind jedoch auch ineffizient da bei jedem Aufruf neue Knotenobjekte mit dem aufwendigen new() Operator erzeugt werden müssen.
Dies kann durch die Verwendung von ausreichend großen Ringpuffern vermieden werden, da hier die Knotenobjekte nur einmalig angelegt werden müssen. Diese Ringpuffer werden durch ein Feld R mit einer festen Größe n implementiert. Beim Erreichen des Endes des Feldes wird dieses durch ein Fortsetzen am Beginn des Feldes zum Ring "zusammengebogen".
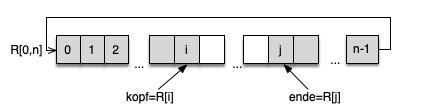
Hierzu benötigt man:
- einen Zeiger auf das Ende der Warteschlange (im Beispiel R[j])
- einen Zeiger auf den Kopf der Warteschlange (Im Beispiel R[i])
Beim Einfügen und Entfernen von Elementen werden beim Verrücken der Zeiger der Restwert nach der Division durch die Größe des Felds verwendet um nicht einen Feldüberlauf zu Erzeugen. Beim Einfügen eines neuen Elements in den Ringpuffer wird das neue Ende in Java wie folgt berechnet:
ende = (ende-1)%n;
Der Kopf wird nach dem Entfernen eines Elements wie folgt berechnet:
kopf = (kopf-1)%n;
Wichtig: Ringpuffer haben eine feste Größe. Es muss explizit eine Ausnahmebehandlung implementiert werden, wenn die Warteschlange über die Größe n des Feldes wächst.
- 9216 views
Implementierung
Unter "Implementierung" steht, dass Warteschlangen nur das Einfügen und Entfernen von Objekten am Ende der Warteschlange erlauben.
Nach dem FIFO-Prinzip müsste aber das Entfernen am Kopf der Warteschlange geschehen und nicht am Ende, damit auch das zuerst eingefügte Element als erstes wieder entfernt wird.
- Log in to post comments
Stimmt, irgendwie schon
Danke für den Hinweis. Ich habe das Skript angepasst. Kopf und Ende wurde hier etwas lax verwendet. Ich habe das Diagramm angepasst und nur noch eine Verzeigerung in eine Richtung eingemalt. Hierdurch sollte es keine Zweifel mehr geben.
- Log in to post comments
Ringpuffer Grafik
Ist es richtig so, dass der kopf=r[j] und das ende auch =r[j] ist?
Sind beim Ringpuffer Anfang und Ende identisch, wenn das Feld sein Ende erreicht hat?
Dachte, dass das nicht so wäre, weshalb mich die Grafik da gerade etwas verwirrt.
- Log in to post comments
Vielen Dank!
Toll beobachtet. Habe den Fehler im Diagramm korrigiert. Vielen Dank.
- Log in to post comments
Bäume
BäumeBäume werden in vielen Bereichen der Informatik verwendet, da Suchen und Einfügen sehr effizient erfolgen können
| Operation | Erklärung | Aufwand | Schlimmster Fall |
|---|---|---|---|
| Einfügen/Löschen | Ändern des Baums | O(log(n)) | O(n) |
| Suchen | Suchen eines Elements | O(log(n)) | O(n) |
| Nächstes Element | Finden des nächsten Elements | O(1) | O(1) |
Da naiv implementierte Bäume degenerieren können und dann die Aufwände einer Liste haben, werden in der Vorlesung einige, wenige Optimierungen diskutiert. Diese Optimierung unterbinden den schlimmsten Fall eines Aufwands mit der Ordnung O(n).
Bäume sind hierarchische Datenstrukturen die aus einer verzweigten Datenstruktur bestehen. Bäume bestehen aus Knoten und deren Nachfolgern.
Jeder Knoten in einem Baum hat genau einen Vorgängerknoten. Der einzige Knoten für den das nicht gilt, ist der Wurzelknoten (engl. root) er hat keinen Vorgänger. Der Wurzelknoten stellt den obersten Knoten dar. Von dieser Wurzel aus kann man von Knoten zu Knoten zu jedem Element des Baums gelangen.
| Rekursive Definition eines Baums |
|---|
| Ein Baum besteht aus Unterbäumen und diese setzen sich bis zu den Blattknoten wieder aus Unterbäumen zusammen. |
Die Baumstruktur wird in Ebenen unterteilt.
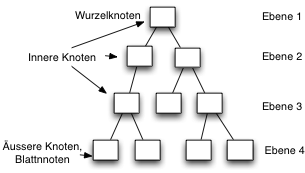
Die Tiefe eines Baumes ergibt sich aus der maximalen Anzahl der Ebenen.
Vollständige Bäume
| Vollständige Bäume |
|---|
| Ein Baum ist vollständig wenn alle Ebenen ausser der letzten Ebene vollständig mit Knoten gefüllt sind. |
Im folgenden Beispiel wird ein Baum gezeigt, der maximal drei Nachfolgerknoten pro Konten besitzen kann:
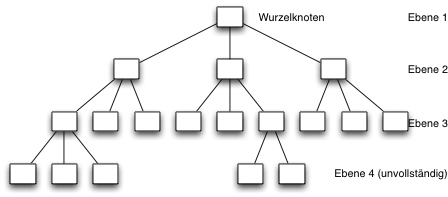
Binärbäume
Binärbäume bestehen aus Knoten mit maximal 2 Nachfolgerknoten. Die maximale Anzahl Knoten pro Ebene ist 2(k-1) Knoten in der Ebene k.
Streng sortierte Binärbäume
| Streng sortierte Binärbäume |
|---|
|
Für jeden Baumknoten gilt:
|
Beispiel eines streng sortierten Binärbaums:
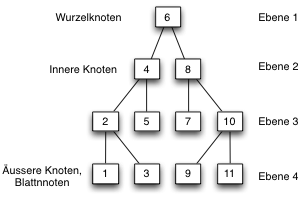
Suchen
Sortierte Binärbäume eignen sich sehr gut zum effektiven Suchen, da mit jedem Knoten die Auswahl der Kandidaten in der Regel halbiert wird.
Das Suchen in einem sortierten Baum geschieht nach dem folgenden, rekursiven Prinzip:
- Beginne mit dem Wurzelknoten
- Vergleiche den gesuchten Wert mit dem Wert des Knoten und beende die Suche wenn der Wert übereinstimmt.
- Suche im linken Teilbaum weiter wenn der gesuchte Wert kleiner als der aktuelle Knoten ist.
- Suche im rechten Teilbaum weiter wenn der gesuchte Wert größer als der Wert des aktuellen Knoten ist.
Bemerkung: Effektives Suchen ist nur in gutartigen (balancierten) Bäumen möglich. Gutartige Bäume haben möglichst wenig Ebenen. Schlechte Bäume zum Suchen sind degenerierte Bäume die im schlimmsten Fall pro Ebene nur einen Knoten besitzen. Solche degenerierten Bäume verhalten sich wie Listen.
Gutartige Bäume haben daher eine Tiefe T= ld(n+a) was auch dem Aufwand zum Suchen O (ld(n)) entspricht. Schlechte Bäume haben eine Tiefe T = n was zu einem Suchaufwand wie bei Listen, also O(n) führt.
Beispielprogramm
|
Das folgende Programm erlaubt es manuell einen Binärbaum aus Ganzzahlen aufzubauen. DownloadDas Programm steht als jar Datei zur Verfügung und kann nach dem Download wie folgt gestartet werden: java -jar BaumGUI.jar Es erlaubt das Einfügen und Entfernen von Blattknoten: |
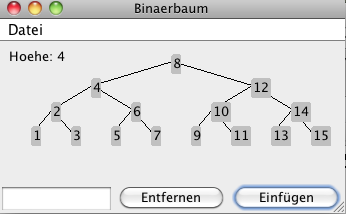 |
Alternative: Die Universität San Francisco hat eine sehr schöne webbasierte Visualisierung.
- 7944 views
AVL Bäume (Ausgeglichene Bäume)
AVL Bäume (Ausgeglichene Bäume)Binärbäume werden benutzt da sie ein sehr effizientes Suchen mit einem Aufwand von O(logN) erlauben solange sie balanciert sind. In extremen Fällen kann die Suche nach Knoten jedoch zu einem Aufwand von O(N) führen falls der Baum degeneriert ist.
Die im vorhergehenden Abschnitt vorgestellten Bäume verwenden in ihren Implementierungen der Einfüge- und Entferneoperation naive Verfahren. Diese naive Verfahren können dazu führen, dass ein Baum sehr unbalanciert werden kann.
Erste Vorschläge zur Vermeidung dieses Problems gehen auf die 1962 gemachten Vorschläge von Adelson-Velskij und Landis zurück. Sie schlugen höhenbalancierte AVL Bäume vor.
AVL Bäume
| AVL Baum |
|---|
|
Ein binärer Baum ist höhenbalanciert bzw AVL ausgeglichen wenn für jeden Knoten im Baum gilt:
|
Beispiele von AVL Bäumen die der obigen Definition genügen sind im folgenden Diagramm zu sehen
Der nachfolgende Baum ist kein AVL Baum. Der rechte Knoten in der zweiten Ebene von oben hat einen linken Unterbaum der Höhe 1 und einen rechten Unterbaum der Höhe 3.
Dieser Baum müsste umorganisiert werden um ein AVL Baum zu werden.
Zum Verwalten von AVL Bäumen berechet man jedoch nicht immer wieder die Höhe der Teilbäume.
Es ist einfacher einen Balanchefaktor zu jedem inneren Knoten mitzuführen der die Differenz der Höhe vom linken und rechtem Teilbaum verwaltet.
| Balancefaktor bal(p) eines AVL Baums |
|---|
|
bal(p) = (Höhe rechter Teilbaum von p) - (Höhe linker Teilbaum von p) bal(p)∈{-1,0,1} |
Im folgenden Beispiel sind die Balancefaktoren für die inneren Knoten eingetragen:
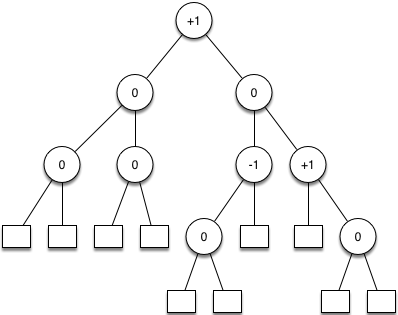
AVL Bäume müssen beim Einfügen und Entfernen von Knoten unter Umständen neu balanciert werden. Der Vorteil besteht jedoch in dem sehr vorhersagbaren Verhalten mit dem Aufwand von O(logN) bei Operationen auf dem Baum.
Tipp: Bauen Sie sich Ihren eigen AVL Baum. Die Universität hat eine web basierte Visualisierung von AVL Bäumen.
- 12073 views
Definition AVL-Baum, 2. Abb.
Kann es sein, dass bei den korrekten AVL-Bäumen unten rechts ein Kästchen fehlt? Dort ist bei einem Kreis lediglich ein Kästchen.
- Log in to post comments
Bruderbäume
BruderbäumeBruderbäume kann man als expandierte AVL Bäume verstehen.
Bruderbäume bekommen durch gezieltes Einfügen unärer Knoten eine konstante Tiefe für alle Blätter. Sie sind höhenbalancierte Bäume. Mit ihnen lässt sich garantieren, dass man mit dem gleichen Suchaufwand auf alle Blätter des Baums zugreifen kann.
Bruderbäume unterscheiden sich von den Binärbäumen dadurch, dass die inneren Knoten mindesten einen Sohn haben.
Bruderbäume haben ihren Namen von dem Fakt, dass für die Söhne eines Knoten untereinander (die Brüder) bestimmte Regeln gelten.
| Bruder |
|---|
| Zwei Knoten heißen Brüder wenn sie denselben Vater (Vorgängerknoten) haben. |
Ein binärer Baum ist ein Bruderbaum wenn das folgende gilt:
| Bruderbaum |
|---|
|
Ein Baum heißt Bruderbaum wenn die folgenden Bedingungen gelten:
|
Beispiele
Im folgenden Diagramm ist der rechte Baum ist kein Bruderbaum da es auf der zweiten Ebene von oben zwei unäre Bruder gibt.
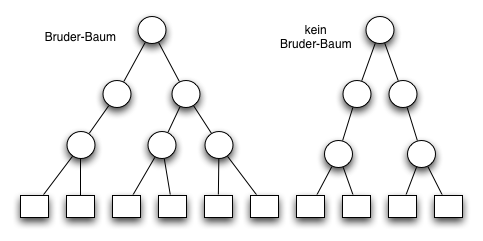
Im Diagramm unten ist der rechte Baum kein Bruderbaum weil die beiden Bruderknoten in der zweiten Ebene von oben unäre Brüder sind.
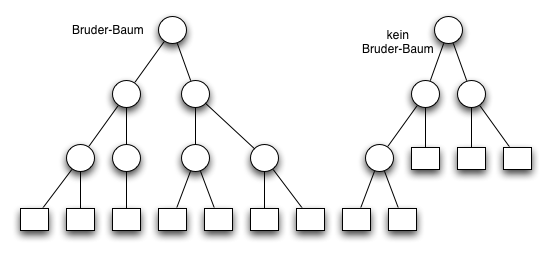
Bemerkung
Bei Bruderbäumen müssen bei Bedarf innerer Knoten eingefügt werden um die Bruderbedingungen zu erfüllen. Bruderbäume sind daher Bäume bei denen die zu verwaltenden Datenstrukturen nicht notwendigerweise in den inneren Knoten verwaltet werden können.
- 7814 views
Anzahl Söhne bei Bruderbäumen
Folgende, sich scheinbar widersprechende Aussagen entstammen Ihrem Skript. Was ist nun korrekt?
"Bruderbäume unterscheiden sich von den Binärbäumen dadurch, dass die inneren Knoten auch nur einen Sohn haben dürfen."
"Ein Baum heißt Bruderbaum wenn die folgenden Bedingungen gelten:
Jeder innere Knoten hat einen oder zwei Söhne."
- Log in to post comments
Gut beobachtet
Danke für den Kommentar.
Innere Knoten in Bruderbäumen müssen mindesten einen Sohn haben.
- Log in to post comments
Übungen (Bäume)
Übungen (Bäume)Balancierte und unbalancierte Bäume
Das folgende Programm erlaubt es manuell einen streng geordneten Binärbaum aus Ganzzahlen aufzubauen.
Das Programm steht als jar Datei zur Verfügung und kann nach dem Download wie folgt gestartet werden:
java -jar BaumGUI.jar
Balancierter Baum
Benutzen Sie das Beispielprogramm und erzeugen sie einen balancierten Baum mit 15 Knoten und der Höhe 4 wie zum Bsp.:
In welcher Reihenfolge müssen die Werte eingegeben werden?
Degenerierter Baum
Erzeugen Sie einen degenerierten Baum mit 5 Knoten und der Höhe 5:
Welche Eingabefolgen von Zahlen erzeugen eine Liste degenerierten Teilbäumen?
Implementierung einer Binärbaums
Alle Klassen zu dieser Übung sind auch über github verfügbar.
Implementieren Sie einen streng geordneten Binärbaum in dem man ganze Zahlen Einfügen und Löschen kann.
Es ist nicht notwendig einen balancierten Baum oder AVL Baum zu implementieren.
Vervollständigen Sie die 3 drei fehlenden Methoden:
- s2.baum.Baumknoten
- Methode hoehe() : Implementieren Sie eine rekursive Methode zum bestimmen der Höhe des Baums (1.ter Schritt)
- s2.baum.Binaerbaum
- Methode einfuegen(teilBaum, Knoten) (2.ter Schritt)
- Tipps
- Betrachten Sie zuerst Sonderfälle (fehlen von Söhnen)
- Welchen Teilbaum müssen Sie modifizieren wenn der neue Knoten kleiner als die aktuelle Wurzel ist?
- Welchen Teilbaum müssen Sie modifizieren wenn der neue Knoten größer als die aktuelle Wurzel ist?
- Fügen Sie keinen Knoten mit einem Wert ein, der schon existiert!
- Tipps
- Methode loeschen(teilBaum, Knoten) (3.ter Schritt)
- Tipps
- Was müssen Sie tun wen der aktuelle Knoten gelöscht werden muss?
- Was müssen Sie tun wenn der zu löschende Knoten die Wurzel des gesamten Baums ist?
- Tipps
- Methode einfuegen(teilBaum, Knoten) (2.ter Schritt)
Übersetzen Sie alle Klassen. Starten Sie die Anwendung mit
$ java s2.baum.BaumGUI
Testen Sie die Anwendung mit der automatisierten Generierung mit dem Befehl
$ java s2.baum.BaumGUI magic
Hinweis: Die Implementierung des Algorithmus zum Entfernen von Knoten ist sehr viel aufwendiger da viele Randbedingungen geprüft werden müssen. Implementieren Sie zu Beginn nur das Einfügen von Knoten und Testen Sie zuerst das Einfügen. Die aktuelle Trivialimplementierung zum Entfernen erlaubt das Übersetzen und Ausführen der Anwendung ohne das Knoten entfernt werden.
UML Diagramm der beteiligten Klassen:
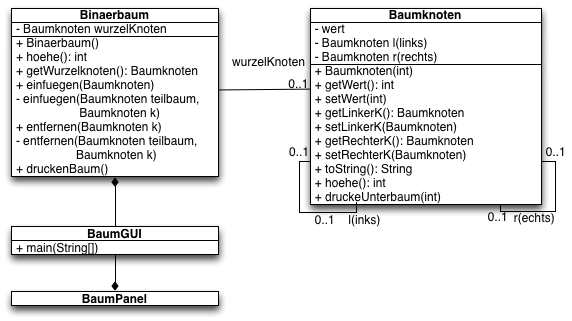
Notwendige Vorarbeiten
Erzeugen Sie die Infrastruktur für das folgenden Paket s2.baum
Klasse s2.baum.Baumknoten
package s2.baum;
/**
*
* @author s@scalingbits.com
*/
public class Baumknoten {
private int wert;
//private final int maxWert= Integer.MAX_VALUE;
private final int maxWert= 99;
public int getWert() {
return wert;
}
public void setWert(int wert) {
this.wert = wert;
}
/**
* Verwalte linken Knoten
*/
private Baumknoten l;
/**
* verwalte rechten Knoten
*/
private Baumknoten r;
public Baumknoten(int i) {wert=i;}
/**
* Liefere linken Knoten zurück
* @return linker Knoten
*/
public Baumknoten getLinkerK() {
return l;
}
/**
* Setze linken Knoten
* @param k Referenz auf linken Knoten
*/
public void setLinkerK(Baumknoten k) {
l = k;
}
/**
* Liefere rechten Knoten zurück
* @return rechter Knoten
*/
public Baumknoten getRechterK() {
return r;
}
/**
* Setze rechten Knoten
* @param k rechter Knoten
*/
public void setRechterK(Baumknoten k) {
r = k;
}
/**
* Drucken einen Unterbaum und rücke entsprechend bei Unterbäumen ein
* @param einruecken
*/
public void druckeUnterbaum(int einruecken) {
if (l != null) {
l.druckeUnterbaum(einruecken + 1);
}
for (int i = 0; i < einruecken; i++) {
System.out.print(".");
}
System.out.println(toString());
if (r != null) {
r.druckeUnterbaum(einruecken + 1);
}
}
/**
* Berechne Höhe des Baums durch rekursive Tiefensuche
* @return
*/
public int hoehe() {
System.out.println("Implementieren Sie Baumknoten.hoehe() als rekursive Methode");
return -1;
}
/**
* Generiere eine Zufallsbelegung für den gegebenen Knoten
* Die Funktion darf nicht mehr nach Einfügen in den Baum
* aufgerufen werden, da der neue Wert zu einer inkorrekten Ordnung führt
*/
public void generiereZufallswert() {
wert= (int)(Math.random()*(double)maxWert);
}
/**
* Erlaubt den Zahlenwert als Text auszudrucken
* @return
*/
public String toString() { return Integer.toString(wert);}
}
Klasse s2.baum.Binaerbaum
package s2.baum;
/**
*
* @author sschneid
*/
public class Binaerbaum {
private Baumknoten wurzelKnoten;
public Baumknoten getWurzelknoten() {return wurzelKnoten;}
/**
* Füge einen neuen Baumknoten in einen Baum ein
* @param s
*/
public void einfuegen(Baumknoten s) {
if (wurzelKnoten == null) {
// Der Baum ist leer. Füge Wurzelknoten ein.
wurzelKnoten = s;
}
else // Der Baum ist nicht leer. Normales Vorgehen
einfuegen(wurzelKnoten,s);
}
/**
* Füge einen gegebenen Knoten s in einen Teilbaum ein.
* Diese Methode ist eine rekursive private Methode
* Da der neue Knoten die Wurzel des neuen Teilbaums bilden kann,
* wird eventuell ein Zeiger auf einen neuen Teilbaum zurückgeliefert
* Randbedingung:
* * Es wird kein Knoten mit einem Wert eingefügt der schon existiertz
* @param teilbaum
* @param s
*/
private void einfuegen(Baumknoten teilbaum, Baumknoten s) {
System.out.println("Implementieren Sie die Methode Binaerbaum:einfuegen()");
}
/**
* Öffentliche Methoden zum Entfernen eines Baumknotens
* @param s
*/
public void entfernen(Baumknoten s) {
wurzelKnoten = entfernen(wurzelKnoten,s);}
/**
* Private, rekursive Methode zum Entfernen eines Knotens aus einem
* Teilbaum. Es kann ein neuer Teilbaum enstehen wennn der Wurzelknoten
* selbst entfernt werden muss. Der neue Teilbaum wird daher wieder mit
* ausgegeben
* @param teilbaum Teilbaum aus dem ein Knoten entfernt werden soll
* @param s der zu entfernende Knoten
* @return Der verbleibende Restbaum. Es kann auch Null für einen leeren Baum ausgegeben werden
*/
private Baumknoten entfernen(Baumknoten teilbaum, Baumknoten s) {
System.out.println("Implementieren Sie die Methode Binaerbaum:entfernen()");
return teilbaum;
}
/**
* Berechnung der Hoehe des Baums
* @return Hoehe des Baums
*/
public int hoehe() {
if (wurzelKnoten == null) return 0;
else return wurzelKnoten.hoehe();
}
/**
* Rückgabe des Namens
* @return
*/
public String algorithmus() {return "Binaerbaum";}
public void druckenBaum() {
System.out.println("Tiefe:" + hoehe());
if (wurzelKnoten != null) wurzelKnoten.druckeUnterbaum(0);
System.out.println("A-----------A");
}
}
Klasse s2.baum.BaumGUI
package s2.baum;
import java.awt.BorderLayout;
import java.awt.Container;
import java.awt.GridLayout;
import java.awt.event.ActionEvent;
import java.awt.event.ActionListener;
import javax.swing.JButton;
import javax.swing.JFrame;
import javax.swing.JLabel;
import javax.swing.JMenu;
import javax.swing.JMenuBar;
import javax.swing.JMenuItem;
import javax.swing.JPanel;
import javax.swing.JTextField;
/**
*
* @author s@scalingbits.com
*/
public class BaumGUI implements ActionListener {
final private JFrame hf;
final private JButton einfButton;
final private JButton entfButton;
final private JTextField eingabeText;
final private JMenuBar jmb;
final private JMenu jm;
final private JMenuItem exitItem;
final private BaumPanel myBaum;
final private Binaerbaum b;
public BaumGUI(Binaerbaum bb) {
b = bb;
JLabel logo;
//ButtonGroup buttonGroup1;
JPanel buttonPanel;
// Erzeugen einer neuen Instanz eines Swingfensters
hf = new JFrame("BaumGUI");
// Gewünschte Größe setzen
// 1. Parameter: horizontale Größe in Pixel
// 2. Parameter: vertikale Größe
hf.setSize(220, 230);
// Beenden bei Schliesen des Fenster
hf.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
// Erzeugen der Buttons und Texteingabefeld
eingabeText = new JTextField("17");
einfButton = new JButton();
einfButton.setText("Einfügen");
entfButton = new JButton();
entfButton.setText("Entfernen");
// Registriere die eigene Instanz
// zum Reagieren auf eine Aktion der beiden Buttons
einfButton.addActionListener(this);
entfButton.addActionListener(this);
// Einfügen der drei Komponenten in ein Panel
// Das Gridlayout führt zum Strecken der drei Komponenten
buttonPanel = new JPanel(new GridLayout(1, 1));
buttonPanel.add(eingabeText);
buttonPanel.add(entfButton);
buttonPanel.add(einfButton);
// Erzeugen des Panels zum Malen des Baums
myBaum = new BaumPanel(b);
// setze Titel des Frame
hf.setTitle(b.algorithmus());
// Erzeuge ein Menueeintrag zum Beenden des Programms
jmb = new JMenuBar();
jm = new JMenu("Datei");
exitItem = new JMenuItem("Beenden");
exitItem.addActionListener(this);
jm.add(exitItem);
jmb.add(jm);
hf.setJMenuBar(jmb);
Container myPane = hf.getContentPane();
myPane.add(myBaum, BorderLayout.CENTER);
myPane.add(buttonPanel, BorderLayout.SOUTH);
hf.pack();
hf.setVisible(true);
hf.setAlwaysOnTop(true);
}
/**
* Diese Methode wird bei allen Aktionen der Menüleiste oder
* der Buttons aufgerufen
* @param e
*/
public void actionPerformed(ActionEvent e) {
Object source = e.getSource();
int wert = 0;
try {
if (source == entfButton) { //Entfernen aufgerufen
wert = Integer.parseInt(eingabeText.getText());
b.entfernen(new Baumknoten(wert));
myBaum.fehlerText("");
myBaum.repaint();
eingabeText.setText("");
}
if (source == einfButton) { // Einfügen aufgerufen
wert = Integer.parseInt(eingabeText.getText());
b.einfuegen(new Baumknoten(wert));
myBaum.fehlerText("");
myBaum.repaint();
eingabeText.setText("");
}
if (source == exitItem) { // Beenden aufgerufen
System.exit(0);
}
} catch (java.lang.NumberFormatException ex) {
// Fehlerbehandlung bei fehlerhafter Eingabe
myBaum.fehlerText("Eingabe '" + eingabeText.getText() + "' ist keine Ganzzahl");
myBaum.repaint();
eingabeText.setText("");
}
}
public static void main(String[] args) {
BaumGUI sg = new BaumGUI(new Binaerbaum());
if ((args.length > 0) && (args[0].equalsIgnoreCase("magic"))) {
sg.magicMode(15);
}
}
public void magicMode(int anzahl) {
Baumknoten[] gz = new Baumknoten[anzahl];
for (int i = 0; i < gz.length; i++) {
gz[i] = new Baumknoten(0);
gz[i].generiereZufallswert();
}
try {
for (int i = gz.length - 1; i >= 0; i--) {
eingabeText.setText(gz[i].toString());
b.einfuegen(gz[i]);
Thread.sleep(800);
myBaum.repaint();
}
for (int i = 0; i < gz.length; i++) {
eingabeText.setText(gz[i].toString());
b.entfernen(gz[i]);
Thread.sleep(800);
myBaum.repaint();
}
} catch (InterruptedException e) {
}
}
}
Klasse s2.baum.BaumPanel
package s2.baum;
import java.awt.Color;
import java.awt.Dimension;
import java.awt.Graphics;
import javax.swing.JPanel;
/**
*
* @author s@scalingbits.com
*/
public class BaumPanel extends JPanel{
final private Binaerbaum b;
final private int ziffernBreite = 10 ; // Breite einer Ziffer in Pixel
final private int ziffernHoehe = 20; // Hoehe einer Ziffer in Pixel
private String fehlerString;
public BaumPanel(Binaerbaum derBaum) {
fehlerString = "";
b = derBaum;
setPreferredSize(new Dimension(600,200));
setDoubleBuffered(true);
}
/**
* Setzen des Fehlertexts des Fehlertexts
* @param s String mit Fehlertext
*/
public void fehlerText(String s) {fehlerString = s;}
/**
* Methode die das Panel überlädt mit der Implementierung
* der Baumgraphik
* @param g
*/
public void paintComponent(Graphics g) {
super.paintComponent(g);
int maxWidth = getWidth();
int maxHeight = getHeight();
Baumknoten k = b.getWurzelknoten();
if (k != null) { // Male Wurzelknoten falls existierend
g.setColor(Color.black);
g.drawString("Hoehe: " + b.hoehe(), 10, 20);
g.drawString(fehlerString, 10, 40);
paintKnoten(g,k,getWidth()/2, 20);
}
else {
g.setColor(Color.RED);
g.drawString("Der Baum ist leer. Bitte Wurzelknoten einfügen.",10,20);
}
}
/**
* Malen eines Knotens und seines Unterbaums
* @param g Graphicshandle
* @param k zu malender Knoten
* @param x X Koordinate des Knotens
* @param y Y Koordinate des Knotens
*/
public void paintKnoten(Graphics g,Baumknoten k, int x, int y) {
int xOffset = 1; // offset Box zu Text
int yOffset = 7; // offset Box zu Text
String wertString = k.toString(); // Wert als Text
int breite = wertString.length() * ziffernBreite;
int xNextNodeOffset = ((int)java.lang.Math.pow(2,k.hoehe()-1))*10;
int yNextNodeOffset = ziffernHoehe*6/5; // Vertikaler Offset zur naechsten Kn.ebene
if (k.getLinkerK() != null) {
// Male linken Unterbaum
g.setColor(Color.black); // Schriftfarbe
g.drawLine(x, y, x-xNextNodeOffset, y+yNextNodeOffset);
paintKnoten(g,k.getLinkerK(),x-xNextNodeOffset,y+yNextNodeOffset);
}
if (k.getRechterK() != null) {
// Male rechten Unterbaum
g.setColor(Color.black); // Schriftfarbe
g.drawLine(x, y, x+xNextNodeOffset, y+yNextNodeOffset);
paintKnoten(g,k.getRechterK(),x+xNextNodeOffset,y+yNextNodeOffset );
}
// Unterbäume sind gemalt. Male Knoten
g.setColor(Color.LIGHT_GRAY); // Farbe des Rechtecks im Hintergrund
g.fillRoundRect(x-xOffset, y-yOffset, breite, ziffernHoehe, 3, 3);
g.setColor(Color.black); // Schriftfarbe
g.drawString(wertString, x+xOffset, y+yOffset);
}
}
Baumschule...
Fragen zu Binärbäumen
Welche der beiden Bäume sind korrekte, streng sortierte Binärbäume?
Welche sind keine streng sortierten Binärbäume und warum?
Streng sortierter Binärbaum 1
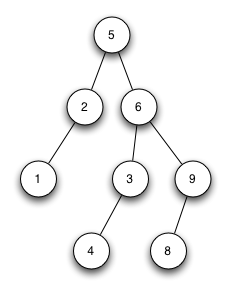
Streng sortierter Binärbaum 2
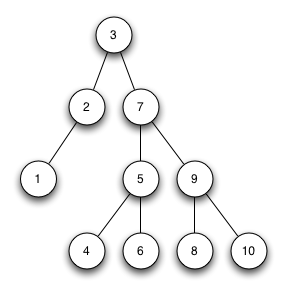
AVL Bäume
Welche der beiden AVL-Bäume sind korrekte AVL-Bäume?
Welche Bäume sind keine korrekten AVL Bäume und warum?
AVL-Baum 1
AVL Baum 2
Bruder-Baum
Welche der beiden Bäume sind keine korrekten Bruder-Bäume?
Warum sind sie keine Bruderbäume?
Bruder-Baum 1
Bruder-Baum 2
Bruder-Baum 3
- 12901 views
Lösungen (Bäume)
Lösungen (Bäume)Balancierte und unbalancierte Bäume
Balancierter Baum
Eingabe: 8, 4, 12, 2, 6, 10, 14, 1, 3, 5, 7, 9, 11, 13, 15
Es sind auch andere Lösungen möglich.
Degenerierte Baum
Eingabemöglichkeiten
- 5, 4, 3, 2, 1
- 1, 2, 3, 4, 5
Sortierte Folgen, gleich ob sie fallend oder steigend sortiert sind, führen bei einfachen binären Bäumen zu degenerierten Bäumen mit großer Höhe.
Implementierung eines Binärbaums
Klasse s2.baum.Baumknoten
Informelle Beschreibung der Algorithmen
Höhe eines Baums
- Bestimme Höhe des linken Unterbaums
- Gibt es einen linkenUnterbaum?
- Nein: Höhe links =0
- Ja: Höhe links= Höhe linker Unterbaum
- Gibt es einen linkenUnterbaum?
- Bestimme Höhe des rechten Unterbaum
- Gibt es einen rechten Unterbaum?
- Nein: Höhe rechts = 0
- Ja: Höhe rechts = Höhe rechter Unterbaum
- Gibt es einen rechten Unterbaum?
- Bestimme den höchsten der beiden Unterbäume
- Höhe des Baumes= 1 + Höhe höchster Unterbaum
Quellcode
package s2.baum;
/**
*
* @author s@scalingbits.com
*/
public class Baumknoten {
private int wert;
//private final int maxWert= Integer.MAX_VALUE;
private final int maxWert= 99;
public int getWert() {
return wert;
}
public void setWert(int wert) {
this.wert = wert;
}
/**
* Verwalte linken Knoten
*/
private Baumknoten l;
/**
* verwalte rechten Knoten
*/
private Baumknoten r;
public Baumknoten(int i) {wert=i;}
/**
* Liefere linken Knoten zurück
* @return linker Knoten
*/
public Baumknoten getLinkerK() {
return l;
}
/**
* Setze linken Knoten
* @param k Referenz auf linken Knoten
*/
public void setLinkerK(Baumknoten k) {
l = k;
}
/**
* Liefere rechten Knoten zurück
* @return rechter Knoten
*/
public Baumknoten getRechterK() {
return r;
}
/**
* Setze rechten Knoten
* @param k rechter Knoten
*/
public void setRechterK(Baumknoten k) {
r = k;
}
/**
* Drucken einen Unterbaum und rücke entsprechend bei Unterbäumen ein
* @param einruecken
*/
public void druckeUnterbaum(int einruecken) {
if (l != null) {
l.druckeUnterbaum(einruecken + 1);
}
for (int i = 0; i < einruecken; i++) {
System.out.print(".");
}
System.out.println(toString());
if (r != null) {
r.druckeUnterbaum(einruecken + 1);
}
}
/**
* Berechne Höhe des Baums durch rekursive Tiefensuche
* @return
*/
public int hoehe() {
int lmax = 1;
int rmax = 1;
int max = 0;
if (l != null) lmax = 1 + l.hoehe();
if (r != null) rmax = 1 + r.hoehe();
if (rmax > lmax) return rmax;
else return lmax;
}
/**
* Generiere eine Zufallsbelegung für den gegebenen Knoten
* Die Funktion darf nicht mehr nach EInfügen in den Baum
* aufgerufen werden, da der neue Wert zu einer inkorrekten Ordnung führt
*/
public void generiereZufallswert() {
wert= (int)(Math.random()*(double)maxWert);
}
/**
* Erlaubt den Zahlenwert als Text auszudrucken
* @return
*/
public String toString() { return Integer.toString(wert);}
}Klasse s2.baum.Binaerbaum
Informelle Beschreibung der Algorithmen
Einfügen von Knoten
- Ist der Wert des neuen Knoten gleich der Wurzel meines Baums?
- Ja: Fertig. Es wird nichts eingefügt
- Nein:
- Ist der Wert kleiner als mein Wurzelknoten?
- Ja: Der neue Knoten muss links eingefügt werden
- Gibt es einen linken Knoten?
- Nein: Füge Knoten als linken Knoten ein
- Ja: Rufe Einfügemethode rejursiv auf...
- Gibt es einen linken Knoten?
- Nein: Der neue Knoten muss rechts eingefügt werden
- Gibt es einen rechten Knoten?
- Nein: Füge Knoten als rechten Knoten ein
- Ja: Rufe Einfügemethode rekursiv auf...
- Gibt es einen rechten Knoten?
- Ja: Der neue Knoten muss links eingefügt werden
- Ist der Wert kleiner als mein Wurzelknoten?
Quellcode
package s2.baum;
/**
*
* @author s@scalingbits.com
*/
public class BinaerbaumLoesung {
private Baumknoten wurzelKnoten;
public Baumknoten getWurzelknoten() {return wurzelKnoten;}
/**
* Füge einen neuen Baumknoten in einen Baum ein
* @param s
*/
public void einfuegen(Baumknoten s) {
if (wurzelKnoten == null) {
// Der Baum ist leer. Füge Wurzelknoten ein.
wurzelKnoten = s;
}
else // Der Baum ist nicht leer. Normales Vorgehen
einfuegen(wurzelKnoten,s);
}
/**
* Füge einen gegebenen Knoten s in einen Teilbaum ein.
* Diese Methode ist eine rekursive private Methode
* Da der neue Knoten die Wurzel des neuen Teilbaums bilden kann,
* wird eventuell ein Zeiger auf einen neuen Teilbaum zurückgeliefert
* Randbedingung:
* * Es wird kein Knoten mit einem Wert eingefügt der schon existiertz
* @param teilbaum
* @param s
*/
private void einfuegen(Baumknoten teilbaum, Baumknoten s) {
if (!(s.getWert()==teilbaum.getWert())) {
// Nicht einfuegen wenn Knoten den gleichen Wert hat
if (s.getWert()<teilbaum.getWert()) {
// Im linken Teilbaum einfuegen
if (teilbaum.getLinkerK() != null)
einfuegen(teilbaum.getLinkerK(),s);
else teilbaum.setLinkerK(s);
}
else // Im rechten Teilbaum einfuegen
if (teilbaum.getRechterK() != null)
einfuegen(teilbaum.getRechterK(),s);
else teilbaum.setRechterK(s);
}
}
/**
* Öffentliche Methoden zum Entfernen eines Baumknotens
* @param s
*/
public void entfernen(Baumknoten s) {
wurzelKnoten = entfernen(wurzelKnoten,s);}
/**
* Private, rekursive Methode zum Entfernen eines Knotens aus einem
* Teilbaum. Es kann ein neuer Teilbaum enstehen wennn der Wurzelknoten
* selbst entfernt werden muss. Der neue Teilbaum wird daher wieder mit
* ausgegeben
* @param teilbaum Teilbaum aus dem ein Knoten entfernt werden soll
* @param s der zu entfernende Knoten
* @return Der verbleibende Restbaum. Es kann auch Null für einen leeren Baum ausgegeben werden
*/
private Baumknoten entfernen(Baumknoten teilbaum, Baumknoten s) {
Baumknoten result = teilbaum;
if (teilbaum != null) {
if (teilbaum.getWert()==s.getWert()) {
// der aktuelle Knoten muss entfernt werden
Baumknoten altRechts = teilbaum.getRechterK();
Baumknoten altLinks = teilbaum.getLinkerK();
if (altRechts != null) {
result = altRechts;
if (altLinks != null) einfuegen(result, altLinks);
}
else
if (altLinks!=null) result = altLinks;
else result = null;
}
else if (teilbaum.getWert()<s.getWert()) {
Baumknoten k = teilbaum.getRechterK();
teilbaum.setRechterK(entfernen(k,s));
}
else {
Baumknoten k = teilbaum.getLinkerK();
teilbaum.setLinkerK(entfernen(k,s));
}
}
return result;
}
/**
* Berechnung der Hoehe des Baums
* @return Hoehe des Baums
*/
public int hoehe() {
if (wurzelKnoten == null) return 0;
else return wurzelKnoten.hoehe();
}
/**
* Rückgabe des Namens
* @return
*/
public String algorithmus() {return "Binaerbaum";}public void druckenBaum() {
System.out.println("Tiefe:" + hoehe());
if (wurzelKnoten != null) wurzelKnoten.druckeUnterbaum(0);
System.out.println("A-----------A");
}
}
Baumschule...
Fragen zu Binärbäumen
Welche der beiden Bäume sind korrekte, streng sortierte Binärbäume?
Welche sind keine streng sortierten Binärbäume und warum?
Streng sortierter Binärbaum 1
Der Baum ist kein streng sortierter Binärbaum. Knoten 3 müsste rechter Sohn von Knoten 2 sein. Knoten 4 müsste rechter Sohn von Knoten 3 sein.
Streng sortierter Binärbaum 2
Der Baum ist ein streng sortierter Binärbaum.
AVL Bäume
Welche der beiden AVL-Bäume sind korrekte AVL-Bäume?
Welche Bäume sind keine korrekten AVL Bäume und warum?
AVL-Baum 1
Der Baum ist ein AVL-Baum. Alle Blätter sind auf nur zwei unterschiedlichen Ebenen angeordnet.
AVL Baum 2
Der Baum ist kein AVL Baum. Das Fehlen eines zweiten Sohns von Knoten B führt zu einem Unterschied von zwei Ebenen im Baum.
Bruder-Baum
Welche der beiden Bäume sind keine korrekten Bruder-Bäume?
Warum sind sie keine Bruderbäume?
Bruder-Baum 1
Der Baum ist ein Bruder-Baum. Alle Blätter sind auf der untersten Ebene. Der einzige unäre Knoten B hat einen binären Bruderknoten.
Bruder-Baum 2
Der Baum ist kein Bruder-Baum. Der Blattknoten E ist nicht auf der untersten Ebene.
Bruder-Baum 3
Der Baum ist kein Bruder-Baum. Knoten B und C sind unäre Brüder. Einer von ihnen müsste binär sein.
Knoten B und C sind überflüssig. Nach ihrem Entfernen entsteht wieder ein Bruder-Baum.
- 11065 views
Lernziele (Datenstrukturen)
Lernziele (Datenstrukturen)|
|
Am Ende dieses Blocks können Sie:
|
Lernzielkontrolle
Sie sind in der Lage die folgenden Fragen zu beantworten: Fragen zu Datenstrukturen
Feedback
- 3885 views
Programmierprojekt: Ariadnefaden
Programmierprojekt: AriadnefadenIm Projekt Ariadnefaden wird eine graphische Anwendung entwickelt mit der man Labyrinthe entwickeln kann um sich dann den besten Pfaden suchen lässt.
|
Das Projekt wird in mehreren Stufen entwickelt:
|
Ein Beispiel eines Labyrinths:
|
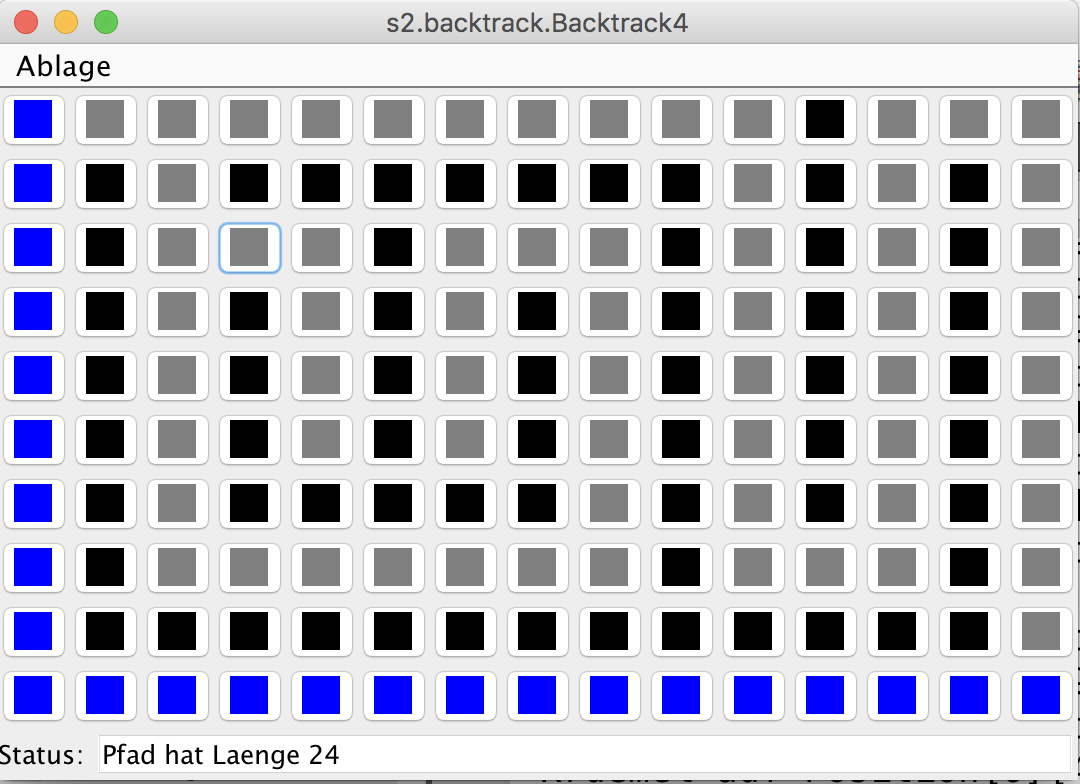
Die Quellen können aus dem github Projekt scalingbits/dhbwjava aus dem Paket s2.backtrack heruntergeladen werden.
- 1250 views
Stufe 1: Swing
Stufe 1: Swing
|
Die Klasse Zelle ist ein JButton der abhängig vom Zustand einer Position eine bestimmte Farbe annimmt. In der main() Methode werden die verschiedenen Menüpunkte implementiert um den JButton zu testen. Rechts ist ein Beispiel zu sehen. Jede Zelle hat einen Zeiger auf eine Position. In der Klasse Zeiger werden alle graphischen Aspekte implementiert. In der Klasse Position wird die Logik zum Darstellen einer Position implementiert. Die Zellen werden in der nächsten Stufe zu einem Feld zusammengefaßt aus dem ein Labyrinth gebaut wird. Die Klasse Position hat hierzu eine x und y Koordinate da sie später in einem Feld zu Lösen des Labyrinths verwendet wird. Implementieren Sie die Klassen im Paket s2.backtrack. |
 |

Quellcode der Klasse Zelle
package s2.backtrack;
import java.awt.Color;
import java.awt.Graphics2D;
import java.awt.event.ActionEvent;
import java.awt.event.ActionListener;
import java.awt.image.BufferedImage;
import javax.swing.Icon;
import javax.swing.ImageIcon;
import javax.swing.JButton;
import javax.swing.JCheckBoxMenuItem;
import javax.swing.JFrame;
import javax.swing.JMenu;
import javax.swing.JMenuBar;
import javax.swing.JMenuItem;
/**
*
* @author s@scalingbits.com
* @version 1.0
*/
public class Zelle extends JButton{
/**
* Die Zelle ist im Editiermodus und erlaubt Änderungen zwischen
* Wand und Leer.
* Alle Objekte teilen sich diese Eigenschaft
*/
public static boolean editierbar = false;
public static Position start;
public static Position ziel;
/**
* Die x,y Position
*/
public Position p;
public static Icon leerIcon;
public static Icon wandIcon;
public static Icon kruemelIcon;
public static Icon startIcon;
public static Icon zielIcon;
public static Icon loesungIcon;
public static int xRaster=20;
public static int yRaster=20;
/**
*
* @param pp eine Position im Feld
*/
public Zelle (Position pp) {
// Hier kodieren
}
/**
* Update des graphischen Objekts falls sich die Position verändert hat
* Es wird die Farbe und der Tooltip neu gesetzt
*/
public void update() {
// Hier kodieren
}
/**
* Erzeugt eine Ikone in der richtigen Größe und Farbe
* @param farbe Farbe der Ikone
* @return die erzeugte Ikone
*/
public static ImageIcon erzeugeIcon(Color farbe) {
BufferedImage img =
new BufferedImage(xRaster, yRaster, BufferedImage.TYPE_4BYTE_ABGR);
Graphics2D g = img.createGraphics();
g.setColor(farbe);
g.fillRect(0, 0, xRaster-1, yRaster-1);
g.dispose();
return new ImageIcon(img);
}
/**
* Erzeugt ein Fenster mit einem einzelnen Button zum Testen der Funktionen
* dieser Klasse
* @param args Eingabeparameter werden nicht gelesen
*/
public static void main(String[] args) {
// Implementieren Sie alles was zum testen des JButtons benötigt wird.
} // Ende Methode main
} // Ende Klasse ZelleMusterlösung
Github Projekt scalingbits/dhbwjava
- Klasse Position.java
- Klasse Zelle.java
|
Hilfe! Wie packe ich das an? |
Hier ein paar Tips wie man dieses Problem in kleineren Schritten lösen kann...
Wichtig: Immer ein lauffähiges Programm behalten!
- Erzeugen Sie die Klasse Zelle als Spezialierung von JButton. Sie wird sich erstmal wie ein normaler JButton verhalten...
- Schreiben Sie ein Hauptprogramm (main() Routine):
- Legen Sie ein JFrame an
- Erzeugen Sie ein Objekt vom Typ Zelle. Geben Sie dem Button einen Namen
- Fügen Sie den Button zum JFrame hinzu
- Fügen Sie notwendigen Code zum JFrame hinzu (Größe, Schließen beim Verlassen etc.)
- Testen Sie alles. Ein Fenster mit einem JButton erscheint
- Fügen Sie ein Menü mit einer Leiste hinzu
- Aktionen benötigen Sie erstmal keine
- Testen Sie alles
- Die update() Methode
- Sie wird verwendet wenn sich der Zustand einer Position ändert. Die Zelle muß dann eine neue Graphik anzeigen
- Man liest den Zustand aus und nutzt setIcon() um neue Ikone mit anderer Farbe anzulegen
- Ein neuer Tooltip ist dann auch nötig (Methode setToolTipText() )
- Die Methode update() kann man natürlich auch im Konstruktor verwenden. Hier muß die Farbe auch gesetzt werden.
- Konstruktor für Zelle:
- Setzen Sie den Namen des JButtons im Konstruktor des JButtons (-> super )
- Erzeugen Sie einen Konstruktor ohne Parameter
- Passen Sie den Aufruf im Hauptprogramm an.
- Testen Sie alles
- Umbauen von einem JButton mit Text zu einem JButton mit Farbe
- Legen Sie die Konstanten für die Größe der Ikone an (x,y und bitte static, sie gilt für alle Buttons)
- Legen Sie einen Zeiger auf eine Ikone Ihrer Wahl an (z.Bsp. Start = rot). Sie ist statisch und final, Eine Methode zum Erzeugen von Ikonen ist vorgegeben.
- Kopieren Sie sich die Methode zum Erzeugen von Ikonen in die Klasse
- Erweitern Sie den Konstruktor
- Erzeugen Sie eine rote Ikone wenn nötig (Factory-pattern! Suchen Sie auf dem Webserver nach Factory wenn notwendig )
- Löschen Sie den super Aufruf mit Namen
- Setzen Sie die Ikone (Das findet man mit Google "java API 11 JButton)
- Testen Sie Ihren roten Button
- Bunte Buttons Infrastruktur:
- Wiederholen Sie alles was Sie für rote Ikonen gemacht haben für die anderen Farben ...
- Sie benötigen Farben für: Start, Ziel, Leere Kachel, Wand, Krümmel, Lösung)
- Macht man am besten in der Methode update()
- Testen: Codieren Sie eine andere Farbe für Ihren Button in dem Sie der Position einen anderen Status geben
- Wiederholen Sie alles was Sie für rote Ikonen gemacht haben für die anderen Farben ...
- Vorbereiten des Farbenwechseln beim Klicken
- Schreiben Sie einen Actionlister für einen Buttonklick
- Am besten im Konstruktor implementieren . Jeder Button soll automatisch einen besitzen.
- Schreiben Sie beim Buttonclick etwas auf die Konsole
- Testen des Buttonclicks!
- Nicht vergessen: Löschen Sie die Konsolenausgabe wieder
- Implementieren Sie Klasse Position
- Minimalanforderungen:
- x,y Attribut und Farbe (entweder enum oder Konstante für jede Farbe)
- Konstruktor
- Der Rest der Klasse ist mechanisch. Sie machen das jetzt oder wenn Sie es später benötigen...
- Minimalanforderungen:
- Ändern des Konstruktors der Klasse Zelle
- Akzeptieren Sie eine Position
- Merken Sie sich die Position...
- Passen Sie das Hauptprogramm an
- Erzeugen Sie zuerst eine Position
- und dann einen JButton mit Ihr
- Testen Sie alles (keine optische Verbesserung)
- Implementieren Sie einen "Tooltip"
- Im Konstruktor von Zelle
- Lesen Sie die x,y Koordinate und den Zustand aus
- am besten jetzt eine Methode toString() in Position implementieren und verwenden
- Testen Sie Ihre Anwendung mit dem Tooltip
- Farbwechsel des Buttons
- Verbessern Sie den ActionListener Ihres JButton (er ist irgendwo im Konstruktor...)
- Lesen Sie den Zustand ihrer "Position" aus und wechseln Sie ihn (setIcon() )
- Testen Sie Ihren JButton
- Implementieren Sie die Tests der anderen Farben und den Editierschutz
- Verwenden Sie die Klasse JCheckBoxMenuItem im Menü.
- Verwenden Sie eine statische Variable für den Editierschutz. Man soll entweder alle Felder editieren können oder keines.
- Sie benötigen ActionListener die auf die anderen Farben wechseln...
- Sie benötigen einen ActionListener der die Editierbarkeit checkt und die statische Variable wechselt
- Blocken Sie die Editierbarkeit im ActionListener der die Farbe von leer auf Wand wechselt...
- Testen Sie alles!
- 1309 views
Stufe 2: Swing mit Layout Manager
Stufe 2: Swing mit Layout ManagerIn der zweiten Phase werden viele Zellen mit JButtons zu einem Feld zusammengefaßt.
LayoutNutzen Sie einen Layoutmanager mit dem Sie Oben das Feld darstellen können und unten die Statusinformationen. Was bietet sich hier an? Welcher Layoutmanager bietet sich für das Feld an? Unten sollen Sie zwei Komponenten implementieren, einen Text und einen variablen Text. Welcher Layoutmanager bietet sich hier an? KomponentenWelche Komponenten benötigen Sie? Pull-down MenüImplementieren Sie das Pull-down Menü. Das Feld soll editierbar sein oder schreibgeschützt. Welche Komponente bietet sich hier an? Implementieren Sie eine Textausgabe für Weg finden, Oeffnen, Speichern. Diese Funktionen werden in späteren Phasen implementiert. Implementieren Sie Editieren, Loeschen, Beenden. |
GUI mit ausgeklapptem Menü
|
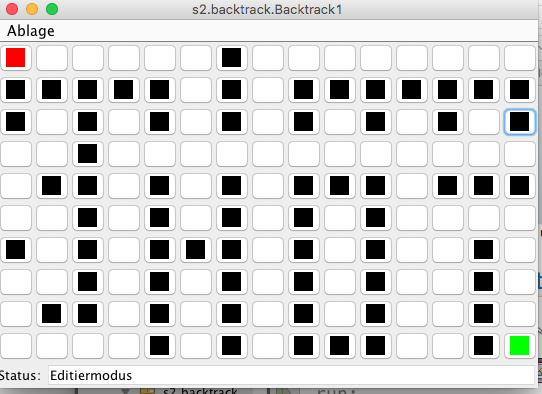
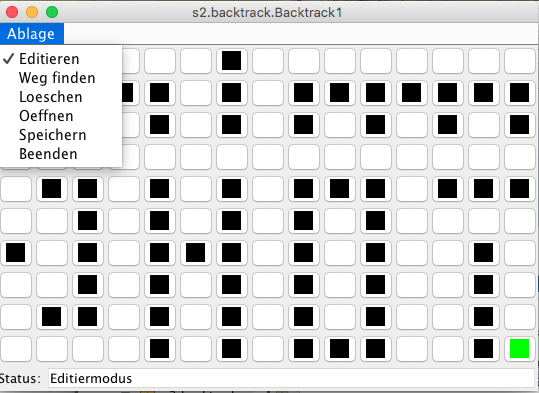
Klasse Backtrack
Zur Klasse Backtrack gibt es einige Entwurfsüberlegungen. Die Klasse soll in den nächsten Stufen in der Lage sein das Laden und Speichern von Dateien zu unterstützen. Sie soll es auch erlauben, dass die Suchalgorithmen eingebunden werden.
Dies kann man erreichen in dem man alle Aktionen des Pull-Down Menüs als eigene Methoden implementiert. Jede zukünftige Phase wird aus dieser Klasse spezialisert. Durch überschreiben der Methoden kann man in zukünftigen Phasen die Aktionen ändern, ohne das man die alte Implementierung ändern muss.
Die Methoden für spätere Phasen machen nur ein Update im Textfeld. So kann man sehen, dass sie aufgerufen werden.
Dadurch kann man auf den Code der vorhergehenden Klasse zurückgreifen und muss den Code nicht replizieren.
Hierzu muss man das GUI in einer Instanz von Backtrack implementieren. Das GUI der vorhergehenden Phase wurde als statische Methode in Zelle implementiert. Dies ist hier nicht geschickt.
Um das Editieren zur ermöglichlichen muß der Benutzer einen aus mehreren Zuständen auswählen. Dies kann man mit der Klasse javax.swing.JCheckBoxMenuItem erreichen.
Klasse Labyrinth
Die Klasse Labyrinth dient zum Darstellen und Speichern des Labyrinths. Sie enthält keine Aspekte der Benutzeroberfläche. Das Labyrinth wird von Backtrack benutzt um die entsprechenden graphischen Elemente korrekt anzuzeigen.
Da das GUI immer etwas sinnvolles anzeigen soll, wird ein Labyrinth nach dem Laden immer in das Labyrinth umkopiert welches zur Anzeige benutzt wird. Jeder JButton (Zelle) hat einen Zeiger auf eine Position. Würde man den neuen Zustand nicht in ein Objekt der Klasse Position umkopieren müsste man alle Zeiger der Zellenobjekte auf die neuen Objekte des Labyrinths ändern.
Die Klasse Labyrinth hat deshalb zwei Konstruktoren
- einen Copy-Konstruktor: ein existierendes Feld wird als Vorlage verwendet.
- einen Konstruktor mit den Dimensionen und der Start und Ziel-Position: Ein Ausgangszustand
- Hier ist es wichtig die Koordinaten der Start- und Ziel Objekte zu nutzen und die dazu passenden Objekte im Feld zu identifizieren.
Die Methode update() kopiert ein existierendes Labyrinth in ein anderes um.
getPos(x,y) ist eine Bequemlichkeitsmethode die in den späteren Phasen beim Suchen helfen wird.
UML
|
|
Die Klasse Labyrinth wird alle Information enthalten die gespeichert werden:
Die Klasse Labyrinth enthält Zeiger auf den Start und das Ziel des Labyrinths. Diese beiden Objekte müssen Teile des Feldes sein welches angezeigt wird! Die Klassen die zum GUI gehören sind:
sie werden nicht gespeichert. |

Speicherstruktur
|
Im Speicher gibt es Objekte die mit der Hilfe von Swing das GUI repräsentieren. Das ist eine Instanz von Ariadne und das Feld der Buttons vom Typ Zelle. Der Zustand der Zellen holen sich die graphischen Objekt aus der Instanz des Labyrinths und dem Feld der Positionen. Später wird der nicht grafische Zustand vom Backtrackingalgorithmus und von den Methoden zum Speichern und Laden verwendet. Die Idee, hier ist, mir Hilfe einer Kopiermethode und eines Copykonstruktors jeweils eine Kopie anzulegen die dann für den entsprechenden Zweck verwendet wird. Die Objekte die den Status des GUI repräsentieren sind getrennt vom GUI. |
|
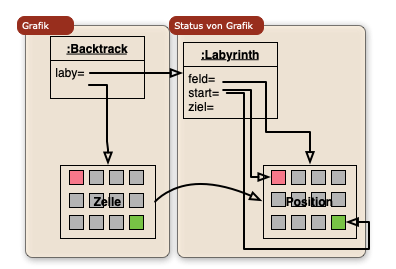
{kind=link}
Musterlösung
Github Projekt scalingbits/dhbwjava
- Klasse Position.java
- Klasse Zelle.java
- Klasse Labyrinth.java
- Klasse Backtrack.java
|
Hilfe! Wie packe ich das an? |
Hier ein paar Tips wie man dieses Problem in kleineren Schritten lösen kann...
Wichtig: Immer ein lauffähiges Programm behalten!
- Implementieren Sie die Klasse Labyrinth
- Erzeugen Sie im Konstruktor ein zweidimensionales Feld von Position
- Der graphische Teil der Anwendung soll auf eigenen Datenstrukturen arbeiten. Deshalb benötigen Sie
- Eine Updatemethode: Der Zustand einer Vorlage wird in in ein Labyrinth kopiert
- Einen Copy-Konstruktur
- Die Klasse Position sollte eine ähnliche Infrastruktur haben
- Start und Ziel: Können theoretisch aus Objekten bestehen, die nicht zum aktuellen Labyrinth gehören (Gefahr von Inkonsistenzen!)
- Lesen Sie das Start- und Ziel-objekt im Konstruktor nur
- Ziegen Sie mit Ihren internen Zeigern auf die äquivalenten Objekte im Labyrinth.
- Setzen Sie deren Zustand.
- Equals- und Update-Methoden in Position sind hier sehr nützlich
- Lesen Sie das Start- und Ziel-objekt im Konstruktor nur
- Setzen Sie beim Anlegen des Feldes alle Positionen auf eine leere Position (ausgenommen Start und Ziel)
- Testen ist schwierig: Mut zur Lücke...
- Design Ihres GUIs (Klasse Backtrack)
- Bauen Sie Ihr GUI im Konstruktor der Klasse
- Legen Sie ein JFrame an
- Beenden Sie die Anwendung beim Schliessen des Fenster
- Nutzen Sie ein Borderlayout als Hauptstruktur
- Im Süden implementieren Sie ein JPanel mit z.Bsp. ein Flowlayout
- Ein JLabel links
- Ein JTextField rechts
- Nur lesbar
- Merken Sie sich den Zeiger auf das Textfeld als Attribut in Ihrer Hauptklasse.
- ActionListener in inneren Klassen müssen hier den Zustand dokumentieren
- Im Zentrum wird ein neues JPanel mit Gridlayout angelegt
- Die Dimension muss zum Labyrinth passen
- Legen Sie ein Labyrinth an.
- Legen Sie zu jedem Feld im Labyrinth eine Zelle an und stecken Sie die Zellen in das JPanel mit Gridlayout
- Speichern Sie sich einen Zeiger auf das Anzeigelabyrinth in einem Attribut der äusseren Klasse
- Im Süden implementieren Sie ein JPanel mit z.Bsp. ein Flowlayout
- Implementieren Sie das Hauptprogramm
- Legen Sie ein Objekt Ihrer Klasse an
- Implementieren und benutzen Sie eine Methode anzeigen()
- Die Methode "packt" das JFrame und zeigt es an
- Man muss später Spezialisierungen der Klasse mit dem spezifisichen Konstruktor in zukünftigen main() Methoden erzeugen. Dies Methode kann man dann wiederverwenden...
- Testen Sie alles!
- Implementieren Sie das Menü mit allen Einträgen. Diese Klasse wir noch spezialisiert. Esa erspart später Schreibarbeit
- Schreiben Sie hierfür eine eigene Methode
- Rufen Sie die Methode aus dem Hauptprgramm auf
- Behandlung der Aktionen (siehe Screenshot)
- Viele Behandlungen werden erst später benötigt. Implementieren nur eine Kontrollausgabe auf der Konsole
- Vorgehen:
- Die Klasse Backtrack wird in späteren Phasen spezialisiert
- Schreiben Sie für jede Aktion eine Methode die einen Zeiger auf die graphische Komponente entgegen nimmt.
- Diese Methoden werden später überschrieben!
- In der Methode wird ein ActionListener angelegt und registriert
- Jetzt zu implementierende Behandlungen
- Beenden der Anwendung
- Schützen der Anwendung vor Editierversuchen
- Löschen des Labyrinths
- Testen, testen, testen
- Feiern: Sie haben die nächste Stufe geschafft.
- 1187 views
Stufe 3: Laden und Speichern von Labyrinthen
Stufe 3: Laden und Speichern von LabyrinthenKlasse BacktrackIO
Diese Klasse wird aus Backtrack spezialisiert. Sie nutzt die gesamte Infrastruktur. Sie überschreibt
- speichernLabyrinth()
- ladenLabryrinth()
- main(String[] args): Sie müssen hier eine Instanz von BacktrackIO anlegen und anzeigen
Da man hier mit Verzeichnissen im Dateiverwaltungssystem arbeiten muss, sollte man die folgenden GUI Klassen verwenden:
Man kann Sie wie folgt einsetzen um den Zugriff auf eine Datei zu bekommen:
File selectedFile;
JFileChooser jfc
= new JFileChooser(FileSystemView.getFileSystemView().getHomeDirectory());
int returnValue = jfc.showSaveDialog(null);
if (returnValue == JFileChooser.APPROVE_OPTION) {
selectedFile = jfc.getSelectedFile();
System.out.println(selectedFile.getAbsolutePath());
// Ab hier mit der Datei arbeiten...
}
| Damit erhalten Sie, abhängig von Ihrer Plattform, einen Auswahldialog im Home-Verzeichniss Ihres Benutzers. | 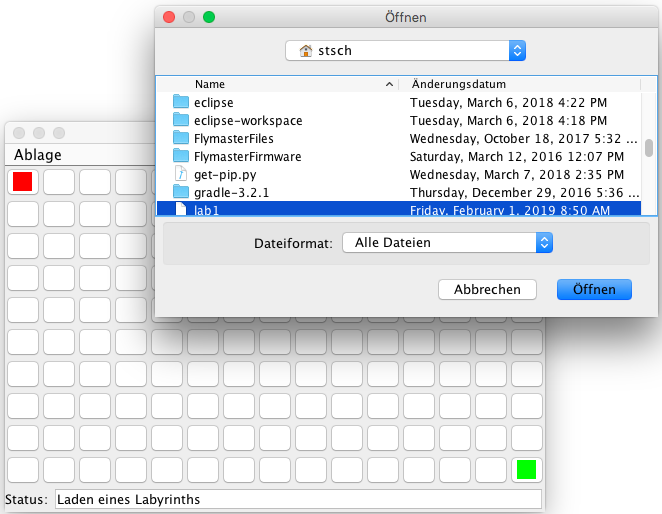 |
UML

Speicherstruktur
| Zum Speichern und Laden eines Labyrinths wird eine Kopie der Daten angelegt die zum visualieren angelegt werden. | 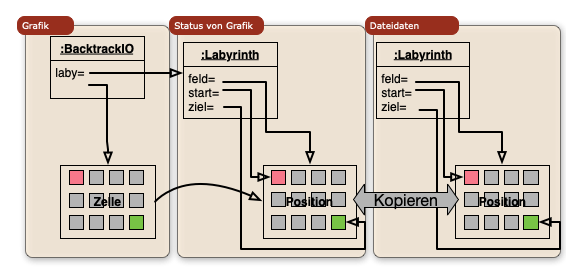 |
Musterlösung
Github Projekt scalingbits/dhbwjava
- Klasse Position.java
- Klasse Zelle.java
- Klasse Labyrinth.java
- Klasse Backtrack.java
- Klasse BacktrackIO.java
|
Hilfe! Wie packe ich das an? |
- Erzeugen Sie eine spezialisierte Klasse BacktrackIO
- Kopieren Sie sich das Hauptprogramm der Oberklasse
- Anpassung: Erzeugen Sie ein Objekt der aktuellen Klasse
- Testen: Läuft alles wie zuvor?
- Nutzen Sie die Serialisierung
- Die Klassen Labyrinth und Position müssen die entsprechende Schnittstelle implementieren
- Überschreiben Sie die Methode zum Speichern
- Nutzen Sie Klasse JFileChooser zum Selektieren der Datei
- Holen Sie sich von der Klasse JFileChooser das Ergebnis (Eine Instanz der Klasse File)
- Spicken Sie doch einfach (Im ersten Semester wurde bei den Schnittstellen ein sehr ähnliches Beispiel diskutiert)
- Schreiben Sie Labyrinth, Start und Ziel als Datei
- Verketten Sie FileOutputStream mit ObjectOutputStream
- Schreiben Sie Ihre GUI Datenstruktur des Layrinths in die Datei
- Behandeln Sie alle Ausnahmen wie benötigt...
- Testen: Wurde die Datei geschrieben?
- Vorbereiten zum Laden
- Schreiben Sie eine Methode die alle JButtons updated. Nach dem Laden müssen neue Zustände angezeigt werden
- Überschreiben Sie die Methode zum Laden
- Nutzen Sie den JFileChooser zur Identifikation der Datei
- Laden Sie die Datei. Sie haben nun einen Zeiger auf ein neues Labyrinth
- Machen Sie Ihr Labyrinth editierbar
- Nutzen Sie die Methode update() und Ihr GUI Labyrinth mit dem eingelesen Labyrinth zu überschreiben
- Machen Sie ein Update auf allen Zellen
- Testen
- 1239 views
Stufe 4: Suchen einer Lösung mit Backtracking
Stufe 4: Suchen einer Lösung mit BacktrackingKlasse BacktrackSuche
Diese Klasse wird aus BacktrackIO spezialiert. Sie nutzt die gesamte Infrastruktur. Sie überschreibt
- loesungFinden()
- main(String[] args): Sie müssen hier eine Instanz von BacktrackSuche anlegen und anzeigen
Klasse Ariadne
In dieser Klasse wird die Suche implementiert.
Zuschauen beim Suchen...
Implementieren Sie eine Wartebedingung, dann können Sie Ihrem Algorithmus zuschauen.
Definieren Sie eine Variable mit Millisekunden Schlafzeit
public static final int WARTEN=10; //ms Schlafen vor dem nächsten Schritt
Lassen Sie den aktuellen Thread schlafen
public static final int WARTEN=1000; // ms Schlafen vor dem nächsten Schritt
try {
Thread.sleep(WARTEN);
} catch (InterruptedException ex) {
System.out.println("Probleme mit Thread aufwachen");
}Das GUI muss jetzt noch wissen, dass sich etwas geändert hat. Deshalb benötigt man einen Zeiger auf das GUI. Das schafft eine Abhängigkeit vom GUI und ist nicht schön (muss aber sein).
Triggern Sie ein Update indem Sie das Labyrinth des GUIs erneuern und dann alle Buttons dazu zwingen den Zustand ihrer Zelle zu checken:
bt.laby.update(laby); bt.updateButtons();
Die rekursive Suche
Es gibt einen Einstieg in die Suche ohne Parameter mit der Methode suche(). Die rekursive Suche findet in einer überschriebenen Methode statt, die die Teilstrecke von einem Zwischenstart zu einem Zwischenziel sucht.
Alle Methoden arbeiten auf dem gleichen Labyrinth, dadurch kann man Stellen entdecken auf denen man schon mal war.
Eine separate Methode findeOptionen() checkt alle Nachbarpositionen und gibt eine Liste von Optionen zurück.
Optionen sind freie Felder. Keine Optionen sind die Wände und Felder die schon einmal betreten wurden.
UML

Musterlösung
Github Projekt scalingbits/dhbwjava
- Klasse Position.java
- Klasse Zelle.java
- Klasse Labyrinth.java
- Klasse Backtrack.java
- Klasse BacktrackIO.java
- Klasse BacktrackSuche.java
|
Hilfe! Wie packe ich das an?Grundlegende Überlegungen
|
- Erzeugen Sie eine spezialisierte Klasse BacktrackSuche aus der Klass BacktrackIO
- Kopieren Sie sich das Hauptprogramm der Oberklasse
- Anpassung: Erzeugen Sie ein Objekt der aktuellen Klasse
- Testen: Läuft alles wie zuvor?
- Überschreiben Sie die Methode loesungFinden()
- Implementieren Sie einen ActionListener der die Suche started
- Setzen Sie das Statusfeld. Das ist ein guter Test ob der Aktionlistener funktioniert.
- Starten Sie die Suche in einem eigenen Thread, dann kann das GUI parallel arbeiten und Sie können die Suche beobachten
- Implementieren Sie die Klasse Ariadne
- Sie können Sie auch Gretel nennen, Ariadne streut in meinem Beispiel Krümel...
- Variablen
- int zum Warten in Millisekunden, Ariadne düst sonst wie von der Hummel gestochen durch das Labyrinth und Sie können nicht sehen wie der Weg gefunden wird.
- Ein Zeiger auf ein Labyrinth: Die Klasse arbeitet rekursiv auf einem eigenen Labyrinth
- Ein Rückzeiger auf Backtrack: Hiermit können Sie das GUI nach jedem gestreuten Krümel um ein Update bitten. Dann können Sie Ariadne beim Krümelstreuen zuschauen. Das ist nicht elegant, weil damit Ariadne von dem GUI abhängt. Das ganze am besten protected, diese Klasse wird nochmals spezialisiert werden
- Einen Konstruktor
- Parameter: Das GUI (Javaklasse Backtrack) welches den Suchauftrag gibt. Man kann dann nach jedem Krümel ein Update machen und zuschauen
- Legen Sie sich ein neues Labyrinth an. Kopieren Sie sich das Labyrinth des GUIs!
- Hilfsmethode: findeOptionen() implementieren
- Geben Sie ein Set mit allen Optionen zurück.
- Testen Sie alle Punkte um den gegebenen Startpunkt. Vorsicht; Ihr Feld ist endlich, es kann Feldüberläufe geben.
- Tipp: Benutzen Sie die Methode Position.neuerWeg(), sie wird wahr wenn das entsprechende Feld keine Wand oder kein Krümel ist.
- Eine Methode suche()
- Diese Methode wird vom GUI aufgerufen
- Rückgabe: Eine Liste von Position mit dem Pfad zur Lösung
- Diese Methode nutzt den hardcodierten Start und Ziel des Labyrinths zum Aufruf der rekursiven Methode suche()
- Testen der Rekursion in Teilschrittem ist schwierig. Möglichkeiten sind:
- findeOptionen() mit Testfällen testen
- Abbruch der Rekursion testen: Start ist gleich Ziel
- Design der Rekursion...
- Diese Methode bekommt einen individuellen Start und ein individuelles Ziel. Diese Methode soll Teilaufgaben lösen!
- Streue erstmal einen Krümel. Gretel meint das ist immer eine gute Sache...
- Das ist die echte Arbeit zum Verkleinern unseres Problems bei der Rekursion
- Tue gutes und sprich darüber...
- Kopiere das Suchlabyrinth um in das GUI-Labyrinth (es hat jetzt einen neuen Krümel=
- Rufe in Backtrack die Methode updateButtons() auf
- So kann man sehen was gerade passiert
- Diese Methode ruft eine Methode findeOptionen() auf
- Diese Methode liefert eine Liste von Optionen
- Optionen sind freie Felder: keine Wand, kein Krümel
- Liegt da ein Krümel, so waren wir schon mal da und haben den Weg gefunden (super) oder auch nicht (da müssen wir nicht weitersuchen)
- Ergebnis ist eine Menge von Positionen
- Die Rekursion:
- Arbeite alle Optionen ab
- Erstmal Pause...
- Lasse den Thread etwas schlafen, damit man das Herumirren im Labyrinth verfolgen kann.
- Hänsel möchte wissen ob wir schon da sind?
- Wenn der Start das Ziel ist haben wir die Lösung gefunden
- wir legen eine neue Liste an
- falls nicht rufen wir die Methode suche() rekursiv auf.
- Verwende die Option als Start
- Verwende das ursprüngliche Ziel
- Wir hängen die aktuelle Position als Lösung ein und
- und geben sie zurück
- Ende der Methode
- Wenn der Start das Ziel ist haben wir die Lösung gefunden
- Merke dir die
- erste Liste (Heureka!)
- die kürzeste Liste (Hänsel läuft nicht gerne)
- Nach dem Abarbeiten aller Optionen:
- Nimm Lösungsliste (der Weg)
- Hänge vorne die Option and um den Lösungsweg zu verlängern
- Gib die Liste mit der gewünschten Lösung zurück
- Gibt es keine Lösung ist die Liste leer
- Die Länge der Liste ist die Länge des Pfades
- 1730 views
Stufe 5: Suchen einer Lösung mit einem parallelisiertem Backtrack Algorithmus
Stufe 5: Suchen einer Lösung mit einem parallelisiertem Backtrack AlgorithmusKlasse BacktrackSucheParallel
Diese Klasse wird aus BacktrackSuche spezialiert. Sie nutzt die gesamte Infrastruktur. Sie überschreibt
- loesungFinden()
- main(String[] args): Sie müssen hier eine Instanz von BacktrackSucheParallel anlegen und anzeigen
Klasse Ariadne4Parallel
Sie müssen hier einen Konstruktor implementieren, da die Oberklasse einen besitzt.
Das parallele Suche wird in der überschriebenen Methode suchen(von, nach) implementiert.
UML

Musterlösung
Github Projekt scalingbits/dhbwjava
- Klasse Position.java
- Klasse Zelle.java
- Klasse Labyrinth.java
- Klasse Backtrack.java
- Klasse BacktrackIO.java
- Klasse BacktrackSuche.java
- Klasse BacktrackSucheParallel
- 1261 views
Feedback
Feedback
| Datum | Teiln. | 2021 Bewertung | 2022 Bewertung | Kommentar | |
|---|---|---|---|---|---|
| Block 1 | |||||
| Block 2 | 3,7 |
|
|||
| Block 3 | 20.4.2022 | 4/20 | 3,8 | 4,3 |
|
| Block 4 Generics |
29.4.2021 | 8/22 | 4,0 | 4,13 |
|
| Block 5 Collections |
2.5.2022 | 1/21 | 2,9 | 4,0 |
Mir hat gut gefallen
Ich würde das folgende anders machen...
|
| Block 6 Swing |
4/18 | 3,3 |
|
||
|
Block 7 |
10/18 | 4,1 |
|
||
| Block 8 Streams I Streams II |
5/19 2/19 |
3,8 4,0 |
|
||
| Block 9 Backtracking |
8/19 | 4,7 |
|
||
| Block 10 Multithreading I Multithreading II |
4/19 -
|
4.3 - |
|
- 904 views