Testing SLES clusters with SAP HANA Database
Testing SLES clusters with SAP HANA DatabaseThe following three tests should be done before a HANA DB cluster is taken into production.
The tests will use all configured components.
- 1405 views
Primary HANA servers becomes unavailable
Primary HANA servers becomes unavailableSimulated Failures
- Instance failures. The primary HANA instance is crashed or not anymore reachable through the network
- Availability zone failure.
Components getting tested
- EC2 stoneith agent
- HANA agent
- Overlay IP agent
- Optional: Route 53 agent if it is configured
Approach
- Have a correctly working HANA DB cluster
- Shutdown eth0 on the instance to isolate
- The cluster will shutdown the node
- The cluster will failover the HANA database
- The cluster will not restart the failed node
Intial Configuration
Check whether the overlay IP address gets hosted on the interface eth0 on the first node:
hana01:/var/log # ip address list eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9000 qdisc mq state UP group default qlen 1000
link/ether 02:ca:c9:ca:a6:52 brd ff:ff:ff:ff:ff:ff
inet 10.0.1.115/24 brd 10.0.1.255 scope global eth0
valid_lft forever preferred_lft forever
inet 192.168.10.21/32 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::ca:c9ff:feca:a652/64 scope link
valid_lft forever preferred_lft forever
Check the cluster status as super user with the command crm status:
hana01:/var/log # crm status
Stack: corosync
Current DC: hana02 (version 1.1.15-21.1-e174ec8) - partition with quorum
Last updated: Tue Sep 11 12:37:53 2018
Last change: Tue Sep 11 12:37:53 2018 by root via crm_attribute on hana012 nodes configured
6 resources configuredOnline: [ hana01 hana02 ]
Full list of resources:
res_AWS_STONITH (stonith:external/ec2): Started hana01
res_AWS_IP (ocf::heartbeat:aws-vpc-move-ip): Started hana01
Clone Set: cln_SAPHanaTopology_HDB_HDB00 [rsc_SAPHanaTopology_HDB_HDB00]
Started: [ hana01 hana02 ]
Master/Slave Set: msl_SAPHana_HDB_HDB00 [rsc_SAPHana_HDB_HDB00]
Masters: [ hana01 ]
Slaves: [ hana02 ]
The AWS console shows that both nodes are running:

Damage the Instance
There are two ways to "damage" an instance
Corrupt Kernel
Become super user on the master HANA node.
Issue the command:
echo 'b' > /proc/sysrq-trigger
Isolate Instance
Become super user on the master HANA node.
Issue the command:
$ ifdown eth0
The current session will now hang. The system will not be able to communicate with the network anymore.
SUSE has a recommendation to do the isolation with firewalls and IP tables.
Monitor Fail Over
Expect the following in a correct working cluster:
- The second node will fence the first node. This means it will force a shutdown through AWS CLI commands
- The first node will be stopped
- The second node will take over the Overlay IP address and it will host the Hana database.
The cluster will now switch the master node and the slave node.
Monitor progress from the healthy node!
The first node gets reported being offline:
hana02:/home/ec2-user # SAPHanaSR-showAttr
Global cib-time
--------------------------------
global Wed Sep 19 13:18:21 2018
Hosts clone_state lpa_hdb_lpt node_state op_mode remoteHost roles score site srmode sync_state version vhost
-----------------------------------------------------------------------------------------------------------------------------------------------------------
hana01 1537362888 offline logreplay hana02 WDF sync hana01
hana02 PROMOTED 1537363101 online logreplay hana01 4:S:master1:master:worker:master 100 ROT sync SOK 2.00.030.00.1522209842 hana02hana02:/home/ec2-user # crm_mon -1rfn
Stack: corosync
Current DC: hana02 (version 1.1.15-21.1-e174ec8) - partition with quorum
Last updated: Wed Sep 19 13:18:52 2018
Last change: Wed Sep 19 13:18:21 2018 by root via crm_attribute on hana022 nodes configured
6 resources configuredNode hana01: OFFLINE
Node hana02: online
rsc_SAPHana_HDB_HDB00 (ocf::suse:SAPHana): Slave
rsc_SAPHanaTopology_HDB_HDB00 (ocf::suse:SAPHanaTopology): Started
res_AWS_IP (ocf::heartbeat:aws-vpc-move-ip): StartedInactive resources:
res_AWS_STONITH (stonith:external/ec2): Stopped
Clone Set: cln_SAPHanaTopology_HDB_HDB00 [rsc_SAPHanaTopology_HDB_HDB00]
Started: [ hana02 ]
Stopped: [ hana01 ]
Master/Slave Set: msl_SAPHana_HDB_HDB00 [rsc_SAPHana_HDB_HDB00]
Slaves: [ hana02 ]
Stopped: [ hana01 ]Migration Summary:
* Node hana02:
res_AWS_STONITH: migration-threshold=5000 fail-count=1 last-failure='Wed Sep 19 13:18:00 2018'Failed Actions:
* res_AWS_STONITH_monitor_120000 on hana02 'unknown error' (1): call=-1, status=Timed Out, exitreason='none',
last-rc-change='Wed Sep 19 13:18:00 2018', queued=0ms, exec=0ms
The AWS console will now show that the second node has been fencing the first node. It gets shut down:

The second node will wait until the first node is shut down. The AWS console will look like:

The cluster will now promote the instance on the second node to be the primary instance:
hana02:/home/ec2-user # SAPHanaSR-showAttr
Global cib-time
--------------------------------
global Wed Sep 19 13:19:14 2018
Hosts clone_state lpa_hdb_lpt node_state op_mode remoteHost roles score site srmode sync_state version vhost
-----------------------------------------------------------------------------------------------------------------------------------------------------------
hana01 1537362888 offline logreplay hana02 WDF sync hana01
hana02 PROMOTED 1537363154 online logreplay hana01 4:P:master1:master:worker:master 100 ROT sync PRIM 2.00.030.00.1522209842 hana02
The cluster status will be the following:
hana02:/home/ec2-user # crm_mon -1rfn
Stack: corosync
Current DC: hana02 (version 1.1.15-21.1-e174ec8) - partition with quorum
Last updated: Wed Sep 19 13:19:16 2018
Last change: Wed Sep 19 13:19:14 2018 by root via crm_attribute on hana022 nodes configured
6 resources configuredNode hana01: OFFLINE
Node hana02: online
rsc_SAPHana_HDB_HDB00 (ocf::suse:SAPHana): Master
res_AWS_STONITH (stonith:external/ec2): Started
rsc_SAPHanaTopology_HDB_HDB00 (ocf::suse:SAPHanaTopology): Started
res_AWS_IP (ocf::heartbeat:aws-vpc-move-ip): StartedInactive resources:
Clone Set: cln_SAPHanaTopology_HDB_HDB00 [rsc_SAPHanaTopology_HDB_HDB00]
Started: [ hana02 ]
Stopped: [ hana01 ]
Master/Slave Set: msl_SAPHana_HDB_HDB00 [rsc_SAPHana_HDB_HDB00]
Masters: [ hana02 ]
Stopped: [ hana01 ]Migration Summary:
* Node hana02:
res_AWS_STONITH: migration-threshold=5000 fail-count=1 last-failure='Wed Sep 19 13:18:00 2018'Failed Actions:
* res_AWS_STONITH_monitor_120000 on hana02 'unknown error' (1): call=-1, status=Timed Out, exitreason='none',
last-rc-change='Wed Sep 19 13:18:00 2018', queued=0ms, exec=0ms
Check whether the overlay IP address gets hosted on the eth0 interface of the second node. Example:
hana02:/tmp # ip address list eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9000 qdisc mq state UP group default qlen 1000
link/ether 06:4f:41:53:ff:76 brd ff:ff:ff:ff:ff:ff
inet 10.0.2.129/24 brd 10.0.2.255 scope global eth0
valid_lft forever preferred_lft forever
inet 192.168.10.21/32 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::44f:41ff:fe53:ff76/64 scope link
valid_lft forever preferred_lft forever
Last step: Clean up the message on the second node:
hana02:/home/ec2-user # crm resource cleanup res_AWS_STONITH hana02
Cleaning up res_AWS_STONITH on hana02, removing fail-count-res_AWS_STONITH
Waiting for 1 replies from the CRMd. OK
hana02:/home/ec2-user # crm status
Stack: corosync
Current DC: hana02 (version 1.1.15-21.1-e174ec8) - partition with quorum
Last updated: Wed Sep 19 13:20:44 2018
Last change: Wed Sep 19 13:20:34 2018 by hacluster via crmd on hana022 nodes configured
6 resources configuredOnline: [ hana02 ]
OFFLINE: [ hana01 ]Full list of resources:
res_AWS_STONITH (stonith:external/ec2): Started hana02
res_AWS_IP (ocf::heartbeat:aws-vpc-move-ip): Started hana02
Clone Set: cln_SAPHanaTopology_HDB_HDB00 [rsc_SAPHanaTopology_HDB_HDB00]
Started: [ hana02 ]
Stopped: [ hana01 ]
Master/Slave Set: msl_SAPHana_HDB_HDB00 [rsc_SAPHana_HDB_HDB00]
Masters: [ hana02 ]
Stopped: [ hana01 ]
Recovering the Cluster
Restart your stopped node. See:
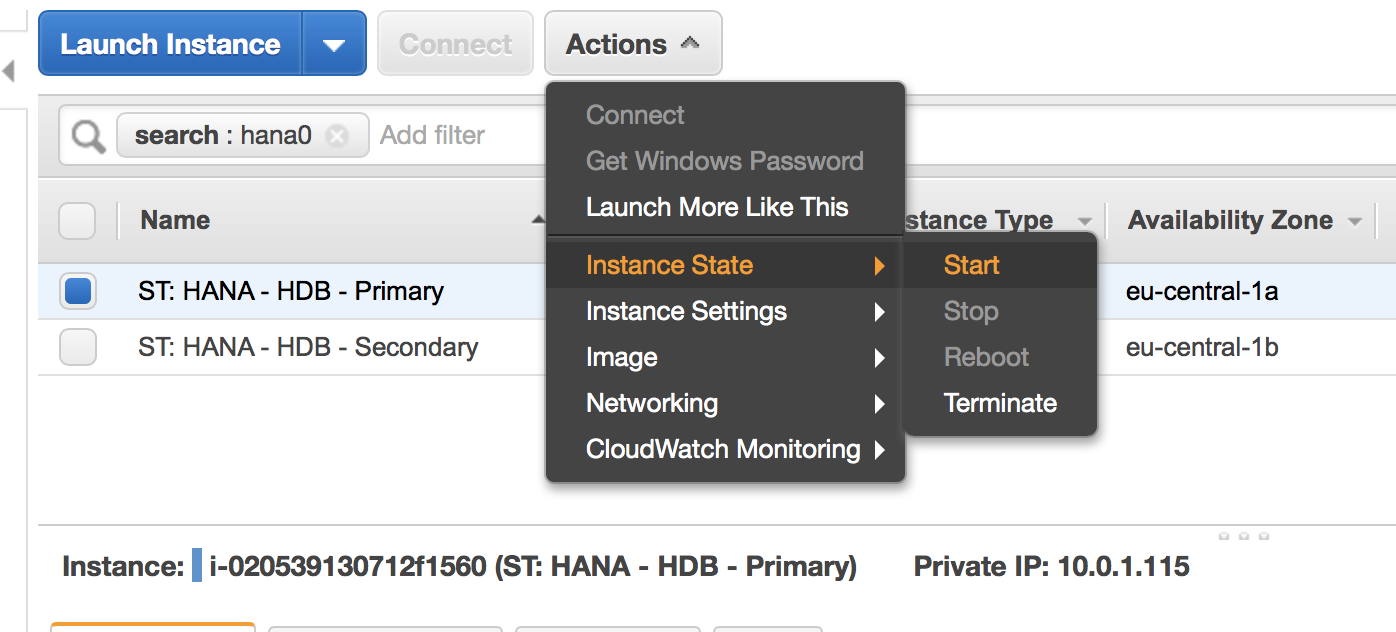
Check whether the cluster services get started
Check whether the first node becomes a replicating server
See:
hana02:/home/ec2-user # SAPHanaSR-showAttr;
Global cib-time
--------------------------------
global Wed Sep 19 13:57:41 2018
Hosts clone_state lpa_hdb_lpt node_state op_mode remoteHost roles score site srmode sync_state version vhost
-----------------------------------------------------------------------------------------------------------------------------------------------------------
hana01 DEMOTED 30 online logreplay hana02 4:S:master1:master:worker:master 100 WDF sync SOK 2.00.030.00.1522209842 hana01
hana02 PROMOTED 1537365461 online logreplay hana01 4:P:master1:master:worker:master 150 ROT sync PRIM 2.00.030.00.1522209842 hana02
- 2615 views
Secondary HANA server becomes unavailable
Secondary HANA server becomes unavailableSimulated Failures
- Instance failures. The secondary HANA instance is crashed or not anymore reachable through the network
- Availability zone failure.
Components getting tested
- EC2 stoneith agent
- HANA agent
- Overlay IP agent
- Optional: Route 53 agent if it is configured
Approach
- Have a correctly working HANA DB cluster
- Shutdown eth0 on the secondary server to isolate the server
- The cluster will shutdown the the secondary node
- The cluster will keep the primary node running without replication
- The cluster will not restart the failed node
Intial Configuration
Check whether the overlay IP address gets hosted on the interface eth0 on the first node:
hana01:/var/log # ip address list eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9000 qdisc mq state UP group default qlen 1000
link/ether 02:ca:c9:ca:a6:52 brd ff:ff:ff:ff:ff:ff
inet 10.0.1.115/24 brd 10.0.1.255 scope global eth0
valid_lft forever preferred_lft forever
inet 192.168.10.21/32 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::ca:c9ff:feca:a652/64 scope link
valid_lft forever preferred_lft forever
Check the cluster status as super user with the command crm status:
hana01:/var/log # crm status
Stack: corosync
Current DC: hana02 (version 1.1.15-21.1-e174ec8) - partition with quorum
Last updated: Tue Sep 11 12:37:53 2018
Last change: Tue Sep 11 12:37:53 2018 by root via crm_attribute on hana012 nodes configured
6 resources configuredOnline: [ hana01 hana02 ]
Full list of resources:
res_AWS_STONITH (stonith:external/ec2): Started hana01
res_AWS_IP (ocf::heartbeat:aws-vpc-move-ip): Started hana01
Clone Set: cln_SAPHanaTopology_HDB_HDB00 [rsc_SAPHanaTopology_HDB_HDB00]
Started: [ hana01 hana02 ]
Master/Slave Set: msl_SAPHana_HDB_HDB00 [rsc_SAPHana_HDB_HDB00]
Masters: [ hana01 ]
Slaves: [ hana02 ]
Status of HANA replication:
hana01:/home/ec2-user # SAPHanaSR-showAttrGlobal cib-time
--------------------------------
global Wed Sep 19 14:23:11 2018
Hosts clone_state lpa_hdb_lpt node_state op_mode remoteHost roles score site srmode sync_state version vhost
-----------------------------------------------------------------------------------------------------------------------------------------------------------
hana01 PROMOTED 1537366980 online logreplay hana02 4:P:master1:master:worker:master 150 WDF sync PRIM 2.00.030.00.1522209842 hana01
hana02 DEMOTED 30 online logreplay hana01 4:S:master1:master:worker:master 100 ROT sync SOK 2.00.030.00.1522209842 hana02
The AWS console shows that both nodes are running:
Damage the Instance
There are two ways to "damage" an instance
Corrupt Kernel
Become super user on the secondary HANA node.
Issue the command:
echo 'b' > /proc/sysrq-trigger
Isolate secondary Instance
Become super user on the secondary HANA node.
Issue the command:
$ ifdown eth0
The current session will now hang. The system will not be able to communicate with the network anymore.
SUSE has a recommendation to do the isolation with firewalls and IP tables.
Monitor Fail Over
Expect the following in a correct working cluster:
-
The first node will fence the second node. This means it will force a shutdown through AWS CLI commands
-
The second node will be stopped
-
The first node will remain the master node of the HANA database.
-
There is no more replication!
Monitor progress from the master node!
The first node gets reported being offline:
hana01:/home/ec2-user # SAPHanaSR-showAttr
Global cib-time
--------------------------------
global Wed Sep 19 14:24:13 2018
Hosts clone_state lpa_hdb_lpt node_state op_mode remoteHost roles score site srmode sync_state version vhost
-----------------------------------------------------------------------------------------------------------------------------------------------------------
hana01 PROMOTED 1537367044 online logreplay hana02 4:P:master1:master:worker:master 150 WDF sync PRIM 2.00.030.00.1522209842 hana01
hana02 DEMOTED 30 offline logreplay hana01 4:S:master1:master:worker:master 100 ROT sync SOK 2.00.030.00.1522209842 hana02
The cluster will figure out that the secondary node is in an unclean state
hana01:/home/ec2-user # crm_mon -1rfn
Stack: corosync
Current DC: hana01 (version 1.1.15-21.1-e174ec8) - partition with quorum
Last updated: Wed Sep 19 14:24:26 2018
Last change: Wed Sep 19 14:24:13 2018 by root via crm_attribute on hana01
2 nodes configured
6 resources configuredNode hana01: online
rsc_SAPHana_HDB_HDB00 (ocf::suse:SAPHana): Master
res_AWS_STONITH (stonith:external/ec2): Started
rsc_SAPHanaTopology_HDB_HDB00 (ocf::suse:SAPHanaTopology): Started
res_AWS_IP (ocf::heartbeat:aws-vpc-move-ip): Started
Node hana02: UNCLEAN (offline)
res_AWS_STONITH (stonith:external/ec2): Started
rsc_SAPHanaTopology_HDB_HDB00 (ocf::suse:SAPHanaTopology): Started
rsc_SAPHana_HDB_HDB00 (ocf::suse:SAPHana): SlaveInactive resources:
Migration Summary:
* Node hana01:
The AWS console will now show that the master node has been fencing the secondary node node. It gets shut down:

The master node will wait until the secondary node is shut down. The AWS console will look like:

The cluster will now reconfigure it HANA configuration. The cluster knows that the node is offline and replication has been stopped:
hana01:/home/ec2-user # SAPHanaSR-showAttr
Global cib-time
--------------------------------
global Wed Sep 19 14:24:13 2018
Hosts clone_state lpa_hdb_lpt node_state op_mode remoteHost roles score site srmode sync_state version vhost
-----------------------------------------------------------------------------------------------------------------------------------------------------------
hana01 PROMOTED 1537367044 online logreplay hana02 4:P:master1:master:worker:master 150 WDF sync PRIM 2.00.030.00.1522209842 hana01
hana02 30 offline logreplay hana01 ROT sync hana02
The cluster status is the following:
hana01:/home/ec2-user # crm_mon -1rfn
Stack: corosync
Current DC: hana01 (version 1.1.15-21.1-e174ec8) - partition with quorum
Last updated: Wed Sep 19 14:27:05 2018
Last change: Wed Sep 19 14:24:13 2018 by root via crm_attribute on hana01
2 nodes configured
6 resources configuredNode hana01: online
rsc_SAPHana_HDB_HDB00 (ocf::suse:SAPHana): Master
res_AWS_STONITH (stonith:external/ec2): Started
rsc_SAPHanaTopology_HDB_HDB00 (ocf::suse:SAPHanaTopology): Started
res_AWS_IP (ocf::heartbeat:aws-vpc-move-ip): Started
Node hana02: OFFLINEInactive resources:
Clone Set: cln_SAPHanaTopology_HDB_HDB00 [rsc_SAPHanaTopology_HDB_HDB00]
Started: [ hana01 ]
Stopped: [ hana02 ]
Master/Slave Set: msl_SAPHana_HDB_HDB00 [rsc_SAPHana_HDB_HDB00]
Masters: [ hana01 ]
Stopped: [ hana02 ]Migration Summary:
* Node hana01:
res_AWS_STONITH: migration-threshold=5000 fail-count=1 last-failure='Wed Sep 19 14:26:17 2018'Failed Actions:
* res_AWS_STONITH_monitor_120000 on hana01 'unknown error' (1): call=-1, status=Timed Out, exitreason='none',
last-rc-change='Wed Sep 19 14:26:17 2018', queued=0ms, exec=0ms
Check whether the overlay IP address gets hosted on the eth0 interface of the master node. Example:
hana01:/home/ec2-user # ip address list eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9000 qdisc mq state UP group default qlen 1000
link/ether 02:ca:c9:ca:a6:52 brd ff:ff:ff:ff:ff:ff
inet 10.0.1.115/24 brd 10.0.1.255 scope global eth0
valid_lft forever preferred_lft forever
inet 192.168.10.21/32 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::ca:c9ff:feca:a652/64 scope link
valid_lft forever preferred_lft forever
Recovering the Cluster
-
Restart your stopped node.
-
Check whether the cluster services get started
-
Check whether the first node becomes a replicating server
See:
hana01:/home/ec2-user # SAPHanaSR-showAttr
Global cib-time
--------------------------------
global Wed Sep 19 14:59:15 2018
Hosts clone_state lpa_hdb_lpt node_state op_mode remoteHost roles score site srmode sync_state version vhost
-----------------------------------------------------------------------------------------------------------------------------------------------------------
hana01 PROMOTED 1537369155 online logreplay hana02 4:P:master1:master:worker:master 150 WDF sync PRIM 2.00.030.00.1522209842 hana01
hana02 DEMOTED 30 online logreplay hana01 4:S:master1:master:worker:master 100 ROT sync SOK 2.00.030.00.1522209842 hana02
- 2163 views
Takeover a HANA DB through killing the Database
Takeover a HANA DB through killing the DatabaseSimulated Failures
- Database failures. The database is not working as expected
Components getting tested
- HANA agent
- Overlay IP agent
- Optional: Route 53 agent if it is configured
Approach
- Have a correctly working HANA DB cluster
- Kill database
- The cluster will failover the database without fencing the node
Intial Configuration
Check whether the overlay IP address gets hosted on the interface eth0 on the first node:
hana01:/var/log # ip address list eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9000 qdisc mq state UP group default qlen 1000
link/ether 02:ca:c9:ca:a6:52 brd ff:ff:ff:ff:ff:ff
inet 10.0.1.115/24 brd 10.0.1.255 scope global eth0
valid_lft forever preferred_lft forever
inet 192.168.10.21/32 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::ca:c9ff:feca:a652/64 scope link
valid_lft forever preferred_lft forever
Check the cluster status as super user with the command crm status:
hana01:/var/log # crm status
Stack: corosync
Current DC: hana02 (version 1.1.15-21.1-e174ec8) - partition with quorum
Last updated: Tue Sep 11 12:37:53 2018
Last change: Tue Sep 11 12:37:53 2018 by root via crm_attribute on hana012 nodes configured
6 resources configuredOnline: [ hana01 hana02 ]
Full list of resources:
res_AWS_STONITH (stonith:external/ec2): Started hana01
res_AWS_IP (ocf::heartbeat:aws-vpc-move-ip): Started hana01
Clone Set: cln_SAPHanaTopology_HDB_HDB00 [rsc_SAPHanaTopology_HDB_HDB00]
Started: [ hana01 hana02 ]
Master/Slave Set: msl_SAPHana_HDB_HDB00 [rsc_SAPHana_HDB_HDB00]
Masters: [ hana01 ]
Slaves: [ hana02 ]
Kill Database
hana01 is the node with the leading HANA database.
The failover will only work if the re-syncing of the slave node is completed. Check this through the command . Example:
hana02:/tmp # SAPHanaSR-showAttr
Global cib-time
--------------------------------
global Tue Sep 11 09:11:16 2018
Hosts clone_state lpa_hdb_lpt node_state op_mode remoteHost roles score site srmode sync_state version vhost
-----------------------------------------------------------------------------------------------------------------------------------------------------------
hana01 PROMOTED 1536657075 online logreplay hana02 4:P:master1:master:worker:master 150 WDF sync PRIM 2.00.030.00.1522209842 hana01
hana02 DEMOTED 30 online logreplay hana01 4:S:master1:master:worker:master 100 ROT sync SOK 2.00.030.00.1522209842 hana02
The synchronisation state (colum sync_state) of the slave node has to be SOK.
Become HANA DB user and execute the following command:
hdbadm@hana01:/usr/sap/HDB/HDB00> HDB kill
killing HDB processes:
kill -9 462 /usr/sap/HDB/HDB00/hana01/trace/hdb.sapHDB_HDB00 -d -nw -f /usr/sap/HDB/HDB00/hana01/daemon.ini pf=/usr/sap/HDB/SYS/profile/HDB_HDB00_hana01
kill -9 599 hdbnameserver
kill -9 826 hdbcompileserver
kill -9 828 hdbpreprocessor
kill -9 1036 hdbindexserver -port 30003
kill -9 1038 hdbxsengine -port 30007
kill -9 1372 hdbwebdispatcher
kill orphan HDB processes:
kill -9 599 [hdbnameserver] <defunct>
kill -9 1036 [hdbindexserver] <defunct>
Monitoring Fail Over
The cluster will now switch the master node and the slave node. The failover will be completed when the HANA database on the first node has been synchronized as well
hana02:/tmp # SAPHanaSR-showAttr
Global cib-time
--------------------------------
global Tue Sep 11 09:20:38 2018
Hosts clone_state lpa_hdb_lpt node_state op_mode remoteHost roles score site srmode sync_state version vhost
---------------------------------------------------------------------------------------------------------------------------------------------------------------
hana01 DEMOTED 30 online logreplay hana02 4:S:master1:master:worker:master -INFINITY WDF sync SOK 2.00.030.00.1522209842 hana01
hana02 PROMOTED 1536657638 online logreplay hana01 4:P:master1:master:worker:master 150 ROT sync PRIM 2.00.030.00.1522209842 hana02
Check the cluster status as super user with the command cluster status. Example
hana02:/tmp # crm status
Stack: corosync
Current DC: hana02 (version 1.1.15-21.1-e174ec8) - partition with quorum
Last updated: Tue Sep 11 09:28:10 2018
Last change: Tue Sep 11 09:28:06 2018 by root via crm_attribute on hana022 nodes configured
6 resources configuredOnline: [ hana01 hana02 ]
Full list of resources:
res_AWS_STONITH (stonith:external/ec2): Started hana01
res_AWS_IP (ocf::heartbeat:aws-vpc-move-ip): Started hana02
Clone Set: cln_SAPHanaTopology_HDB_HDB00 [rsc_SAPHanaTopology_HDB_HDB00]
Started: [ hana01 hana02 ]
Master/Slave Set: msl_SAPHana_HDB_HDB00 [rsc_SAPHana_HDB_HDB00]
Masters: [ hana02 ]
Slaves: [ hana01 ]Failed Actions:
* rsc_SAPHana_HDB_HDB00_monitor_61000 on hana01 'not running' (7): call=273, status=complete, exitreason='none',
last-rc-change='Tue Sep 11 09:18:47 2018', queued=0ms, exec=1867ms
* res_AWS_IP_monitor_60000 on hana01 'not running' (7): call=264, status=complete, exitreason='none',
last-rc-change='Tue Sep 11 08:57:15 2018', queued=0ms, exec=0ms
All resources are started. The overlay IP addres is now hosted on the second node. Delete the failed actions with the command:
hana02:/tmp # crm resource cleanup rsc_SAPHana_HDB_HDB00
Cleaning up rsc_SAPHana_HDB_HDB00:0 on hana01, removing fail-count-rsc_SAPHana_HDB_HDB00
Cleaning up rsc_SAPHana_HDB_HDB00:0 on hana02, removing fail-count-rsc_SAPHana_HDB_HDB00
Waiting for 2 replies from the CRMd.. OK
hana02:/tmp # crm resource cleanup res_AWS_IP
Cleaning up res_AWS_IP on hana01, removing fail-count-res_AWS_IP
Cleaning up res_AWS_IP on hana02, removing fail-count-res_AWS_IP
Waiting for 2 replies from the CRMd.. OK
The crm status command will not show anymore the failures.
Check whether the overlay IP address gets hosted on the eth0 interface of the second node. Example:
hana02:/tmp # ip address list eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9000 qdisc mq state UP group default qlen 1000
link/ether 06:4f:41:53:ff:76 brd ff:ff:ff:ff:ff:ff
inet 10.0.2.129/24 brd 10.0.2.255 scope global eth0
valid_lft forever preferred_lft forever
inet 192.168.10.21/32 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::44f:41ff:fe53:ff76/64 scope link
valid_lft forever preferred_lft forever
- 2817 views