SUSE SLES for SAP
SUSE SLES for SAPProduct: SLES for SAP 12 (Product landing page)
Failover Services: HANA Scale Up databases and Netweaver central systems
Licensing: Bring your own SUSE subscription or use the AWS Marketplace SUSE Linux Enterprise Server for SAP Applications 12 SP3 offering.
Status: Full support starting with SLES for SAP 12 SP1
This product relies on the SAP HANA system replication. It will monitor the master and the slave node for health. The Linux Cluster will failover a service IP address to the previous slave node when needed. The fencing agents will then reboot the previouse master node.
See:
- SAP NetWeaver High Availability Cluster 7.40 for the AWS Cloud - Setup Guide
- SUSE Linux Enterprise Server for SAP Applications 12 SP3 for the AWS Cloud - Setup Guide
More Resources:
- Technical presentation SUSECon 2015: Fast SAP HANA Fail Over Architecture with a SUSE High Availability Cluster in the AWS Cloud
- 15 minutes video showing an automated failover
- SAP note: (1765442) Joined support SAP SUSE (SLES High Availability)
- SAP note: (2309342) SUSE Linux Enterprise High Availability Extension on AWS
- SAP note: (1763512) Supportdetails für SUSE Linux Enterprise High Availability
- SUSE Setup Guide:
- SLES 11 (no AWS support):Automate your SAP HANA System Replication Failover
- SLES for SAP 12 SP1(with AWS Support): SAP HANA SR Performance Optimized Scenario
- Agent sources (not inidvidually required when SLES for SAP is being used)
- Open source AWS fencing agent in github
- Open source AWS move ip agent in github
- AWS Quickstart to install SLES HAE with HANA DB
- 5822 views
Trouble Shooting the Configuration
Trouble Shooting the ConfigurationVerification and debugging of the aws-vpc-move-ip Cluster Agent
As root user run the following command using the same parameters as in your cluster configuration:
# OCF_RESKEY_address=OCF_RESKEY_routing_table= OCF_RESKEY_interface=eth0 OCF_RESKEY_profile=cluster OCF_ROOT=/usr/lib/ocf /usr/lib/ocf/resource.d/suse/aws-vpc-move-ip monitor
Stop the overlay IP Address to be hosted on a given Node
# OCF_RESKEY_address=<virtual_IPv4_address> OCF_RESKEY_routing_table=<AWS_route_table> OCF_RESKEY_interface=eth0 OCF_RESKEY_profile=cluster OCF_ROOT=/usr/lib/ocf /usr/lib/ocf/resource.d/suse/aws-vpc-move-ip stop
# OCF_RESKEY_address=<virtual_IPv4_address> OCF_RESKEY_routing_table=<AWS_route_table> OCF_RESKEY_interface=eth0 OCF_RESKEY_profile=cluster OCF_ROOT=/usr/lib/ocf/usr/lib/ocf/resource.d/suse/aws-vpc-move-ip start
Start the overlay IP Address to be hosted on a given Node
As root user run the following command using the same parameters as in your cluster configuration:
# OCF_RESKEY_address=<virtual_IPv4_address> OCF_RESKEY_routing_table=<AWS_route_table> OCF_RESKEY_interface=eth0 OCF_RESKEY_profile=<AWS-profile> /usr/lib/ocf/resource.d/suse/aws-vpc-move-ip start
Check DEBUG output for error messages and verify that the virtual IP address is active on the current node with the command ip a.
Testing the Stonith Agent
The Stonith agent will shutdown the other node if he thinks that this node isn't anymore reachable. The agent can be called manually as super user on a cluster node 1 to shut down cluster node 2. Use it with the same parameter as being used in the Stoneith agent configuration:
# stonith -t external/ec2 profile=<AWS-profile> port=<cluster-node2> tag=<aws_tag_containing_hostname> -T off <cluster-node2>
This command will shutdown cluster node 2. Check the errors reported during execution of the command if it's not going to work as planned.
Re-start cluster node 2 and test STONITH the other way around.
The parameter used here are:
- AWS-profile : The profile which will be used by the AWS CLI. Check the file ~/.aws/config for the matching one. Using the AWS CLI command aws configure list will provide the same information
- cluster-node2: The name or IP address of the other cluster node
- aws_tag_containing_hostname: The is the name of the tag of the EC2 instances for the two cluster nodes. We used the name pacemaker in this documentation
Checking Cluster Log Files
Check the file: /var/log/cluster/corosync.log
Useful Commands
As super user:
| crm_resource -C | Reset warnings showing up in the command crm status |
| crm configure edit | Configure all agents in vi |
| crm configure property maintenance-mode=true | Set Pace Maker in maintenance mode. This allows to reconfigure, start, stop, resync. SAP HANA |
| crm configure property maintenance-mode=false | Bring Pace Maker from maintenance mode back into controlling, production mode. Allow Pace Maker to explore the current configuration. This can take a few seconds. |
SAP HANA related commands (as <SAP>adm user)
| hdbcons -e hdbindexserver 'replication info' | Check whether HANA is replicating, detailed |
| hdbnsutil -sr_state | Check whether HANA is replicating. Show the master, slave relationship |
| SAPHanaSR-showAttr | Cluster tool which checks the current configuration. Run as super user |
- 2810 views
Bad Hair Days (with SLES for SAP)
Bad Hair Days (with SLES for SAP)Bugs I ran into:
Symptom: Virtual IP Address doesn't get hosted
Manual testing of virtual IP address agent (start option) creates the following output:
INFO: EC2: Moving IP address 192.168.10.22 to this host by adjusting routing table rtb-xxx INFO: monitor: check routing table (API call) DEBUG: executing command: /usr/bin/aws --profile cluster --output text ec2 describe-route-tables --route-table-ids rtb-xxx DEBUG: executing command: ping -W 1 -c 1 192.168.10.22 WARNING: IP 192.168.10.22 not locally reachable via ping on this system INFO: EC2: Adjusting routing table and locally configuring IP address DEBUG: executing command: /usr/bin/aws --profile cluster ec2 replace-route --route-table-id rtb-xxx --destination-cidr-block 192.168.10.22/32 --instance-id i-1234567890 DEBUG: executing command: ip addr delete 192.168.10.22/32 dev eth0 RTNETLINK answers: Cannot assign requested address WARNING: command failed, rc 2 INFO: monitor: check routing table (API call)
The host can't add the IP address to eth0
Problem: SUSE netconfig hasn't been disabled
Solution: Set CLOUD_NETCONFIG_MANAGE='no' in /etc/sysconfig/network/ifcfg-eth0
Symptom: Virtual IP Address gets removed after some minutes
corosyn logs show a line like:
rsc_ip_XXX_XXXX_start_0:17147:stderr [ An error occurred (UnauthorizedOperation) when calling the ReplaceRoute operation: You are not authorized to"Problem: The instance does not have the right to modifiy routing tables
Solution: The virtual IP address policy has a problem. It may be missing. It may have a typo. Another policy may disallow access to routing tables.
Symptom: Nodes fence each other
The log file shows lines like:
2018-10-11T11:14:06.597541-04:00 my-hostname pengine[1234]: error: Resource rsc_ip_ABC_DEF01 (ocf::aws-vpc-move-ip) is active on 2 nodes attempting recovery 2018-10-11T11:14:06.597766-04:00 my-hostname pengine[1234]: warning: See http://clusterlabs.org/wiki/FAQ#Resource_is_Too_Active for more information.
Problem: There is a bug is the aws-vpc-move-ip agent. The monitoring has a glitch. The cluster thinks that both sides host the IP address on eth0 and they fence each other.
Solution: Update the package in question. Contact SUSE if this doesn't work or...
Modify all aws-vpc-move-ip resources in your CIB by adding monapi=true to the parameters of each aws-vpc-move-ip resource.
Symptom: Nodes fence each other
Both nodes shut down. The corosync log looks like:
Jan 07 07:31:17 [4750] my-hostname corosync notice [TOTEM ] A processor failed, forming new configuration.
Jan 07 07:31:25 [4750] my-hostname corosync notice [TOTEM ] A new membership (w.x.y.z:52) was formed. Members left: 2
Jan 07 07:31:25 [4750] my-hostname corosync notice [TOTEM ] Failed to receive the leave message. failed: 2
Problem: The corosync token didn't arrive for 6 times within 5 seconds. Check whether the communication in between the two servers works as intented or...
Solution: Increase the following corosync parameter:
- token: from 5000 to 30000
- consensus: from 7500 to 32000
- token_retransmits_before_loss_const: from 6 to 10
Decrease these parameters later on as long as the cluster runs stable. These changes have the following impact:
- The cluster will give up on coroysnc communication after (token) 30 seconds
- The time out for an individual token gets increased to token/retransmit : 30000ms/10 = 3s
- The cluster will attempt (token_retransmits_before_loss_const) 10 times to reestablish communication instead of 6 times
- The consensus parameter has to be larger than the token parameter
This configuration will increase the time for a cluster to recognize the communication failure and take over!
Symptom: Virtual IP Address gets removed after some minutes
corosync logs show a line like:
rsc_ip_XXX_XXXX_start_0:17147:stderr [ An error occurred (UnauthorizedOperation) when calling the ReplaceRoute operation: You are not authorized to"Problem: The instance does not have the right to modifiy routing tables
Solution: The virtual IP address policy has a problem. It may be missing. It may have a typo. Another policy may disallow access to routing tables.
Symptom: Both nodes shut down after a while
The log file shows lines like:
2018-10-12T08:33:10.477900-04:00 xxx stonith-ng[2199]: warning: fence_legacy[32274] stderr: [ An error occurred (UnauthorizedOperation) when calling the StopInstances operation: You are not authorized to perform this operation. Encoded authorization failure message: Q5Edo8F0xvippgHSKd11QKshu_Hhc3Z8Es_D9O4PYkrLrqY_o6ziaM0JkUrCwadpplJsJreOGxwCTEGd-f68XYc82Dz- HqBZmIrwacTFsYxa0fAQLOA6stHTc2OolBqD-X-HsKZ-bOMjAXs69RT04MRAgNVWJPXeAtq4PHZqN5nne8ocnsshgCt_5xkdjGnxp5VsfzE6o75OUtdHKtblq- 8MokX1ItkZKdohocthhQdQyhGlG8HT1loxdDSuG50LE-kHwGo1slNnZOa-Rw3rPKi0tNzpPvDvlMR3_OXwyC
2018-10-12T08:33:10.478589-04:00 xxx stonith-ng[2199]: error: Operation 'poweroff' [32274] (call 56 from crmd.2205) for host 'haawnulsmqaci' with device 'res_AWS_STONITH' returned: -62 (Timer expired)
2018-10-12T08:33:10.478793-04:00 xxx stonith-ng[2199]: warning: res_AWS_STONITH:32274 [ Performing: stonith -t external/ec2 -T off xxx ]
2018-10-12T08:33:10.478978-04:00 xxx stonith-ng[2199]: error: Operation poweroff of haawnulsmqaci by awnulsmqaci for crmd.2205@awnulsmqaci.98fa9afe: Timer expired
2018-10-12T08:33:10.479151-04:00 xxx crmd[2205]: notice: Stonith operation 56/53:87:0:c76c1861-5fd3-4132-a36c-8f22794a6f1b: Timer expired (-62)
2018-10-12T08:33:10.479340-04:00 xx crmd[2205]: notice: Stonith operation 56 for haawnulsmqaci failed (Timer expired): aborting transition.
Problem: A node can't shut down the other since the stonith policies are missing or not being configured appropriately
Solution: Add the stonith policy as indicated in the installation manual. Make sure that the policy is using the appropriate AWS instance ids. Test them individually!
Symptom: Confusing messages after crm configure commands
Example:
host01:~ # crm configure property maintenance-mode=false WARNING: cib-bootstrap-options: unknown attribute 'have-watchdog' WARNING: cib-bootstrap-options: unknown attribute 'stonith-enabled' WARNING: cib-bootstrap-options: unknown attribute 'placement- strategy' WARNING: cib-bootstrap-options: unknown attribute 'maintenance- mode'
Problem: This is a bug in crmsh. See: https://github.com/ClusterLabs/crmsh/pull/386 . It shouldn't affect functionality.
Solution: Wait for fix
Symptom: Cluster loses quorum after on node leaves the cluster
Problem: A cluster starts but it breakes the quorum
The corosync-quorum-tools lists the following incorrect status:
# corosync-quorumtool
(...)
Votequorum information
----------------------
Expected votes: 2
Highest expected: 2
Total votes: 2
Quorum: 2 --> Quorum
Flags: Quorate
A correctly configured cluster will show the following output:
# corosync-quorumtool
(...)
Votequorum information
----------------------
Expected votes: 2
Highest expected: 2
Total votes: 2
Quorum: 1 --> Quorum
Flags: 2Node Quorate WaitForAll
Solution: Fix typo in corosync configuration.
One line is probably incorrect. It may look like
two_nodes: 1
Remove the plural s and change it to
two_node: 1
- 1409 views
Checklist for the Installation of SAP Central Systems with SLES HAE
Checklist for the Installation of SAP Central Systems with SLES HAEThis check list is supposed to help with the installation of SAP HAE for ASCS protection.
The various identifiers will be needed at different stages of the installation. This check list should be complete before the SAP and the SLES HAE installation begins.
Tip: Click on "Generate printer friendly layout" at the bottom of the page before you print this file.
| Item | Status/Value |
|---|---|
|
SLES subscription and update status
|
|
|
AWS User Privileges for the installing person
|
|
|
VPC
|
|
| Subnet id A for systems in first AZ | |
| Subnet id B for systems in second AZ | |
Routing table id for subnet A and B
|
|
|
Optional:
|
|
AWS Policies Creation
|
|
|
First cluster node (ASCS and ERS)
|
|
Second cluster node (ASCS and ERS)
|
|
PAS system
|
|
AAS system
|
|
DB system (is potentially node 1 of a database failover cluster)
|
|
|
Overlay IP address: service ASCS
|
|
Overlay IP address: service ERS
|
|
Optional: Overlay IP address DB server
|
|
|
Optional: Route 53 configuration
|
|
|
Creation of EFS filesytem
|
|
|
All instance have Internet access
|
- 1704 views
Open Source Agents being used by SLES-for-SAP
Open Source Agents being used by SLES-for-SAPSUSE is a dedicated Open Source provider. SUSE tends to uses agents being published Upstream in the ClusterLabs Open Source project.
The Open Source agents being published via SLES-for-SAP are the only ones with SUSE support. Customers have evergrowing requirements. SUSE and AWS work on improving the agents.
This page lists the ClusterLabs agents as well as experimental agents without support.
| Name | location in SLES file system | Github sources | as of Github commit | Comment | Shortcomings |
|---|---|---|---|---|---|
| STONITH agent | /usr/lib64/stonith/plugins/external/ec2 | ec2 | 34a217f on ~ Aug 6, 2018 |
Stops and monitors EC2 instances. This version is filtering the EC2 commands which has the following advantages
|
Cosmetic: The --text option in AWS CLI command is missing. This would lower the risk of configuration errors with the AWS profile SUSE Bug 1106700: - AWS: ec2 agent has fixes implemented upstream |
| Move Overlay IP | /usr/lib/ocf/resource.d/suse/aws-vpc-move-ip | aws-vpc-move-ip | 7ac4653Sept. 4, 2018 | Reassign an AWS Overlay IP address in a routing table |
Heads up: This agent is not compatible to the proprietary agent from SUSE. SUSE uses a parameter with the name address. The upstream version uses the parameter name ip. I haven't yet been able to make this agent work in a SUSE cluster :-( |
| Route 53 | /usr/lib/ocf/resource.d/heartbeat/aws-vpc-route53 | aws-vpc-route53.in | 7632a85 ~August 6, 2018 | Update a record in an AWS Route 53 hosted zone (DNS server) |
calls of ec2metadata will fail if the AWS user data contains strings like "local-ipv4". This can happen in specific AWS Quickstart implementations Bug 1106706 - AWS: Route 53 agent has fixes implemented upstream |
There is an ongoing discussion about updating the agents. Here are some experimental agents without any SUSE support.
| Name | location in SLES file system | Github sources | as of Github commit | Comment | Shortcomings |
|---|---|---|---|---|---|
| Move Overlay IP | /usr/lib/ocf/resource.d/suse/aws-vpc-move-ip | ...soon here... | . | Reassign an AWS Overlay IP address in a routing table | New monitoring doesn't work when a cluster node rejoins a cluster. Use the old monitoring mode by adding the parametermonapi="true" to the primitive. Monitoring function got updated. New mode works. No parameter needed |
| Route 53 | /usr/lib/ocf/resource.d/heartbeat/aws-vpc-route53 | aws-vpc-route53 | 319ba06 on 2 Jul, 2018 | Update a record in an AWS Route 53 hosted zone (DNS server) | calls of ec2metadata will fail if the AWS user data contains strings like "local-ipv4". This can happen in specific AWS Quickstart implementations. The implementation ofec2metadata has been replaced with a more specific implementation |
- 1243 views
SLES HAE Cluster Tests with Netweaver on AWS
SLES HAE Cluster Tests with Netweaver on AWSThis is an example of tests to be performed with a SLES HAE HANA cluster.
Anyone will want to execute these tests before going into production.
| No. | Topic | Expected behavior |
|---|---|---|
| 1.0 | Set a node on standby/offline Set a node on standby by means of Pacemaker Cluster Tools (“crm node standby”). |
The cluster stops all managed resources on the standby node (master resources will be migrated / slave resources will just stop) |
| 1.1 | Set <nodenameA> to standby. |
Time until all managed resources were stopped / migrated to the other node: XX sec |
| 1.2 | Set <nodenameB> to standby | Time until all managed resources were stopped / migrated to the other node: XX sec |
| 2.0 | Switch off cluster node A Power-off the EC2 instance (hard / instant stop of the VM). |
The cluster notices that a member node is down. The remaining node makes a STONITH attempt to verify that the lost member is really offline. If STONITH is confirmed the remaining node takes over all resources. |
| 2.1 | Failover time of ASCS / HANA primary | XXX sec. |
| 3 | Switch off cluster node B Power-off the EC2 instance (hard / instant stop of the VM). |
The cluster notices that a member node is down. The remaining node makes a STONITH attempt to verify that the lost member is really offline. If STONITH is confirmed the remaining node takes over all resources. |
| 3.1 | Failover time of ASCS / HANA primary | XXX sec. |
| 4 | un-plug network connection (Split Brain) The cluster communication over the network is down. |
Both nodes detect the split brain scenario and try to fence each other (using the AWS STONITH agent). One node shuts down – the other will take over all resources Failovertime: XXX sec |
| 5 |
Failure (crash) of ASCS instance
ps -ef | grep ASCS | awk ‘{print $2}’ | xargs kill -9
|
The cluster notices the problem and promotes the ERS instance to ASCS while keeping all locks from the ENQ replication table. ASCS Failover time: XXX sec |
| 6 |
Failure of ERS instance
ps –ef | grep ERS | awk ‘{print $2}’ | xargs kill -9
|
The cluster notices the problem and restarts the ERS instance.
Time until ERS got restarted on same node: XX sec |
| 7 | Failure of HANA primary |
Time until HANA DB is available again: XXX sec |
| 8 | Failure of corosync Kill corosync cluster deamon “kill -9 “ on one node. |
The node without corosync is fenced by the remaining node (since it appears down). The remaining node makes a STONITH attempt to verify that the lost member is really offline. If STONITH is confirmed the remaining node takes over all resources. Failover of all managed resources: xxx sec |
Keep logfiles of all relevant resources to prove functionality. For instance after ASCS failover keep a copy of /usr/<SID>/ASCS<nr>/work/dev_enqserver. This logfile should list that an ENQ replication table was found in memory and that all locks got copied into the new ENQ table. Customers may request to aquire ENQ locks before the failover test and then check the status of those locks after successful failover (please document with screenshots of SM12 on both nodes before and after failover).
Keep corosync / cluster log of all actions taken during failover tests.
Ask customer for additional failover tests / requirements / scenarios he would like to cover.
Have customer sign the protocol (!) acknowledging that all tested failover scenarios worked as expected.
Remind customer to regularly re-test all failover scenarios if SAP / OS / cluster configuration changed or patches were applied.
- 2144 views
Testing SLES clusters with SAP HANA Database
Testing SLES clusters with SAP HANA DatabaseThe following three tests should be done before a HANA DB cluster is taken into production.
The tests will use all configured components.
- 1405 views
Primary HANA servers becomes unavailable
Primary HANA servers becomes unavailableSimulated Failures
- Instance failures. The primary HANA instance is crashed or not anymore reachable through the network
- Availability zone failure.
Components getting tested
- EC2 stoneith agent
- HANA agent
- Overlay IP agent
- Optional: Route 53 agent if it is configured
Approach
- Have a correctly working HANA DB cluster
- Shutdown eth0 on the instance to isolate
- The cluster will shutdown the node
- The cluster will failover the HANA database
- The cluster will not restart the failed node
Intial Configuration
Check whether the overlay IP address gets hosted on the interface eth0 on the first node:
hana01:/var/log # ip address list eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9000 qdisc mq state UP group default qlen 1000
link/ether 02:ca:c9:ca:a6:52 brd ff:ff:ff:ff:ff:ff
inet 10.0.1.115/24 brd 10.0.1.255 scope global eth0
valid_lft forever preferred_lft forever
inet 192.168.10.21/32 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::ca:c9ff:feca:a652/64 scope link
valid_lft forever preferred_lft forever
Check the cluster status as super user with the command crm status:
hana01:/var/log # crm status
Stack: corosync
Current DC: hana02 (version 1.1.15-21.1-e174ec8) - partition with quorum
Last updated: Tue Sep 11 12:37:53 2018
Last change: Tue Sep 11 12:37:53 2018 by root via crm_attribute on hana012 nodes configured
6 resources configuredOnline: [ hana01 hana02 ]
Full list of resources:
res_AWS_STONITH (stonith:external/ec2): Started hana01
res_AWS_IP (ocf::heartbeat:aws-vpc-move-ip): Started hana01
Clone Set: cln_SAPHanaTopology_HDB_HDB00 [rsc_SAPHanaTopology_HDB_HDB00]
Started: [ hana01 hana02 ]
Master/Slave Set: msl_SAPHana_HDB_HDB00 [rsc_SAPHana_HDB_HDB00]
Masters: [ hana01 ]
Slaves: [ hana02 ]
The AWS console shows that both nodes are running:

Damage the Instance
There are two ways to "damage" an instance
Corrupt Kernel
Become super user on the master HANA node.
Issue the command:
echo 'b' > /proc/sysrq-trigger
Isolate Instance
Become super user on the master HANA node.
Issue the command:
$ ifdown eth0
The current session will now hang. The system will not be able to communicate with the network anymore.
SUSE has a recommendation to do the isolation with firewalls and IP tables.
Monitor Fail Over
Expect the following in a correct working cluster:
- The second node will fence the first node. This means it will force a shutdown through AWS CLI commands
- The first node will be stopped
- The second node will take over the Overlay IP address and it will host the Hana database.
The cluster will now switch the master node and the slave node.
Monitor progress from the healthy node!
The first node gets reported being offline:
hana02:/home/ec2-user # SAPHanaSR-showAttr
Global cib-time
--------------------------------
global Wed Sep 19 13:18:21 2018
Hosts clone_state lpa_hdb_lpt node_state op_mode remoteHost roles score site srmode sync_state version vhost
-----------------------------------------------------------------------------------------------------------------------------------------------------------
hana01 1537362888 offline logreplay hana02 WDF sync hana01
hana02 PROMOTED 1537363101 online logreplay hana01 4:S:master1:master:worker:master 100 ROT sync SOK 2.00.030.00.1522209842 hana02hana02:/home/ec2-user # crm_mon -1rfn
Stack: corosync
Current DC: hana02 (version 1.1.15-21.1-e174ec8) - partition with quorum
Last updated: Wed Sep 19 13:18:52 2018
Last change: Wed Sep 19 13:18:21 2018 by root via crm_attribute on hana022 nodes configured
6 resources configuredNode hana01: OFFLINE
Node hana02: online
rsc_SAPHana_HDB_HDB00 (ocf::suse:SAPHana): Slave
rsc_SAPHanaTopology_HDB_HDB00 (ocf::suse:SAPHanaTopology): Started
res_AWS_IP (ocf::heartbeat:aws-vpc-move-ip): StartedInactive resources:
res_AWS_STONITH (stonith:external/ec2): Stopped
Clone Set: cln_SAPHanaTopology_HDB_HDB00 [rsc_SAPHanaTopology_HDB_HDB00]
Started: [ hana02 ]
Stopped: [ hana01 ]
Master/Slave Set: msl_SAPHana_HDB_HDB00 [rsc_SAPHana_HDB_HDB00]
Slaves: [ hana02 ]
Stopped: [ hana01 ]Migration Summary:
* Node hana02:
res_AWS_STONITH: migration-threshold=5000 fail-count=1 last-failure='Wed Sep 19 13:18:00 2018'Failed Actions:
* res_AWS_STONITH_monitor_120000 on hana02 'unknown error' (1): call=-1, status=Timed Out, exitreason='none',
last-rc-change='Wed Sep 19 13:18:00 2018', queued=0ms, exec=0ms
The AWS console will now show that the second node has been fencing the first node. It gets shut down:

The second node will wait until the first node is shut down. The AWS console will look like:

The cluster will now promote the instance on the second node to be the primary instance:
hana02:/home/ec2-user # SAPHanaSR-showAttr
Global cib-time
--------------------------------
global Wed Sep 19 13:19:14 2018
Hosts clone_state lpa_hdb_lpt node_state op_mode remoteHost roles score site srmode sync_state version vhost
-----------------------------------------------------------------------------------------------------------------------------------------------------------
hana01 1537362888 offline logreplay hana02 WDF sync hana01
hana02 PROMOTED 1537363154 online logreplay hana01 4:P:master1:master:worker:master 100 ROT sync PRIM 2.00.030.00.1522209842 hana02
The cluster status will be the following:
hana02:/home/ec2-user # crm_mon -1rfn
Stack: corosync
Current DC: hana02 (version 1.1.15-21.1-e174ec8) - partition with quorum
Last updated: Wed Sep 19 13:19:16 2018
Last change: Wed Sep 19 13:19:14 2018 by root via crm_attribute on hana022 nodes configured
6 resources configuredNode hana01: OFFLINE
Node hana02: online
rsc_SAPHana_HDB_HDB00 (ocf::suse:SAPHana): Master
res_AWS_STONITH (stonith:external/ec2): Started
rsc_SAPHanaTopology_HDB_HDB00 (ocf::suse:SAPHanaTopology): Started
res_AWS_IP (ocf::heartbeat:aws-vpc-move-ip): StartedInactive resources:
Clone Set: cln_SAPHanaTopology_HDB_HDB00 [rsc_SAPHanaTopology_HDB_HDB00]
Started: [ hana02 ]
Stopped: [ hana01 ]
Master/Slave Set: msl_SAPHana_HDB_HDB00 [rsc_SAPHana_HDB_HDB00]
Masters: [ hana02 ]
Stopped: [ hana01 ]Migration Summary:
* Node hana02:
res_AWS_STONITH: migration-threshold=5000 fail-count=1 last-failure='Wed Sep 19 13:18:00 2018'Failed Actions:
* res_AWS_STONITH_monitor_120000 on hana02 'unknown error' (1): call=-1, status=Timed Out, exitreason='none',
last-rc-change='Wed Sep 19 13:18:00 2018', queued=0ms, exec=0ms
Check whether the overlay IP address gets hosted on the eth0 interface of the second node. Example:
hana02:/tmp # ip address list eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9000 qdisc mq state UP group default qlen 1000
link/ether 06:4f:41:53:ff:76 brd ff:ff:ff:ff:ff:ff
inet 10.0.2.129/24 brd 10.0.2.255 scope global eth0
valid_lft forever preferred_lft forever
inet 192.168.10.21/32 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::44f:41ff:fe53:ff76/64 scope link
valid_lft forever preferred_lft forever
Last step: Clean up the message on the second node:
hana02:/home/ec2-user # crm resource cleanup res_AWS_STONITH hana02
Cleaning up res_AWS_STONITH on hana02, removing fail-count-res_AWS_STONITH
Waiting for 1 replies from the CRMd. OK
hana02:/home/ec2-user # crm status
Stack: corosync
Current DC: hana02 (version 1.1.15-21.1-e174ec8) - partition with quorum
Last updated: Wed Sep 19 13:20:44 2018
Last change: Wed Sep 19 13:20:34 2018 by hacluster via crmd on hana022 nodes configured
6 resources configuredOnline: [ hana02 ]
OFFLINE: [ hana01 ]Full list of resources:
res_AWS_STONITH (stonith:external/ec2): Started hana02
res_AWS_IP (ocf::heartbeat:aws-vpc-move-ip): Started hana02
Clone Set: cln_SAPHanaTopology_HDB_HDB00 [rsc_SAPHanaTopology_HDB_HDB00]
Started: [ hana02 ]
Stopped: [ hana01 ]
Master/Slave Set: msl_SAPHana_HDB_HDB00 [rsc_SAPHana_HDB_HDB00]
Masters: [ hana02 ]
Stopped: [ hana01 ]
Recovering the Cluster
Restart your stopped node. See:
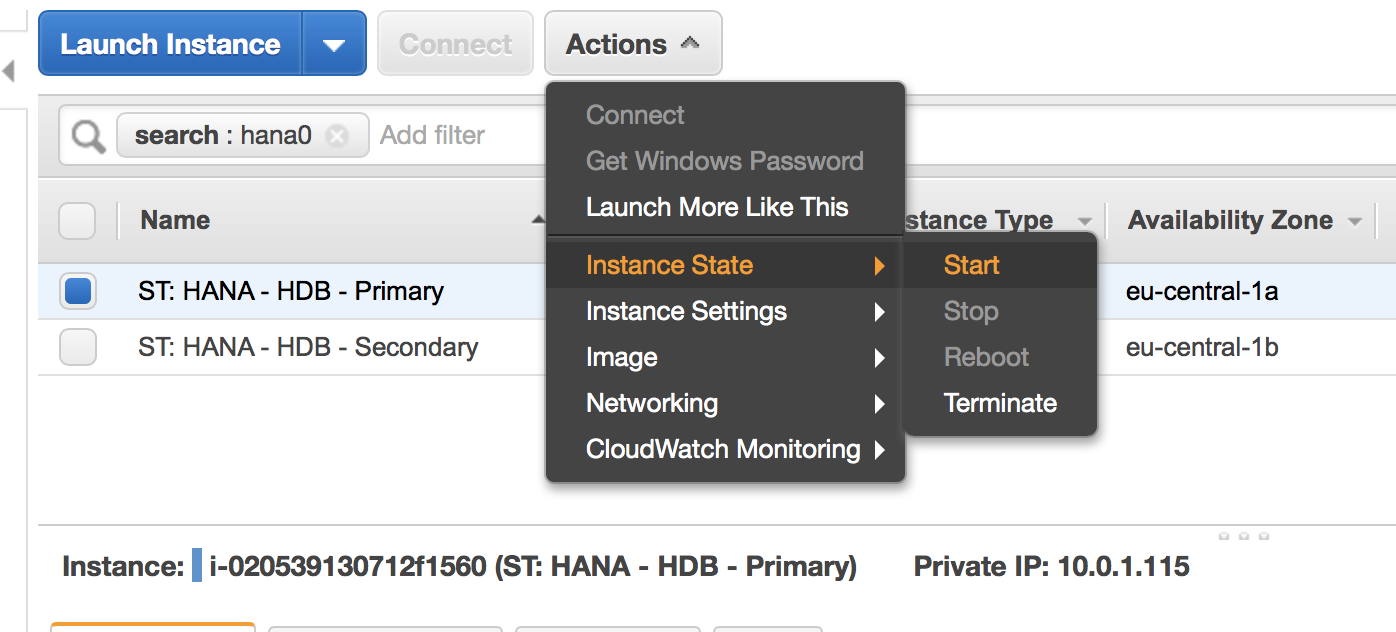
Check whether the cluster services get started
Check whether the first node becomes a replicating server
See:
hana02:/home/ec2-user # SAPHanaSR-showAttr;
Global cib-time
--------------------------------
global Wed Sep 19 13:57:41 2018
Hosts clone_state lpa_hdb_lpt node_state op_mode remoteHost roles score site srmode sync_state version vhost
-----------------------------------------------------------------------------------------------------------------------------------------------------------
hana01 DEMOTED 30 online logreplay hana02 4:S:master1:master:worker:master 100 WDF sync SOK 2.00.030.00.1522209842 hana01
hana02 PROMOTED 1537365461 online logreplay hana01 4:P:master1:master:worker:master 150 ROT sync PRIM 2.00.030.00.1522209842 hana02
- 2615 views
Secondary HANA server becomes unavailable
Secondary HANA server becomes unavailableSimulated Failures
- Instance failures. The secondary HANA instance is crashed or not anymore reachable through the network
- Availability zone failure.
Components getting tested
- EC2 stoneith agent
- HANA agent
- Overlay IP agent
- Optional: Route 53 agent if it is configured
Approach
- Have a correctly working HANA DB cluster
- Shutdown eth0 on the secondary server to isolate the server
- The cluster will shutdown the the secondary node
- The cluster will keep the primary node running without replication
- The cluster will not restart the failed node
Intial Configuration
Check whether the overlay IP address gets hosted on the interface eth0 on the first node:
hana01:/var/log # ip address list eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9000 qdisc mq state UP group default qlen 1000
link/ether 02:ca:c9:ca:a6:52 brd ff:ff:ff:ff:ff:ff
inet 10.0.1.115/24 brd 10.0.1.255 scope global eth0
valid_lft forever preferred_lft forever
inet 192.168.10.21/32 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::ca:c9ff:feca:a652/64 scope link
valid_lft forever preferred_lft forever
Check the cluster status as super user with the command crm status:
hana01:/var/log # crm status
Stack: corosync
Current DC: hana02 (version 1.1.15-21.1-e174ec8) - partition with quorum
Last updated: Tue Sep 11 12:37:53 2018
Last change: Tue Sep 11 12:37:53 2018 by root via crm_attribute on hana012 nodes configured
6 resources configuredOnline: [ hana01 hana02 ]
Full list of resources:
res_AWS_STONITH (stonith:external/ec2): Started hana01
res_AWS_IP (ocf::heartbeat:aws-vpc-move-ip): Started hana01
Clone Set: cln_SAPHanaTopology_HDB_HDB00 [rsc_SAPHanaTopology_HDB_HDB00]
Started: [ hana01 hana02 ]
Master/Slave Set: msl_SAPHana_HDB_HDB00 [rsc_SAPHana_HDB_HDB00]
Masters: [ hana01 ]
Slaves: [ hana02 ]
Status of HANA replication:
hana01:/home/ec2-user # SAPHanaSR-showAttrGlobal cib-time
--------------------------------
global Wed Sep 19 14:23:11 2018
Hosts clone_state lpa_hdb_lpt node_state op_mode remoteHost roles score site srmode sync_state version vhost
-----------------------------------------------------------------------------------------------------------------------------------------------------------
hana01 PROMOTED 1537366980 online logreplay hana02 4:P:master1:master:worker:master 150 WDF sync PRIM 2.00.030.00.1522209842 hana01
hana02 DEMOTED 30 online logreplay hana01 4:S:master1:master:worker:master 100 ROT sync SOK 2.00.030.00.1522209842 hana02
The AWS console shows that both nodes are running:
Damage the Instance
There are two ways to "damage" an instance
Corrupt Kernel
Become super user on the secondary HANA node.
Issue the command:
echo 'b' > /proc/sysrq-trigger
Isolate secondary Instance
Become super user on the secondary HANA node.
Issue the command:
$ ifdown eth0
The current session will now hang. The system will not be able to communicate with the network anymore.
SUSE has a recommendation to do the isolation with firewalls and IP tables.
Monitor Fail Over
Expect the following in a correct working cluster:
-
The first node will fence the second node. This means it will force a shutdown through AWS CLI commands
-
The second node will be stopped
-
The first node will remain the master node of the HANA database.
-
There is no more replication!
Monitor progress from the master node!
The first node gets reported being offline:
hana01:/home/ec2-user # SAPHanaSR-showAttr
Global cib-time
--------------------------------
global Wed Sep 19 14:24:13 2018
Hosts clone_state lpa_hdb_lpt node_state op_mode remoteHost roles score site srmode sync_state version vhost
-----------------------------------------------------------------------------------------------------------------------------------------------------------
hana01 PROMOTED 1537367044 online logreplay hana02 4:P:master1:master:worker:master 150 WDF sync PRIM 2.00.030.00.1522209842 hana01
hana02 DEMOTED 30 offline logreplay hana01 4:S:master1:master:worker:master 100 ROT sync SOK 2.00.030.00.1522209842 hana02
The cluster will figure out that the secondary node is in an unclean state
hana01:/home/ec2-user # crm_mon -1rfn
Stack: corosync
Current DC: hana01 (version 1.1.15-21.1-e174ec8) - partition with quorum
Last updated: Wed Sep 19 14:24:26 2018
Last change: Wed Sep 19 14:24:13 2018 by root via crm_attribute on hana01
2 nodes configured
6 resources configuredNode hana01: online
rsc_SAPHana_HDB_HDB00 (ocf::suse:SAPHana): Master
res_AWS_STONITH (stonith:external/ec2): Started
rsc_SAPHanaTopology_HDB_HDB00 (ocf::suse:SAPHanaTopology): Started
res_AWS_IP (ocf::heartbeat:aws-vpc-move-ip): Started
Node hana02: UNCLEAN (offline)
res_AWS_STONITH (stonith:external/ec2): Started
rsc_SAPHanaTopology_HDB_HDB00 (ocf::suse:SAPHanaTopology): Started
rsc_SAPHana_HDB_HDB00 (ocf::suse:SAPHana): SlaveInactive resources:
Migration Summary:
* Node hana01:
The AWS console will now show that the master node has been fencing the secondary node node. It gets shut down:

The master node will wait until the secondary node is shut down. The AWS console will look like:

The cluster will now reconfigure it HANA configuration. The cluster knows that the node is offline and replication has been stopped:
hana01:/home/ec2-user # SAPHanaSR-showAttr
Global cib-time
--------------------------------
global Wed Sep 19 14:24:13 2018
Hosts clone_state lpa_hdb_lpt node_state op_mode remoteHost roles score site srmode sync_state version vhost
-----------------------------------------------------------------------------------------------------------------------------------------------------------
hana01 PROMOTED 1537367044 online logreplay hana02 4:P:master1:master:worker:master 150 WDF sync PRIM 2.00.030.00.1522209842 hana01
hana02 30 offline logreplay hana01 ROT sync hana02
The cluster status is the following:
hana01:/home/ec2-user # crm_mon -1rfn
Stack: corosync
Current DC: hana01 (version 1.1.15-21.1-e174ec8) - partition with quorum
Last updated: Wed Sep 19 14:27:05 2018
Last change: Wed Sep 19 14:24:13 2018 by root via crm_attribute on hana01
2 nodes configured
6 resources configuredNode hana01: online
rsc_SAPHana_HDB_HDB00 (ocf::suse:SAPHana): Master
res_AWS_STONITH (stonith:external/ec2): Started
rsc_SAPHanaTopology_HDB_HDB00 (ocf::suse:SAPHanaTopology): Started
res_AWS_IP (ocf::heartbeat:aws-vpc-move-ip): Started
Node hana02: OFFLINEInactive resources:
Clone Set: cln_SAPHanaTopology_HDB_HDB00 [rsc_SAPHanaTopology_HDB_HDB00]
Started: [ hana01 ]
Stopped: [ hana02 ]
Master/Slave Set: msl_SAPHana_HDB_HDB00 [rsc_SAPHana_HDB_HDB00]
Masters: [ hana01 ]
Stopped: [ hana02 ]Migration Summary:
* Node hana01:
res_AWS_STONITH: migration-threshold=5000 fail-count=1 last-failure='Wed Sep 19 14:26:17 2018'Failed Actions:
* res_AWS_STONITH_monitor_120000 on hana01 'unknown error' (1): call=-1, status=Timed Out, exitreason='none',
last-rc-change='Wed Sep 19 14:26:17 2018', queued=0ms, exec=0ms
Check whether the overlay IP address gets hosted on the eth0 interface of the master node. Example:
hana01:/home/ec2-user # ip address list eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9000 qdisc mq state UP group default qlen 1000
link/ether 02:ca:c9:ca:a6:52 brd ff:ff:ff:ff:ff:ff
inet 10.0.1.115/24 brd 10.0.1.255 scope global eth0
valid_lft forever preferred_lft forever
inet 192.168.10.21/32 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::ca:c9ff:feca:a652/64 scope link
valid_lft forever preferred_lft forever
Recovering the Cluster
-
Restart your stopped node.
-
Check whether the cluster services get started
-
Check whether the first node becomes a replicating server
See:
hana01:/home/ec2-user # SAPHanaSR-showAttr
Global cib-time
--------------------------------
global Wed Sep 19 14:59:15 2018
Hosts clone_state lpa_hdb_lpt node_state op_mode remoteHost roles score site srmode sync_state version vhost
-----------------------------------------------------------------------------------------------------------------------------------------------------------
hana01 PROMOTED 1537369155 online logreplay hana02 4:P:master1:master:worker:master 150 WDF sync PRIM 2.00.030.00.1522209842 hana01
hana02 DEMOTED 30 online logreplay hana01 4:S:master1:master:worker:master 100 ROT sync SOK 2.00.030.00.1522209842 hana02
- 2163 views
Takeover a HANA DB through killing the Database
Takeover a HANA DB through killing the DatabaseSimulated Failures
- Database failures. The database is not working as expected
Components getting tested
- HANA agent
- Overlay IP agent
- Optional: Route 53 agent if it is configured
Approach
- Have a correctly working HANA DB cluster
- Kill database
- The cluster will failover the database without fencing the node
Intial Configuration
Check whether the overlay IP address gets hosted on the interface eth0 on the first node:
hana01:/var/log # ip address list eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9000 qdisc mq state UP group default qlen 1000
link/ether 02:ca:c9:ca:a6:52 brd ff:ff:ff:ff:ff:ff
inet 10.0.1.115/24 brd 10.0.1.255 scope global eth0
valid_lft forever preferred_lft forever
inet 192.168.10.21/32 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::ca:c9ff:feca:a652/64 scope link
valid_lft forever preferred_lft forever
Check the cluster status as super user with the command crm status:
hana01:/var/log # crm status
Stack: corosync
Current DC: hana02 (version 1.1.15-21.1-e174ec8) - partition with quorum
Last updated: Tue Sep 11 12:37:53 2018
Last change: Tue Sep 11 12:37:53 2018 by root via crm_attribute on hana012 nodes configured
6 resources configuredOnline: [ hana01 hana02 ]
Full list of resources:
res_AWS_STONITH (stonith:external/ec2): Started hana01
res_AWS_IP (ocf::heartbeat:aws-vpc-move-ip): Started hana01
Clone Set: cln_SAPHanaTopology_HDB_HDB00 [rsc_SAPHanaTopology_HDB_HDB00]
Started: [ hana01 hana02 ]
Master/Slave Set: msl_SAPHana_HDB_HDB00 [rsc_SAPHana_HDB_HDB00]
Masters: [ hana01 ]
Slaves: [ hana02 ]
Kill Database
hana01 is the node with the leading HANA database.
The failover will only work if the re-syncing of the slave node is completed. Check this through the command . Example:
hana02:/tmp # SAPHanaSR-showAttr
Global cib-time
--------------------------------
global Tue Sep 11 09:11:16 2018
Hosts clone_state lpa_hdb_lpt node_state op_mode remoteHost roles score site srmode sync_state version vhost
-----------------------------------------------------------------------------------------------------------------------------------------------------------
hana01 PROMOTED 1536657075 online logreplay hana02 4:P:master1:master:worker:master 150 WDF sync PRIM 2.00.030.00.1522209842 hana01
hana02 DEMOTED 30 online logreplay hana01 4:S:master1:master:worker:master 100 ROT sync SOK 2.00.030.00.1522209842 hana02
The synchronisation state (colum sync_state) of the slave node has to be SOK.
Become HANA DB user and execute the following command:
hdbadm@hana01:/usr/sap/HDB/HDB00> HDB kill
killing HDB processes:
kill -9 462 /usr/sap/HDB/HDB00/hana01/trace/hdb.sapHDB_HDB00 -d -nw -f /usr/sap/HDB/HDB00/hana01/daemon.ini pf=/usr/sap/HDB/SYS/profile/HDB_HDB00_hana01
kill -9 599 hdbnameserver
kill -9 826 hdbcompileserver
kill -9 828 hdbpreprocessor
kill -9 1036 hdbindexserver -port 30003
kill -9 1038 hdbxsengine -port 30007
kill -9 1372 hdbwebdispatcher
kill orphan HDB processes:
kill -9 599 [hdbnameserver] <defunct>
kill -9 1036 [hdbindexserver] <defunct>
Monitoring Fail Over
The cluster will now switch the master node and the slave node. The failover will be completed when the HANA database on the first node has been synchronized as well
hana02:/tmp # SAPHanaSR-showAttr
Global cib-time
--------------------------------
global Tue Sep 11 09:20:38 2018
Hosts clone_state lpa_hdb_lpt node_state op_mode remoteHost roles score site srmode sync_state version vhost
---------------------------------------------------------------------------------------------------------------------------------------------------------------
hana01 DEMOTED 30 online logreplay hana02 4:S:master1:master:worker:master -INFINITY WDF sync SOK 2.00.030.00.1522209842 hana01
hana02 PROMOTED 1536657638 online logreplay hana01 4:P:master1:master:worker:master 150 ROT sync PRIM 2.00.030.00.1522209842 hana02
Check the cluster status as super user with the command cluster status. Example
hana02:/tmp # crm status
Stack: corosync
Current DC: hana02 (version 1.1.15-21.1-e174ec8) - partition with quorum
Last updated: Tue Sep 11 09:28:10 2018
Last change: Tue Sep 11 09:28:06 2018 by root via crm_attribute on hana022 nodes configured
6 resources configuredOnline: [ hana01 hana02 ]
Full list of resources:
res_AWS_STONITH (stonith:external/ec2): Started hana01
res_AWS_IP (ocf::heartbeat:aws-vpc-move-ip): Started hana02
Clone Set: cln_SAPHanaTopology_HDB_HDB00 [rsc_SAPHanaTopology_HDB_HDB00]
Started: [ hana01 hana02 ]
Master/Slave Set: msl_SAPHana_HDB_HDB00 [rsc_SAPHana_HDB_HDB00]
Masters: [ hana02 ]
Slaves: [ hana01 ]Failed Actions:
* rsc_SAPHana_HDB_HDB00_monitor_61000 on hana01 'not running' (7): call=273, status=complete, exitreason='none',
last-rc-change='Tue Sep 11 09:18:47 2018', queued=0ms, exec=1867ms
* res_AWS_IP_monitor_60000 on hana01 'not running' (7): call=264, status=complete, exitreason='none',
last-rc-change='Tue Sep 11 08:57:15 2018', queued=0ms, exec=0ms
All resources are started. The overlay IP addres is now hosted on the second node. Delete the failed actions with the command:
hana02:/tmp # crm resource cleanup rsc_SAPHana_HDB_HDB00
Cleaning up rsc_SAPHana_HDB_HDB00:0 on hana01, removing fail-count-rsc_SAPHana_HDB_HDB00
Cleaning up rsc_SAPHana_HDB_HDB00:0 on hana02, removing fail-count-rsc_SAPHana_HDB_HDB00
Waiting for 2 replies from the CRMd.. OK
hana02:/tmp # crm resource cleanup res_AWS_IP
Cleaning up res_AWS_IP on hana01, removing fail-count-res_AWS_IP
Cleaning up res_AWS_IP on hana02, removing fail-count-res_AWS_IP
Waiting for 2 replies from the CRMd.. OK
The crm status command will not show anymore the failures.
Check whether the overlay IP address gets hosted on the eth0 interface of the second node. Example:
hana02:/tmp # ip address list eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9000 qdisc mq state UP group default qlen 1000
link/ether 06:4f:41:53:ff:76 brd ff:ff:ff:ff:ff:ff
inet 10.0.2.129/24 brd 10.0.2.255 scope global eth0
valid_lft forever preferred_lft forever
inet 192.168.10.21/32 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::44f:41ff:fe53:ff76/64 scope link
valid_lft forever preferred_lft forever
- 2817 views